Microservices require a robust authorization system that works consistently for all services. This article describes a solution we call fine-grained authorization and uses Quarkus, a modern Java framework, to implement Relationship-Based Access Control (ReBAC) in the manner of Google Zanzibar.
Coarse-grained versus fine-grained authorization
In brief, the difference between coarse-grained and fine-grained authorization is:
- Coarse-grained authorization requires only looking at the request to make an authorization decision.
- Fine-grained authorization requires looking at the request in the context of the system's state.
An example of coarse-grained authorization is authorizing a connection based on the claims of a JSON Web Token (JWT) or based on the identity of a client certificate from a static lookup table containing the identities that are allowed.
Coarse-grained operations can be performed by a proxy that lacks access to the state of the system. In microservices based on a service mesh, coarse-grained authorization is usually delegated to the mesh proxies running Envoy.
Conversely, fine-grained authorization must be performed with inside knowledge of the state of the system. Authorization is often performed by the service itself, because the authorization requires a business-related interpretation of the request.
For example, let's assume we have a checking account service at the context path /checkingaccounts/<number>/withdraw that responds to POST requests. Let's also assume that we perform coarse-grained authorization based on JWTs, configured to check that the user has a claim on the /checkingaccounts/<number> path. We want to make sure that a user can withdraw money only from one of their checking accounts. For that level of detail, we need fine-grained authorization.
In a microservices architecture in which microservices do not share data stores, only the checking account service knows which checking account belongs to which customer. As a result, the verification needs to happen within that code.
A simplistic implementation of fine-grained authorization would lead to multiple permissions systems, which are hard to manage and might lead to inconsistent rules applied to some users.
Fine-grained authorization in monoliths
Before we delve into the solution for fine-grained authorization for microservices, let's ask: How did we deal with this problem previously with monolithic applications?
In the case under consideration in this article, we were actually trying to strangle a monolith. So, we had the opportunity to examine the monolith's code.
The answer at a high level is simple: Permission data is stored together with business information in the database (Figure 1). The permission data portion of the database contains concepts such as roles, groups, and user memberships. The monolithic code can use the request data to query the database directly and make authorization decisions.

Authorization logic (aka the permission model) is scattered everywhere in the code and can become hard to maintain. But, in general, the central solution is very efficient. Sometimes a single query can retrieve data and, at the same time, filter out the rows that should not be returned based on the permission model.
Architectural approaches for fine-grained authorization with microservices
When we move to a microservice architecture, the business data portion of the database splits apart into multiple databases containing aggregate-related data. But what happens to the permission data?
At a high level, there are two architectural approaches: centralized and distributed.
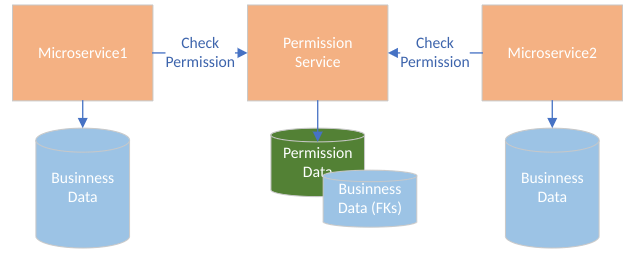
A centralized architecture appears similar to Figure 2. Various microservices call the permission service to check permissions for a given request. The permission service is the owner of the permission data. With this architecture, the check for permissions needs to happen before the actual business operation, therefore adding latency to the request. However, all of the permission-related data is stored in one place, guaranteeing consistency.

A distributed architecture appears similar to Figure 3. Each microservice carries the permission data that it needs and has similar performance characteristics as in the monolithic application, because business data and permission data are colocated.

Unfortunately, the distributed architecture offers fewer guarantees about the consistency of fine-grained authorization decisions. If microservices teams work independently, as they should, we cannot guarantee that they define the same conceptual permission model.
In other words, it's hard in the distributed permission architecture to guarantee consistency of authorization decisions across microservices. For example, does the "back office manager" role mean the same thing across all of the microservices? Does it even exist in all microservices?
Also, consider what it would take to build a user interface (UI) for permission management, where administrators can define roles and groups, in the distributed architecture, where permissions are scattered across multiple microservices. (Figure 3 depicts just three microservices, but in a real-world scenario, there would likely be many more.) It wouldn't be impossible, but it would involve a large integration exercise with the permission UI code that requires continuous refactoring as the various microservices evolve.
Overall, when we examined the problem closely, it was clear that the centralized approach was preferable.
Google's Zanzibar and ReBAC
While doing our research, we quickly discovered that we were not alone in trying to solve this problem. In fact, the major cloud providers have to solve a similar issue: They have hundreds of services (cloud APIs), each with potentially its own specific operations and permission over those operations. Meanwhile, the cloud providers have to give customers a way to define access control lists (ACLs) for their organizations.
Every cloud provider has variations on how they implement ACL management, but all of them do so with a single UI and API. We conclude from this uniform implementation—although we cannot confirm our conclusion as outsiders—that they use a centralized approach.
Google, in particular, disclosed how they implement permissions in the white paper they published about Zanzibar, their internal fine-grained authorization system.
Zanzibar introduces the concept of Relation-Based Access Control (ReBAC). With ReBAC, asking whether user A has permission B over object C translates to asking whether user A has a direct or indirect relationship of type B with object C.
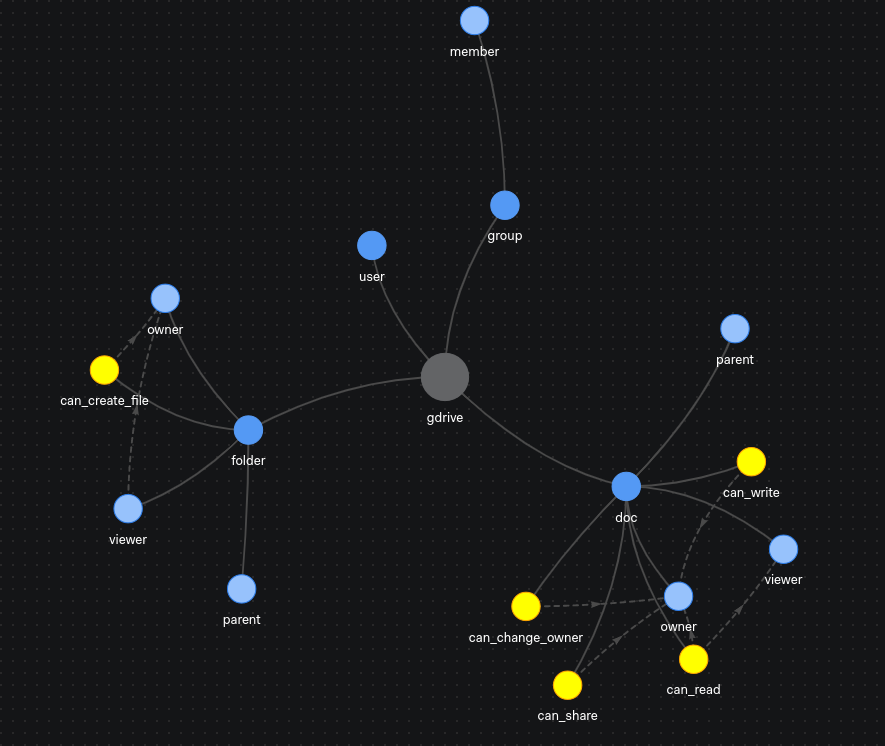
Let's take the Google Drive permission model (or at least what we can infer of it by observing it from the outside). A user can view a document if they are the owner or if the user has view permission of the parent folder. This model can be captured by the following text in OpenFGA's syntax:
type user
type folder
relations
define owner as self
define parent as self
define viewer as self or owner or viewer from parent
type doc
relations
define can_read as owner or viewer from parent
define owner as self
define parent as self
Notice that the define statements with the self keywords refer to direct relationships: For instance, define owner as self. The other statement format defines the rules about how to navigate the relationship graph. See the OpenFGA tutorial on modeling permissions for the complete example.
ReBAC permission models can be visualized as graphs. Figure 4 offers an example.
As in other instances where Google publishes information about what they are doing internally, initiatives were spawned to recreate the same capability as a product that anyone could use. There are now several initiatives implementing the Zanzibar/ReBAC style to fine-grained permission authorization. In our journey, we focused on two implementations: OpenFGA, as mentioned earlier, and Authzed SpiceDB.
We gravitated toward those two products because we needed something Quarkus-friendly and relatively mature. (The Zanzibar white paper was published in 2019, so in 2022 one cannot expect products to be older than a couple of years.) OpenFGA and SpiceDB seem to offer pretty similar features. We eventually chose SpiceDB for its enterprise support.
One of the things that distinguishes Zanzibar-style fine-grained authorization is that the permission service needs to possess the identifiers (as represented by database foreign keys) of all of the entities under permission and of all of the users. This allows the service to establish the relationships between users and entities and decide whether an action over an entity is permitted.
So the architecture of a centralized fine-grained permission model based on the Zanzibar approach appears similar to Figure 5. The permission service now has foreign keys to all of the entities under permission.
Challenges of implementing a Zanzibar fine-grained permission model
We faced two challenges when implementing Zanzibar-style fine-grained authorization: Dual writes and list operations.
Dual writes
As described in the previous section, the Zanzibar-style permission service needs to know about every entity under permission in the system. This oversight is typically accomplished by creating relations that refer to the foreign keys of the entities. (Any other unique identifier would also work.) As a result, when entities are created or deleted, the relations must be correspondingly added or removed from the Zanzibar permission database. This design introduces a dual write situation in which we need to make two writes within the same transaction: one to our microservice database and one to the Zanzibar permission database.
Zanzibar permission services typically expose their service via gRPC or REST. So distributed transactions are out of the question and would not be appropriate for a low-latency scenario anyway.
We decided on an approach inspired by this authzed blog, represented by Figure 6.
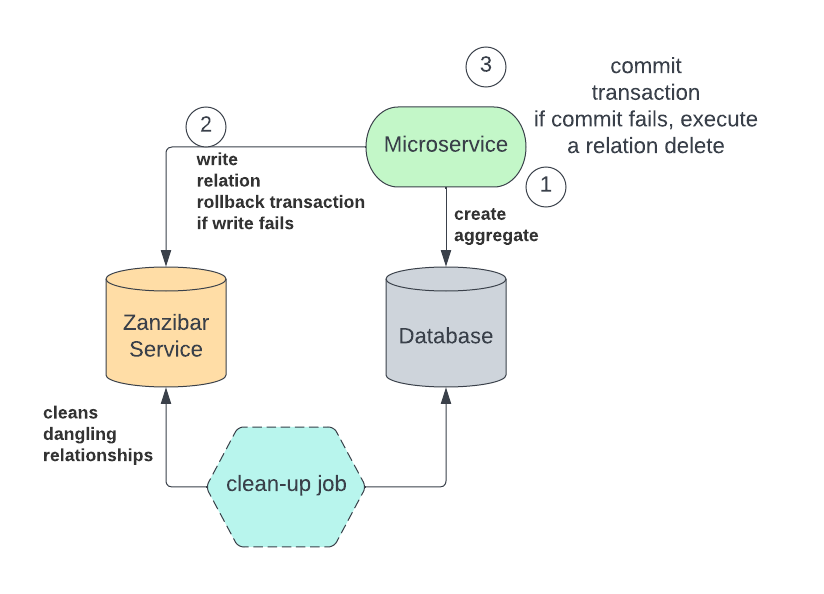
The sequence of events is:
- The microservice opens a transaction to the database in order to create a new entity there.
- The microservice tries to create a new relationship in the Zanzibar permission database. If the creation fails, the database transaction is rolled back.
- If the permission is successfully created, the microservice tries to commit the transaction to the database. If the transaction fails, the microservice tries to delete the previously created relationship in the permission database.
With this model, we run the risk of having a relation created in the Zanzibar permission database without creating the related entity in the microservice database. But the opposite never happens: There is never an entity that lacks a permission.
These dangling relationships are innocuous because the code never checks for them. To clean up the dangling relationships, we can optionally run a cleanup process that periodically deletes them by checking whether a corresponding entity exists in the microservice database.
In this approach, the write operation on SpiceDB must be completed after the write operation to the database, introducing latency.
List operations
Services commonly expose list operations that return a collection of entities. A monolithic application can create efficient queries that return only the entities that are visible to the requestor. With a Zanzibar permission service, we need to check whether the user has access to each returned entity. That could require a large number of calls to the permission service, introducing significant latency.
We addressed this issue by switching from paginated results for list operations to streams. With streams, the wait time for the user is the time it takes to return the first item as opposed to the entire page. So the Zanzibar permission service adds just the latency of making one call to the permission service.
Paginated and filtered results were also problematic because it was difficult to efficiently control the size of the returned page. For example, if a user asked for the first 20 objects and the database returned the first 20 objects, but then we had to discard some of them for permission reasons, we would have to make additional queries to the database to return more objects. Streams brilliantly solve this issue.
In this project, we were using Quarkus and reactive programming, so using streams for list operations was a natural choice. The conceptual code looks similar to the following (several implementation details are omitted):
Multi<Aggregate> result=aggregateList(params).select().when(i->permissionService.checkPermission(i))
Quarkus integration
Quarkus offers support for Zanzibar-style permission service via the following extensions:
- quarkus-zanzibar: A general extension that abstracts away the actual Zanzibar implementation and provides a set of methods including annotations to perform authorization checks.
- quarkus-openfga-client: Provides an implementation for OpenFGA.
- quarkus-authzed-client: Provides an implementation for Authzed and SpiceDB.
Both clients offer support for Dev Services, simplifying the inner loop for developers.
The annotations introduced by the quarkus-zanzibar extension can be used to guard access to methods. For example:
@FGAPathObject(param = "id", type = "thing")
@FGARelation("reader")
Thing getObject(@PathParam("id") String id) {
...
}
This code says that a user has permission to execute the getObject() method if they are in a relationship with an object of type thing and for which the identifier is taken from the request itself.
Unfortunately, these annotations currently work only for REST services, so we couldn't use them in our project because we use gRPC services. The maintainers of these extensions are considering how to support gRPC.
A centralized permission model works with Quarkus
In this article, we saw an approach to managing fine-grained authorization in a microservices ecosystem using a Zanzibar/ReBAC approach. The ecosystem of tools and products around this kind of solution is small, but is growing very rapidly, especially with support for major languages such as Java, Golang, C#, and Javascript.
Although setting up the infrastructure to support a centralized permission service and synchronize aggregates foreign keys to it requires some discipline, it seems to us that in the long run, it is well worth the investment.
Last updated: August 14, 2023