As Java developers, we have been using Java bean objects to store our data for nearly the entirety of the language's existence. It has always been considered a good practice to have private member variables along with public getters and setters for those private member variables. Furthermore, after two decades of Java EE and now Jakarta, it's become common to put all of our classes in four or five packages or folders that loosely map to model, view, and controller packages or folders. For good measure, you might add a package for data transfer objects and other classes.
With the explosion of complexity in the number and kinds of annotations required to make modern microservices work, this pattern of a few packages and hundreds of files in each folder is fundamentally broken when it runs up against the finite capabilities of humans. How many times have you scrolled for a long time looking for the four files that make up the business logic that you are trying to update?
There is a better way. I explore it in detail in 10 design tips for microservices developers with Quarkus, my on-demand session from Red Hat Summit 2022. In this article, we'll take a look at some of the high points.
Tip #1: Choose better package names
The first orthodoxy we have to challenge is that every Java project should use the same three to six package names. These names are no doubt well known to you in your projects, and are relics from an earlier and simpler time.
Let's use the idea of domain-driven development to align our package names with the capabilities we are looking to create. Rather than model, view, and controller packages, let's look to use things like User, ShoppingCart, or Checkout (and yes, those names should be capitalized) as top-level packages, each of which should package up the group of objects that take care of that named capability. This automatically gets us thinking about how to package up and create our classes and gives us a baseline to build on for our next five tips.
Tip #2: Domain-driven development
Once we have a package structure, what should we name the files that we place in those packages? I would suggest that files follow the pattern of APIUser.java, ModelUser.java, PerisistenUser.java, and ServiceUser.java.
Why are these names chosen? Let's consider them in alphabetical order.
- We have
API$Domain.java, which speaks to the outside world via JSON requests. - The next object uses
Model$Domain.javato store, marshall, and unmarshall these JSON requests. This class has the required JSON annotations that are typical of an object that is used to store a JSON request. Persistence$Domain.javais the class that stores the data that will be written to your database. Like the Model class earlier, this class will contain the annotations typical to JPA and database persistence. We separate out the annotations into two classes, giving our brain a break from crossing up the different needs of what needs to be stored in a database versus what is passed around in JSON. They are generally equal but not the same.- Finally, we have
Service$Domain.java, which takes care of writing the data to the database.
The front end is API$Domain.java gateways, and Service$Domain.java is the backend, taking care of writing information to our data store.
This covers naming conventions and the typical classes needed for each microservice that uses JSON and stores state in a database. Typically, all of these classes would be public. But let's explore a different idea in our next tip.
Tip #3: Death to public classes
By making the above classes public, you are allowing the compiler, Maven, and your enterprising and creative teammates to use them anywhere in your codebase. The traveling salesman problem is a metaphor for the possible number of connections and the resulting headache that befalls many projects. The spaghetti mess of interconnectedness available to your team with just a few classes is almost incalculable, but it also certainly exceeds your ability to test all of the possible permutations. With just 10 classes, you are left with 10! connections—more than 3 million paths that code execution could follow. That doesn't even address the explosion that happens with all of the public methods available to each class. With 20 classes, this number explodes to 2.4 x 1018, or more atoms than are in your body.
How can we solve this? Microservices development is supposed to make lives simpler for developers, but with this much available interconnectedness, things seem anything but simple.
This is where the empty modifier or protected keyword on our classes come in. These limit the use of objects and classes to either the local package (in the case of empty) or to those inherited in the tree (in the case of protected). This simple change enables the package to be considered as a super-object and lets the compiler and JVM create a firewall around the access to all classes in your package. With this strategy, the only way into your package, aka the super-object, is the JSON-speaking endpoint.
By combining the domain idea in Tip #2 and this idea in Tip #3, we have abstracted the kinds of development and annotations required to deliver the needed capabilities to a particular class. That allows us to concentrate on one type of coding in each of our four classes as outlined above. This is illustrated in Figure 1.
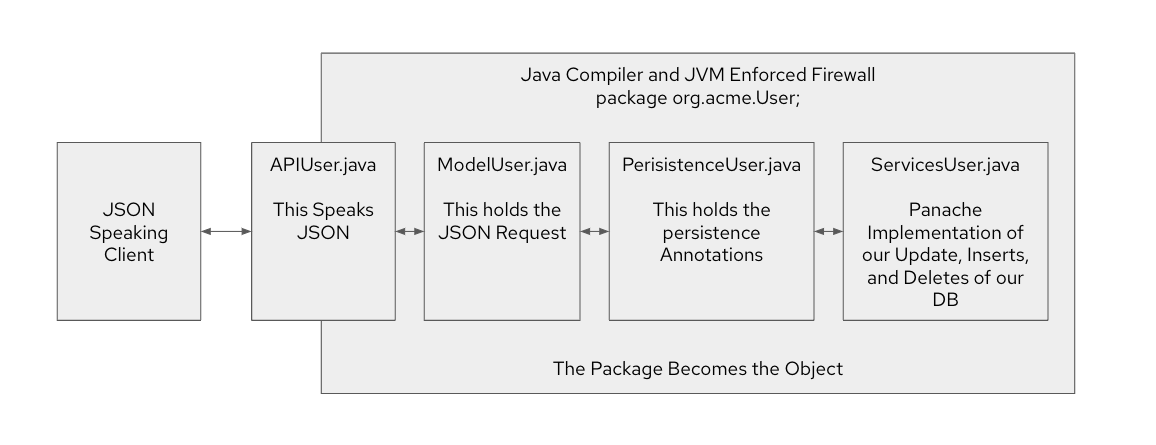
Turning away from public classes gives our brains a break, which is very much needed in the context of modern software development. Let's look at the next tip to see how we can work a bit more to give our brains even more of a break.
Tip #4: Type less, do more
Now that we have our class names figured out and have a strategy to limit the blast radius of our classes by using the protected or empty modifiers, what should we do about the typical use of private member variables and public getters and setters? Remember, we are limiting access to our classes—either to the same class, or by using inheritance with protected or empty modifiers on our classes. We can now extend this idea to our two data holding classes, Model$Domain.java and Perisistence$Domain.java.
Since these classes can only be used in our package, we can safely use the empty modifier on our member variables. Instead of private String firstName = null; with public getters and setters, we can use String firstName = null;. This lightens the cognitive load in two ways. Using fewer words lowers the cognitive load significantly around the member variables and the process of decoding what is happening. And with no getters and setters, less maintenance and fewer updates are required as your software evolves over time.
Tip #5: toString() that thing
Writing software is a lot like writing a great novel. The difference is that, rather than writing many paragraphs and then editing them until you have your masterpiece, in software we use logging to output the flow of our program, thus recreating our story over again until it is refined and brilliant.
I understand that a debugger is amazing, but the challenge for me has always been remembering all the state changes along the way. What was the state when I started? Did that variable change over time? I like to be able to scroll up and down an output log and review the story I am writing. You can't do that easily with debugger output over time. You just can't beat a good logging statement, and if you are going to have debugging statements, Java is brilliant in that it easily allows you to make a toString() method that outputs whatever your want. I love printing out the current state of the object, and the right format makes it pretty easy to see that state transition over time, and to uncover those simple logic bombs in transforming states that are so easy to do, but sometimes hard to track.
Tip #6: Considerations for Service$Domain.java
When writing a JSON-speaking object and the main gateway into the super-object in a package, I like to think about a few methods to help me develop and maintain it over time. In our current world of containers, having a health check URL easily accessible is always a nice thing. I will return a current build date and time and possibly a version number so I know what version of my software is running. When returning information from any number of gets, posts, deletes, and so on, I like to ensure I return good HTTP codes, including ones that might be custom to my application.
I also like to think about these methods returning textual strings with information on any error conditions and maybe even a success value as a true boolean, along with other error codes on failure. I also might provide a URL like /help that provides output about how I might invoke the endpoint. Remember, users of your software might not have access to the terminal and any error message returned there. They might not even have the documentation or know-how to invoke your service. Having some embedded documentation can help your future self out immensely.
Conclusion
Taking into consideration the needs of the human in the context of software development gives you many insights into how to make your microservices development more robust and simple. From lowering the blast radius of who can import and use your classes to limiting the number of words you need to type, you can make the creation of your super-objects just a little easier. By making smart use of the toString() method and some helper methods for your deployed services, you can assist your future self and others with the use of the APIs that you are deploying by making the software you deploy that much more robust.
For a deeper dive into these tips, along with more tips on microservices development, watch my on-demand session from Red Hat Summit 2022.
Last updated: February 11, 2024