Red Hat Data Grid is a distributed, cloud-based datastore offering very fast response times as an in-memory database. The latest version, Data Grid 8.3, features cross-site replication with more observability and two new types of SQL cache store for scaling applications with large datasets. This version also brings improved security, support for Helm charts, and a better command-line interface (CLI).
This article is an overview of new features and enhancements in this latest version of Red Hat Data Grid.
Cross-site replication with more observability
With the latest Data Grid release, you can track cross-site replication operations for each of the backup locations and their caches, including response times and the number of RELAY messages exchanged, as shown in Figure 1.
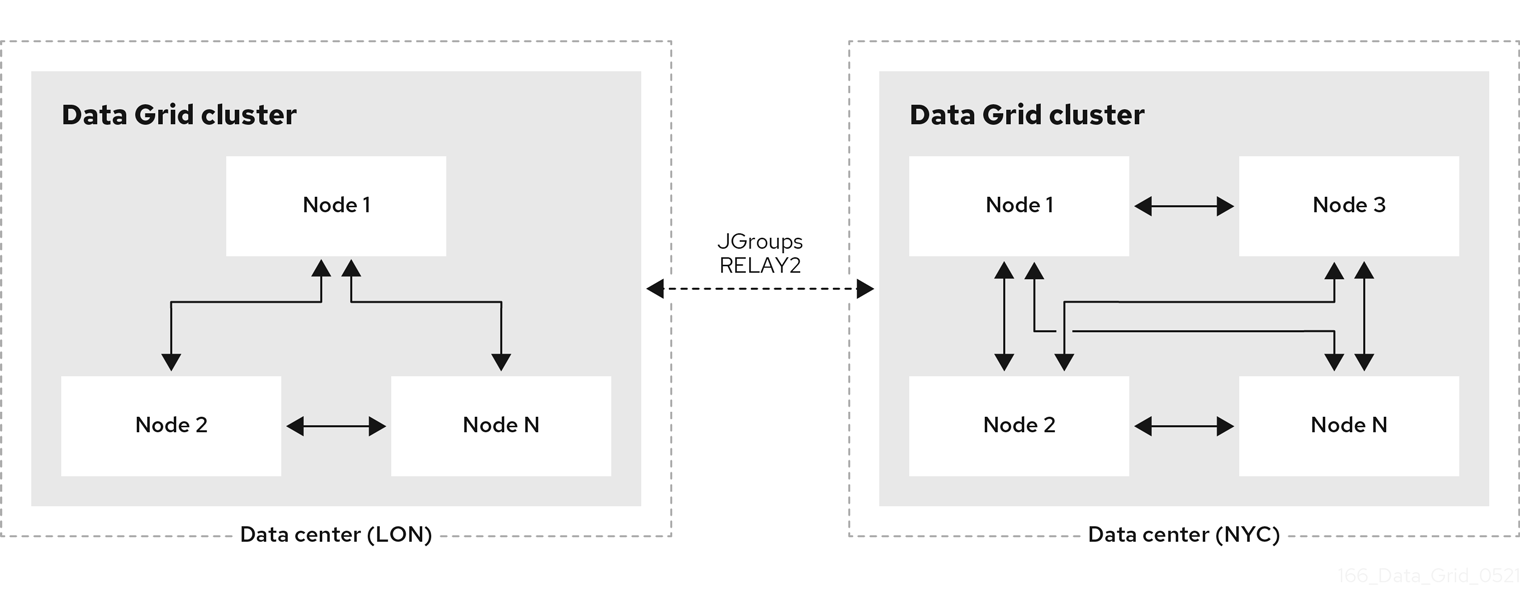
We have also enabled access to the data via the CLI, the REST API, and Java Management Extensions (JMX) to offer a better user experience to cluster operators. Cross-site replication is also more transparent and observable due to dedicated, operator-managed pods for routing cross-site replication requests.
Data Grid operators can also configure the number of relay nodes for cross-site replication. This flexibility enhances the cache's scalability and performance over multiple sites.
Finally, security is of paramount importance for a cross-site cluster, so we have enabled TLS security for router-based cross-site replication. (Scroll down for more about security enhancements in a later section.)
Scaling with SQL cache stores
What do you do if you have a lot of data in a database and want to load the data into the cache? Database schemas can be complex and users might want to define how that data is queried through operations such as SELECT, INSERT, and so on. Perhaps you would also like to support write-through and write-back operations. All of this makes for a complex scenario.
In this release, we have added two types of SQL cache store:
- Table cache store: Loads all data from a single table. Only the table name is required.
- Query cache store: Loads data based on SQL queries.
Useful things you can do with the new SQL cache stores include the following:
- Pre-load data from an existing database.
- Expose cache data with a user-defined schema.
- Allow read and write operations.
- Configure the cache store as read-only, and act as a cache loader.
- Configure the cache store to load values on startup.
- Use the cache store with composite keys and values through the protocol buffers (protobuf) schema.
- With the query cache store, use arbitrary select, select all, delete, delete all, and upsert operations.
To set up a cache store, you simply need to drop the database drivers into the server, which can be done with the Operator custom resource (CR) on Red Hat OpenShift. After that, users should be able to create SQL cache stores via YAML, JSON, or XML—also a new configuration feature. An example using Infinispan and the Quarkus Java framework is available on GitHub.
More security enhancements
Data Grid now provides full support for TLS version 1.3 with OpenSSL native acceleration. We have also increased the flexibility and convenience of security in Data Grid 8.3.
Multiple realms
You can combine multiple security realms into a single realm. When authenticating users, Data Grid Server checks each security realm in turn until it finds one that can perform the authentication.
The following example security realm includes an LDAP realm and a property realm, along with the distributed-realm element:
<security-realms>
<security-realm name="my-distributed-realm">
<ldap-realm>
<!-- LDAP realm configuration. -->
</ldap-realm>
<properties-realm>
<!-- Property realm configuration. -->
</properties-realm>
<distributed-realm/>
</security-realm>
</security-realms>Multiple endpoints
Users can now also configure multiple endpoints and define separate security realms for them. This enhancement enables more flexible and secure use.
The following example contains two different endpoint configurations. One endpoint binds to a public socket, uses an application security realm, and disables administrative features. Another endpoint binds to a private socket, uses a management security realm, and enables administrative features:
<endpoints>
<endpoint socket-binding="public"
security-realm="application"
admin="false">
<hotrod-connector/>
<rest-connector/>
</endpoint>
<endpoint socket-binding="private"
security-realm="management">
<hotrod-connector/>
<rest-connector/>
</endpoint>
</endpoints>PEM files
Users can now add PEM files directly to their Data Grid Server configuration and use them as trust stores and keystores in a TLS server identity.
Note: See the Data Grid Security Guide and Distributed security realms to learn more about new security features in Data Grid 8.3.
Deploy Data Grid with Helm charts
Developers who use Helm charts for application deployment can now use this convenient mechanism to install Data Grid. You can use charts to deploy Data Grid instances, configure clusters, add authentication and authorization, add network access via routes and node ports, enable load balancers, and more, using the Data Grid portal (Figure 2) or the CLI.
Note: Using Helm charts is intended for sites where the Data Grid Operator is not available and operators must configure, deploy, and manage the cluster manually.
CLI improvements
Data Grid 8.3 has a few updates for developers who prefer working on the command line. For one, you can enable and disable rebalancing of the cluster, track and extract more details about cross-site replication relay nodes, and manage cache availability. Additionally, if you use the general oc OpenShift command, you can now also install the Infinispan extension and use it with oc, as shown in Figure 3.

Usability improvements
We've made a few more improvements to increase the usability of Data Grid in this release:
- Data Grid 8.3 has full support for Java 17 for embedded and remote caches.
- You can automatically migrate any file-store configuration during the upgrade to Data Grid 8.3.
You can now delete entries with the Ickle programming language:
query.create("DELETE FROM books WHERE page_count > 500").executeStatement();- Hot Rod migration is simpler when upgrading clusters of server nodes between versions and handles configuration changes transparently.
Get started with Data Grid 8.3
Ready to dive in and try out Data Grid 8.3? These resources will get you started:
- Zip distributions are available through the Certified Service Provider (CSP) program.
- Container distributions and Operators are available in the Red Hat Container Catalog.
- Product documentation is available on the Red Hat customer portal, including a migration guide to help you migrate your existing Data Grid deployments to 8.0.
Visit the Red Hat Data Grid product page to learn more about this technology.
Last updated: June 4, 2024