Change data capture (CDC) is a powerful data processing tool widely used in the industry, and provided by the open source Debezium project. CDC notifies your application whenever changes are made to a data set so that you can react promptly. This tutorial demonstrates how to use Debezium to monitor a MySQL database. As the data in the database changes, the resulting event streams are reflected in Red Hat OpenShift Streams for Apache Kafka.
Debezium includes connectors for many types of data stores. In this tutorial, we will use the MySQL connector.
Red Hat OpenShift Service Registry
This demo uses Red Hat OpenShift Service Registry, a fully hosted and managed service that provides an API and schema registry for microservices. OpenShift Service Registry makes it easy for development teams to publish, discover, and reuse APIs and schemas.
The following services include OpenShift Service Registry at no additional charge:
- Red Hat OpenShift API Management
- Red Hat OpenShift Streams for Apache Kafka
Debezium schema serialization
Although Debezium makes it easy to capture database changes and record them in Kafka, one of the critical decisions you have to make is how you will serialize those change events in Kafka. Debezium allows you to select key and value converters to choose from different types of options. OpenShift Service Registry enables you to store externalized schema versions to minimize the payload that is propagated.
By default, Debezium's converter includes the record's JSON message schema in each record, making the records very verbose. Alternatively, you can serialize the record keys and values using the compact binary format standardized in Apache Avro. To use Apache Avro serialization, you must deploy a schema registry that manages Avro message schemas and their versions.
OpenShift Service Registry provides an Avro converter that you can specify in Debezium connector configurations. This converter maps Kafka Connect schemas to Avro schemas. The converter then uses the Avro schemas to serialize the record keys and values into Avro's format.
Prerequisites
Install the following tools to run the tasks in this tutorial:
-
The latest version of Docker or Podman. (See the Docker Engine installation documentation or the Podman installation documentation.)
-
kcat. -
jq(for JSON processing).
You also need access to the following:
-
A Red Hat Developer account. (As part of the developer program for OpenShift Streams for Apache Kafka, anyone with a Red Hat account can create a Kafka instance free of charge.)
-
A running OpenShift Streams cluster.
-
A running OpenShfit Service Registry instance.
Start the local services
The MySQL database and the Kafka Connect cluster run locally on your machine for this demo. We will use Docker Compose to start the required services, so there is no need to install anything beyond the prerequisites listed in the previous section.
To start the local services, follow these steps.
-
Clone this repository:
$ git clone https://github.com/hguerrero/debezium-examples.git -
Change to the following directory:
$ cd debezium-examples/debezium-openshift-registry-avro -
Open the
docker-compose.yamlfile and edit the Kafka-related properties to specify your cluster information. You need to know the name of your Kafka bootstrap server and the service account you will use to connect. The container image will then take the password from a local file calledcpass. Thus, your properties should look like:KAFKA_CONNECT_BOOTSTRAP_SERVERS: <your-boostrap-server>:<port> KAFKA_CONNECT_TLS: 'true' KAFKA_CONNECT_SASL_MECHANISM: plain KAFKA_CONNECT_SASL_USERNAME: <kafka-sa-client-id> KAFKA_CONNECT_SASL_PASSWORD_FILE: cpass -
Open the provided
cpassfile and replace the placeholder with your service account secret. -
Start the environment using one of these two commands:
podman-compose up -ddocker-compose up -dThe preceding command starts the following components:
- A single-node Kafka Connect cluster
- The MySQL database (ready for CDC)
Configure Apicurio converters
The open source Apicurio Registry project is the upstream community that furnishes the technology used by OpenShift Service Registry. Apicurio Registry provides Kafka Connect converters for Apache Avro and JSON Schema. When configuring Avro at the Debezium Connector, you have to specify the converter and schema registry as a part of the connector's configuration. The connector configuration customizes the connector, explicitly setting its serializers and deserializers to use Avro and specifying the location of the Apicurio registry.
The container image used in this environment includes all the required libraries to gain access to the Debezium connectors and Apicurio Registry converters.
The following snippet contains the lines required in the connector configuration to set the key and value converters and their respective registry configuration. Replace the placeholders in the snippet with the information from your OpenShift services:
"key.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"key.converter.apicurio.registry.converter.serializer": "io.apicurio.registry.serde.avro.AvroKafkaSerializer",
"key.converter.apicurio.registry.url": "<your-service-registry-core-api-url>",
"key.converter.apicurio.auth.service.url": "https://identity.api.openshift.com/auth",
"key.converter.apicurio.auth.realm": "rhoas",
"key.converter.apicurio.auth.client.id": "<registry-sa-client-id>",
"key.converter.apicurio.auth.client.secret": "<registry-sa-client-id>",
"key.converter.apicurio.registry.as-confluent": "true",
"key.converter.apicurio.registry.auto-register": "true",
"value.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"value.converter.apicurio.registry.converter.serializer": "io.apicurio.registry.serde.avro.AvroKafkaSerializer",
"value.converter.apicurio.registry.url": "<your-service-registry-core-api-url>",
"value.converter.apicurio.auth.service.url": "https://identity.api.openshift.com/auth",
"value.converter.apicurio.auth.realm": "rhoas",
"value.converter.apicurio.auth.client.id": "<registry-sa-client-id>",
"value.converter.apicurio.auth.client.secret": "<registry-sa-client-id>",
"value.converter.apicurio.registry.as-confluent": "true",
"value.converter.apicurio.registry.auto-register": "true"
The compatibility mode allows you to use other providers' tooling to deserialize and reuse the schemas in the Apicurio service registry.
This configuration also includes the information required for the serializer to authenticate with the service registry using a service account.
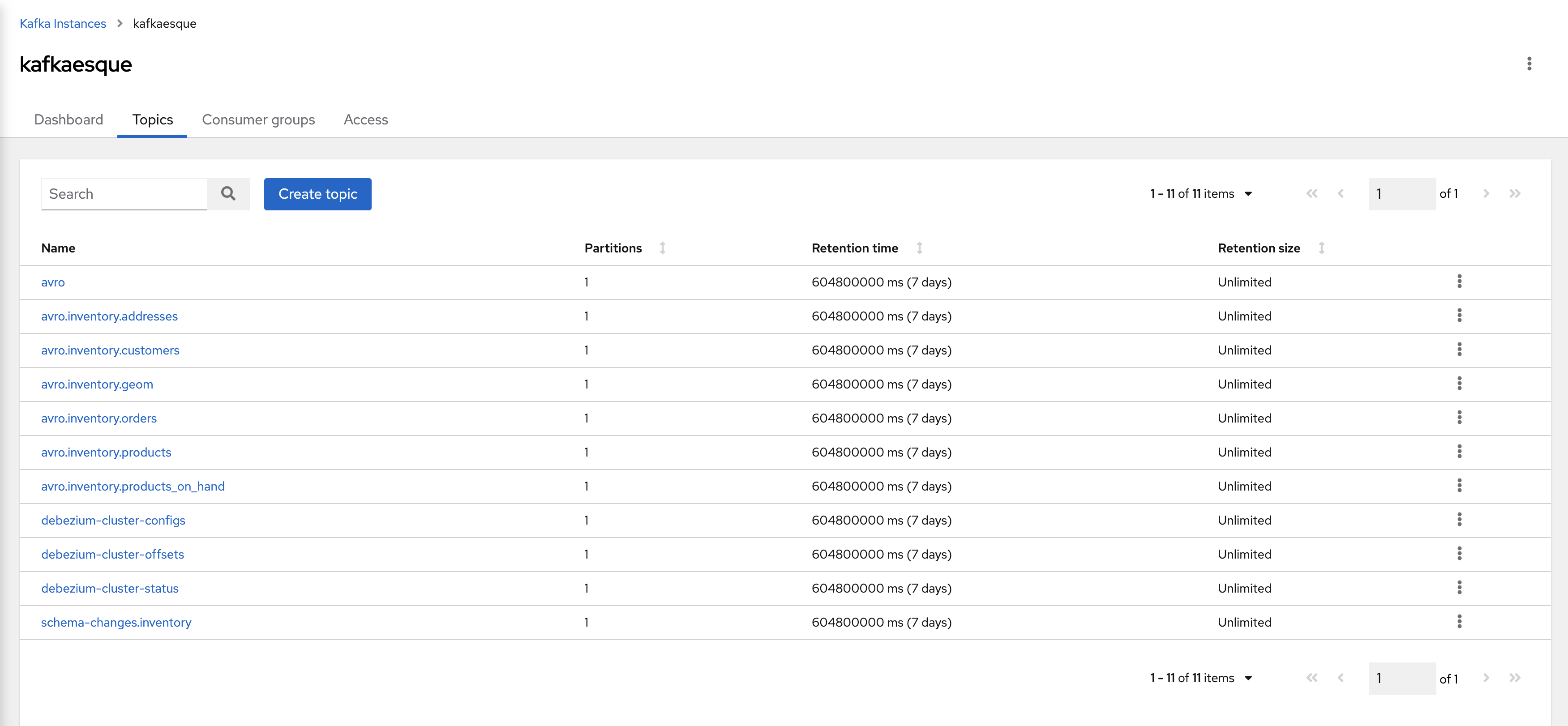
Create the topics in OpenShift Streams for Apache Kafka
You need to manually create the required topics Debezium will use in your Kafka cluster. The user interface (UI) in OpenShift Streams for Apache Kafka makes configuration easier and eliminates some sources of errors. The recommended parameters for each topic are:
- Partitions:
1 - Retention time:
604800000 ms (7 days) - Retention size:
Unlimited
The topics whose names start with debezium-cluster- must also be configured with the compact policy (Figure 1). If you don't set this property correctly, the connector won't be able to start and errors will appear in the Kafka Connect log.

The topics to create are:
avroavro.inventory.addressesavro.inventory.customersavro.inventory.geomavro.inventory.orders)avro.inventory.productsavro.inventory.products_on_handdebezium-cluster-configsdebezium-cluster-offsetsdebezium-cluster-statusschema-changes.inventory
The resulting table of topics should look like Figure 2.
Configure the database history
In a separate database history Kafka topic, the Debezium connector for MySQL records all data definition language (DDL) statements along with the position in the binlog where each DDL statement appears. In order to store that information, the connector needs access to the target Kafka cluster, so you need to add the connection details to the connector configuration.
Create the following lines, inserting the correct values for your environment in your connector configuration to access OpenShift Streams for Apache Kafka. Add the lines as you did with the details of the converter. You need to configure the producer and consumer authentication independently:
"database.history.kafka.topic": "schema-changes.inventory",
"database.history.kafka.bootstrap.servers": "<your-boostrap-server>",
"database.history.producer.security.protocol": "SASL_SSL",
"database.history.producer.sasl.mechanism": "PLAIN",
"database.history.producer.sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=<kafka-sa-client-id> password=<kafka-sa-client-secret>;",
"database.history.consumer.security.protocol": "SASL_SSL",
"database.history.consumer.sasl.mechanism": "PLAIN",
"database.history.consumer.sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=<kafka-sa-client-id> password=<kafka-sa-client-secret>;",
You can check the final file configuration by viewing the dbz-mysql-openshift-registry-avro.json file under the main folder.
Create the connector
Now that the configuration for the connector is ready, add the configuration to the Kafka Connect cluster so that it starts the task that captures changes to the database. Use the kcctl command-line client for Kafka Connect, which allows you to register and examine connectors, delete them, and restart them, among other features.
Configure the kcctl context:
$ kcctl config set-context --cluster http://localhost:8083 local
Register the connector:
$ kcctl apply -f dbz-mysql-openshift-registry-avro.json
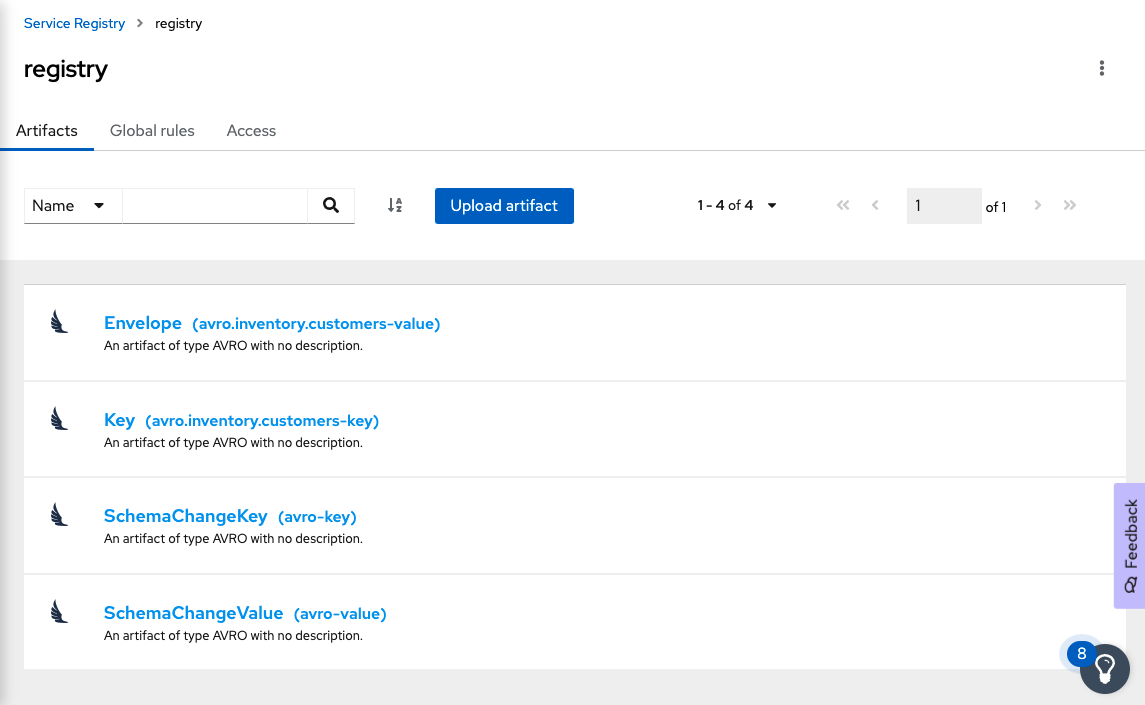
Check the registry
Go to the OpenShift Service Registry console. There you should find all the schema artifacts, as shown in Figure 3.
Check the data
Now use the kcat command-line utility to query the information stored in the OpenShift Streams Kafka cluster:
-
Set the environment variables in your terminal session to specify your cluster information:
$ export BOOTSTRAP_SERVER=<replace-with-bootstrap-server> $ export CLIENT_ID=<replace-with-kafka-sa-client-id> $ export CLIENT_SECRET=<replace-with-kafka-sa-client-secret> -
Check connectivity by querying the cluster metadata:
$ kcat -b $BOOTSTRAP_SERVER \ -X sasl.mechanisms=PLAIN \ -X security.protocol=SASL_SSL \ -X sasl.username="$CLIENT_ID" \ -X sasl.password="$CLIENT_SECRET" -LYou should get an output similar to the following:
Metadata for all topics (from broker -1: sasl_ssl://kafkaesque-c-isn-bhfjlsl-g-dana.bf2.kafka.rhcloud.com:443/bootstrap): 3 brokers: broker 0 at broker-0-kafkaesque-c-isn-bhfjlsl-g-dana.bf2.kafka.rhcloud.com:443 (controller) broker 2 at broker-2-kafkaesque-c-isn-bhfjlsl-g-dana.bf2.kafka.rhcloud.com:443 broker 1 at broker-1-kafkaesque-c-isn-bhfjlsl-g-dana.bf2.kafka.rhcloud.com:443 11 topics: topic "avro.inventory.orders" with 1 partitions: partition 0, leader 0, replicas: 0,1,2, isrs: 0,1,2 topic "avro.inventory.addresses" with 1 partitions: partition 0, leader 2, replicas: 2,0,1, isrs: 2,0,1 topic "debezium-cluster-configs" with 1 partitions: partition 0, leader 2, replicas: 2,0,1, isrs: 2,0,1 topic "debezium-cluster-offsets" with 1 partitions: partition 0, leader 0, replicas: 0,1,2, isrs: 0,1,2 topic "avro.inventory.products" with 1 partitions: partition 0, leader 0, replicas: 0,2,1, isrs: 0,2,1 topic "debezium-cluster-status" with 1 partitions: partition 0, leader 0, replicas: 0,2,1, isrs: 0,2,1 topic "avro" with 1 partitions: partition 0, leader 1, replicas: 1,2,0, isrs: 1,2,0 topic "avro.inventory.geom" with 1 partitions: partition 0, leader 0, replicas: 0,2,1, isrs: 0,2,1 topic "schema-changes.inventory" with 1 partitions: partition 0, leader 2, replicas: 2,0,1, isrs: 2,0,1 topic "avro.inventory.products_on_hand" with 1 partitions: partition 0, leader 0, replicas: 0,2,1, isrs: 0,2,1 topic "avro.inventory.customers" with 1 partitions: partition 0, leader 1, replicas: 1,2,0, isrs: 1,2,0 -
Now check the records in the
customerstopic:$ kcat -b $BOOTSTRAP_SERVER \ -X sasl.mechanisms=PLAIN \ -X security.protocol=SASL_SSL \ -X sasl.username="$CLIENT_ID" \ -X sasl.password="$CLIENT_SECRET" \ -t avro.inventory.customers -C -eYou should see the following four scrambled records in the terminal:
� Sally Thomas*sally.thomas@acme.com01.5.4.Final-redhat-00001 mysqavro����trueinventorycustomers mysql-bin.000003�r����_ � George Bailey$gbailey@foobar.com01.5.4.Final-redhat-00001 mysqavro����trueinventorycustomers mysql-bin.000003�r����_ � Edward Walkered@walker.com01.5.4.Final-redhat-00001 mysqavro����trueinventorycustomers mysql-bin.000003�r����_ AnneKretchmar$annek@noanswer.org01.5.4.Final-redhat-00001 mysqavro����lastinventorycustomers mysql-bin.000003�r����_ % Reached end of topic avro.inventory.customers [0] at offset 4The garbled formatting shows up because we are using Avro for serialization. The
kcatutility expects text strings and hence cannot convert the format correctly. The following step fixes the problem. -
Ask
kcatto connect with the OpenShift Service Registry so it can query the schema used and correctly deserialize the Avro records. OpenShift Service Registry supports various types of authentication; the following command uses basic authentication, specifying credentials in the formathttps://<username>:<password>@<URL>.:$ kcat -b $BOOTSTRAP_SERVER \ -X sasl.mechanisms=PLAIN \ -X security.protocol=SASL_SSL \ -X sasl.username="$CLIENT_ID" \ -X sasl.password="$CLIENT_SECRET" \ -t avro.inventory.customers -C -e \ -s avro -r https://<registry-sa-client-id>:<registry-sa-client-secret>@<registry-compatibility-api-url> | jqNow the records are displayed in a nicely formatted JSON structure:
... { "before": null, "after": { "Value": { "id": 1004, "first_name": "Anne", "last_name": "Kretchmar", "email": "annek@noanswer.org" } }, "source": { "version": "1.5.4.Final-redhat-00001", "connector": "mysql", "name": "avro", "ts_ms": 1642452727355, "snapshot": { "string": "last" }, "db": "inventory", "sequence": null, "table": { "string": "customers" }, "server_id": 0, "gtid": null, "file": "mysql-bin.000003", "pos": 154, "row": 0, "thread": null, "query": null }, "op": "r", "ts_ms": { "long": 1642452727355 }, "transaction": null }
Conclusion
Congratulations! You can send Avro serialized records from MySQL to OpenShift Streams for Apache Kafka using OpenShift Service Registry. Visit the following links to learn more:
Last updated: March 18, 2024