Apache Kafka makes it possible to run a variety of analytics on large-scale data. This is the first half of a two-part article that employs one of Kafka's most popular projects, the Kafka Streams API, to analyze data from an online interactive game. Our example uses the Kafka Streams API along with the following Red Hat technologies:
- Red Hat OpenShift Streams for Apache Kafka is a fully hosted and managed Apache Kafka service.
- Red Hat OpenShift Application Services simplifies provisioning and interaction with managed Kafka clusters, and integration with your applications.
- The Developer Sandbox for Red Hat OpenShift lets you deploy and test applications quickly.
The two-part article is based on a demonstration from Red Hat Summit 2021. This first part sets up the environment for analytics, and the second part runs the analytics along with replaying games from saved data.
Why do game data analysis?
Sources indicate that there are approximately three billion active gamers around the globe. Our pocket-sized supercomputers and their high-speed internet connections have made gaming more accessible than it has ever been. These factors also make data generated during gameplay more accessible and enable developers to constantly improve games after their release. This continuous iteration requires data-driven decision-making that's based on events and telemetry captured during gameplay.
According to steamcharts.com, the most popular games often have up to one million concurrent players online—and that’s just the PC versions of those games! That number of players will generate enormous amounts of valuable telemetry data. How can development teams ingest such large volumes of data and put it to good use?
Uses of game telemetry data
A practical example can help solidify the value of game telemetry data. The developers of a competitive online FPS (first-person shooter) game could send an enormous amount of telemetry events related to player activity. Some simple events and data might include:
- The player’s location in the game world, recorded every N seconds.
- Weapon choices and changes.
- Each time the player fires a shot.
- Each time a player successfully hits an opponent.
- Items the player obtains.
- Player wins and losses.
- Player connection quality and approximate physical location.
Game developers could use the data in these events to determine the busy or hot spots on the game world, the popularity of specific weapons, the players' shooting accuracy, and even the accuracy of players using specific weapons.
Developers could use this information to make game balance adjustments. For example, if a specific weapon is consistently chosen by 50% of players and their accuracy with that weapon is higher than with other weapons, there’s a chance that the weapon is overpowered or bugged.
Network engineers could ingest the player ping time and location to generate Grafana dashboard and alerts, isolate problems, and reference the data when choosing new data center locations.
Marketers could also use the data to market power-ups or incentives to players down on their luck if the game supports microtransactions.
Example and prerequisites
This article shows you how to employ Red Hat OpenShift Streams for Apache Kafka with the Kafka Streams API to ingest and analyze real-time events and telemetry reported by a game server, using a practical example. Specifically, you’ll learn how to:
- Use the Red Hat OpenShift Application Services CLI and OpenShift Streams for Apache Kafka to:
- Provision Kafka clusters.
- Manage Kafka topics.
- Connect your OpenShift project to a managed Kafka instance.
- Develop a Java application using the Kafka Streams API to process event data.
- Expose HTTP endpoints to the processed data using Quarkus and MicroProfile.
- Deploy Node.js and Java applications on Red Hat OpenShift and connect them to your OpenShift Streams for Apache Kafka cluster.
To follow along with the examples, you’ll need:
- Access to Red Hat OpenShift Streams for Apache Kafka. You can get a free account at the Getting started site.
- Access to Developer Sandbox. Use the Get started in the Sandbox link on the Developer Sandbox welcome page to get access for free.
- The Red Hat OpenShift Application Services command-line interface (CLI). Installation instructions are available on GitHub.
- The OpenShift CLI. The tool is available at the page of files for downloading.
- The Git CLI. Downloads are available at the Git download page.
The demo application: Shipwars
If you attended Red Hat Summit 2021 you might have already played our Shipwars game. This is a browser-based video game (Figure 1) that’s similar to the classic Battleship tabletop game, but with a smaller 5x5 board and a server-side AI opponent.

Shipwars is a relatively simple game, unlike the complex shooter game described earlier. Despite the simplicity of Shipwars, it generates useful events for you to process. We'll focus on two specific events:
- Player: Created when a player connects to the server and is assigned a generated username; for example, "Wool Pegasus" from Figure 1.
- Attack: Sent whenever a player attacks. Each player will attack at least 13 times, because a minimum of 14 hits are required to sink all of the opponent’s ships.
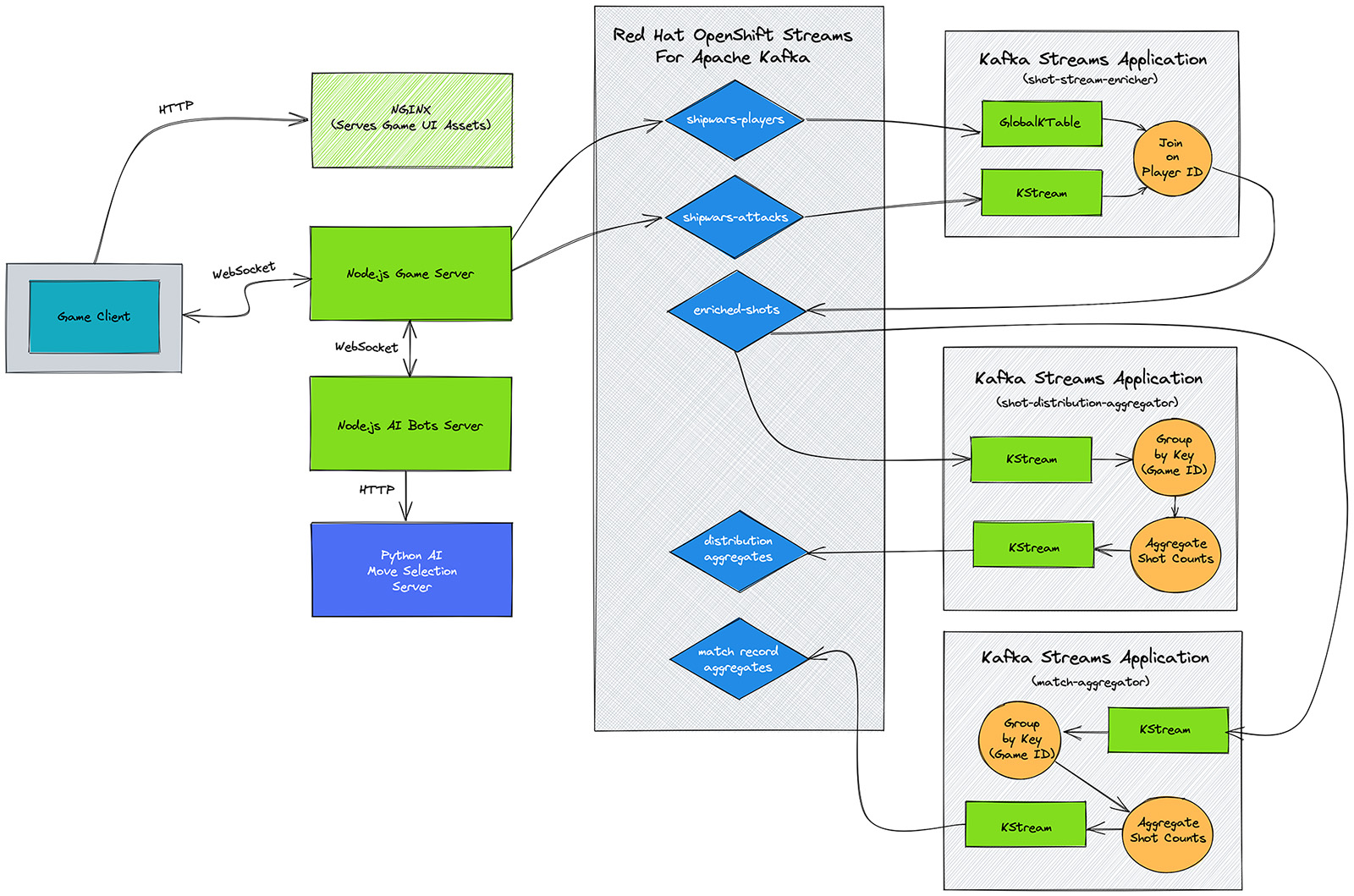
You’ll deploy the Shipwars microservices and send these events to a managed Kafka instance running on OpenShift Streams for Apache Kafka. You’ll also use Kafka Streams to process events generated by the game. This involves using Kafka Streams to:
- Join data from two separate Kafka topics.
- Create aggregations using the joined data stream.
The join can be used to create a real-time heatmap of player shots. It is also a prerequisite for the aggregation stage.
The aggregations can be used to:
- Create and store records of completed games with each turn in order.
- Analyze how human players compare to their AI counterparts.
- Continuously update your AI model.
Figure 2 shows the overall architecture of core game services, topics in Red Hat OpenShift Streams for Apache Kafka, and the Kafka Streams topology you’ll create.
Deploying the core Shipwars services on the Developer Sandbox
The README file in Red Hat's Shipwars deployment repository can help you quickly deploy the game.
The first step is to deploy Shipwars on the Developer Sandbox. Shipwars can run without Kafka integration, so you’ll add the Kafka integration after the core game microservices are running.
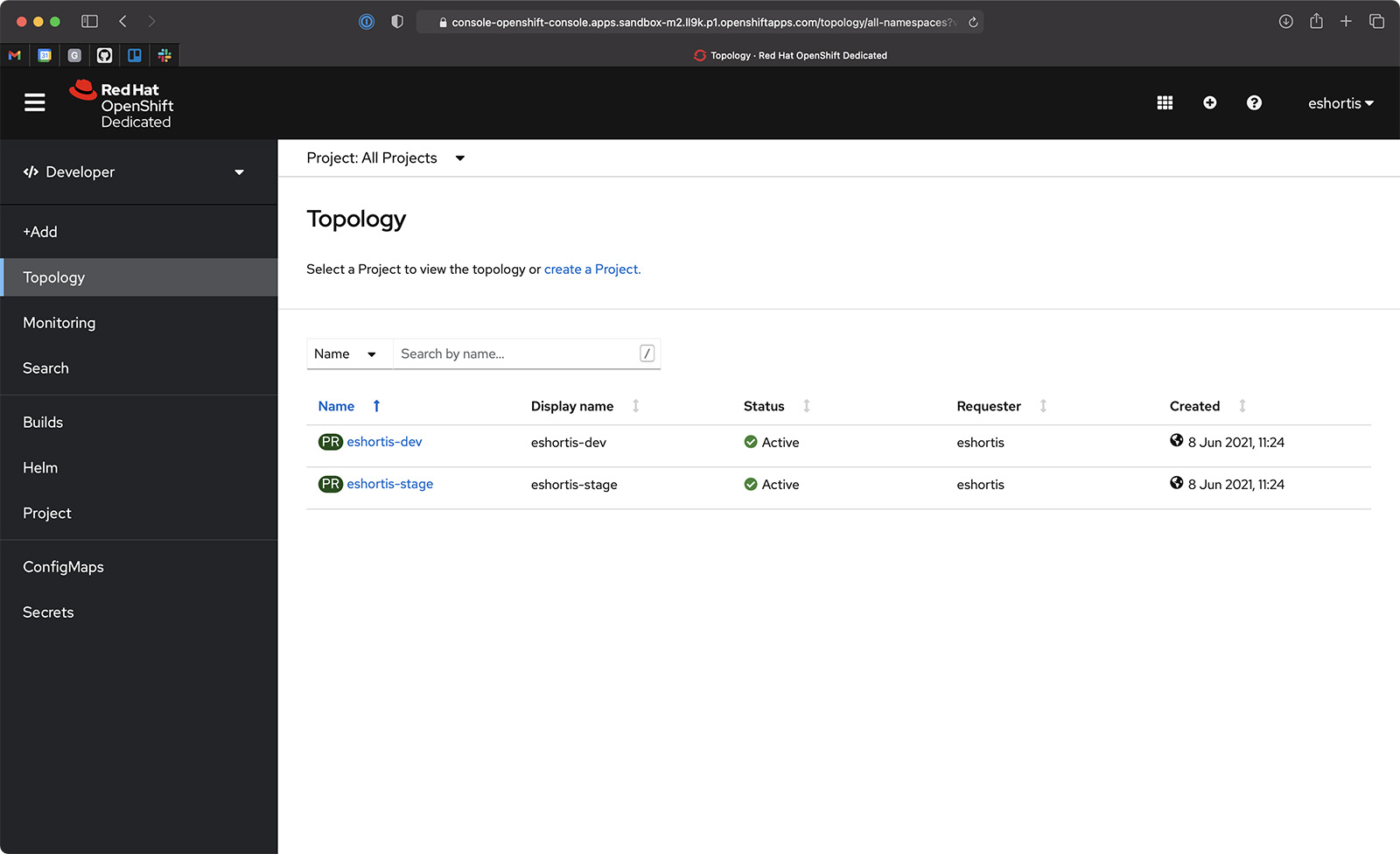
Get started by accessing the Developer Sandbox. Once you're logged in, you should see two empty projects (namespaces). For example, my projects are eshortis-dev and eshortis-stage, as shown in Figure 3. I use the dev namespace throughout this two-part article.
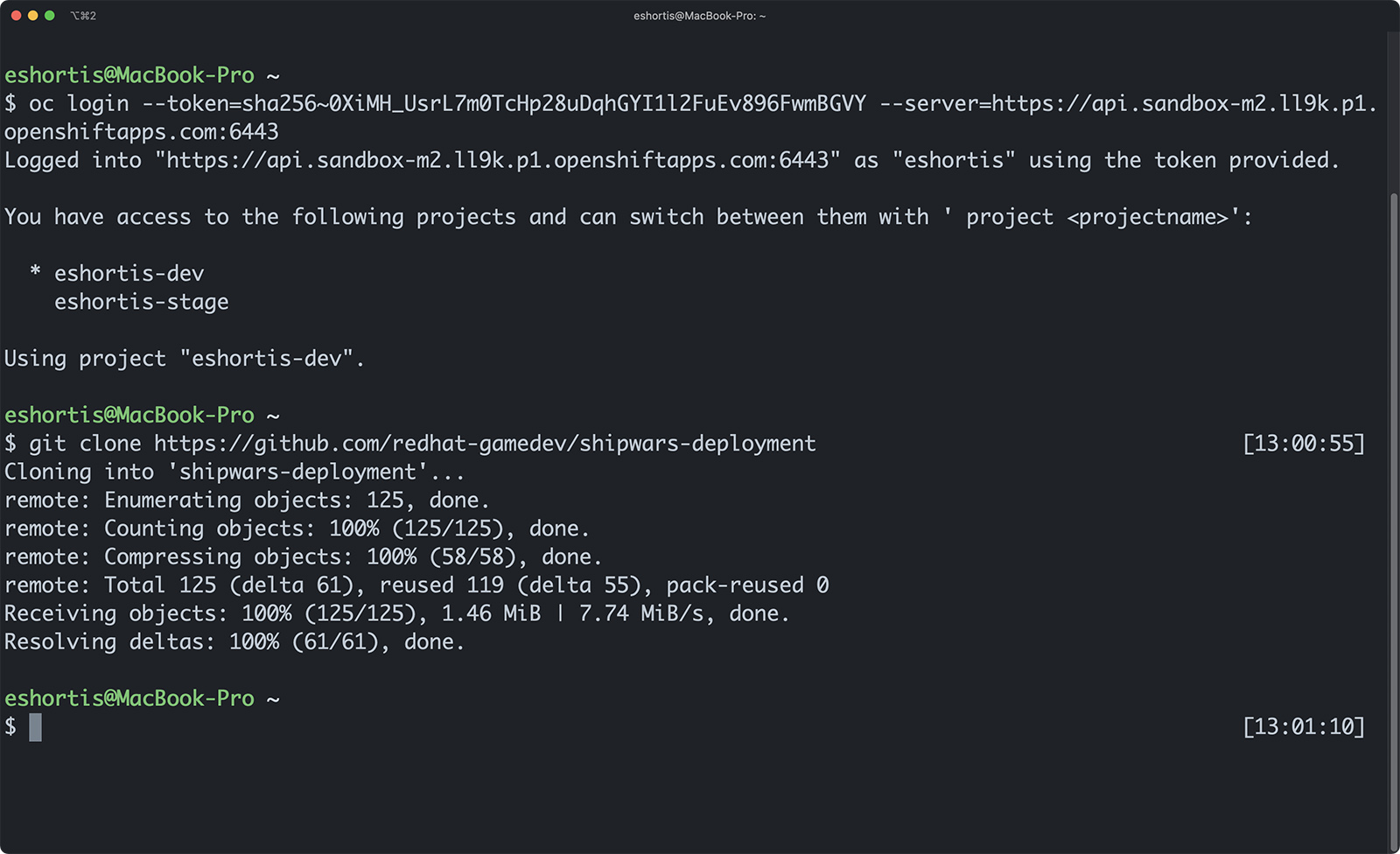
The deployment process for Shipwars uses the OpenShift CLI. Do the following to obtain the OpenShift CLl login command and token:
- Click your username in the top-right corner of the OpenShift Sandbox UI.
- Click Copy Login Command.
- Select the DevSandbox login option when prompted.
- Click Display Token.
- Copy and paste the displayed login command into your terminal.
After a successful login, the OpenShift CLI prints your available projects.
Next, use the git clone command to clone the shipwars-deployment repository into your workspace. Figure 4 shows both the OpenShift CLI and Git CLI commands.
A script is included to deploy Shipwars. This is a straightforward script that applies YAML files so you can get to the Kafka content more quickly:
$ git clone https://github.com/redhat-gamedev/shipwars-deployment
$ cd shipwars-deployment/openshift
$ NAMESPACE=eshortis-dev ./deploy.game.sh
Note: The NAMESPACE variable must be set to a valid namespace in your Developer Sandbox. The eshortis-dev value used here is an example, and must be replaced with the equivalent for your username, such as myusername-dev.
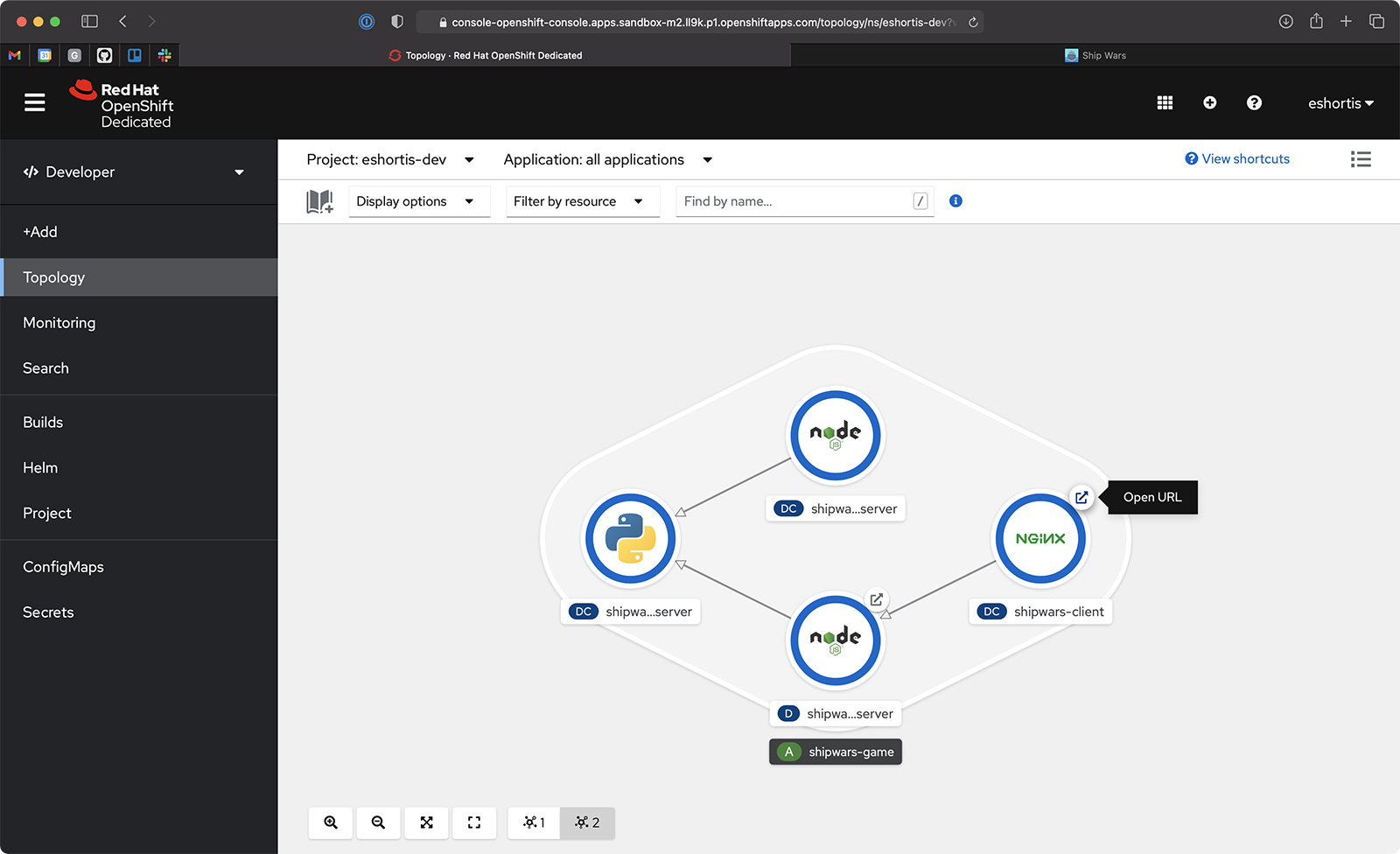
The script prints the resource types as it creates them. Once it is finished, you can view the deployed services in the OpenShift topology view. You can also click the Open URL link on the NGINX service, as shown in Figure 5, to view and play the Shipwars game against an AI opponent.
Creating a Kafka instance and topics
If you’re not familiar with the basics of OpenShift Streams for Apache Kafka, consider reviewing this introductory article: Getting started with Red Hat OpenShift Streams for Apache Kafka. It covers the basics of creating Kafka instances, topics, and service accounts.
In this article, we use the Red Hat OpenShift Application Services CLI, rhoas, to manage the creation of everything needed to integrate OpenShift Streams for Apache Kafka with the Shipwars game server you deployed on the Developer Sandbox.
To get started, log in to your cloud.redhat.com account and create a Kafka instance using the following commands:
# Login using the browser flow
rhoas login
# Create a kafka instance
rhoas kafka create shipwars
The kafka create command will complete within a few seconds, but the Kafka instance won’t be ready at this point. Wait for two or three minutes, then issue a rhoas kafka list command. This lists your Kafka instances and their status. You can continue with the procedure in this article when the shipwars instance status is "ready," as shown in Figure 6.
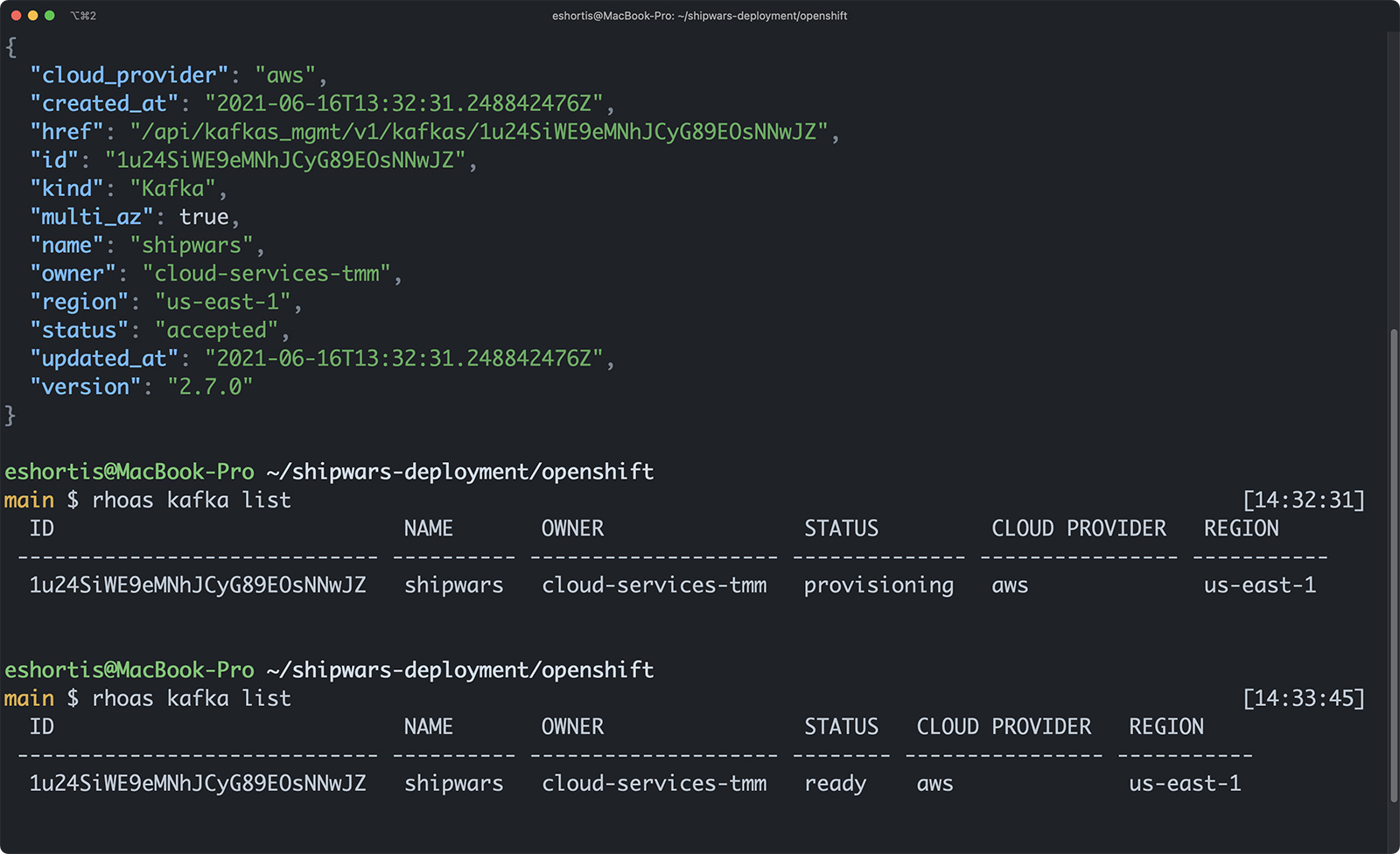
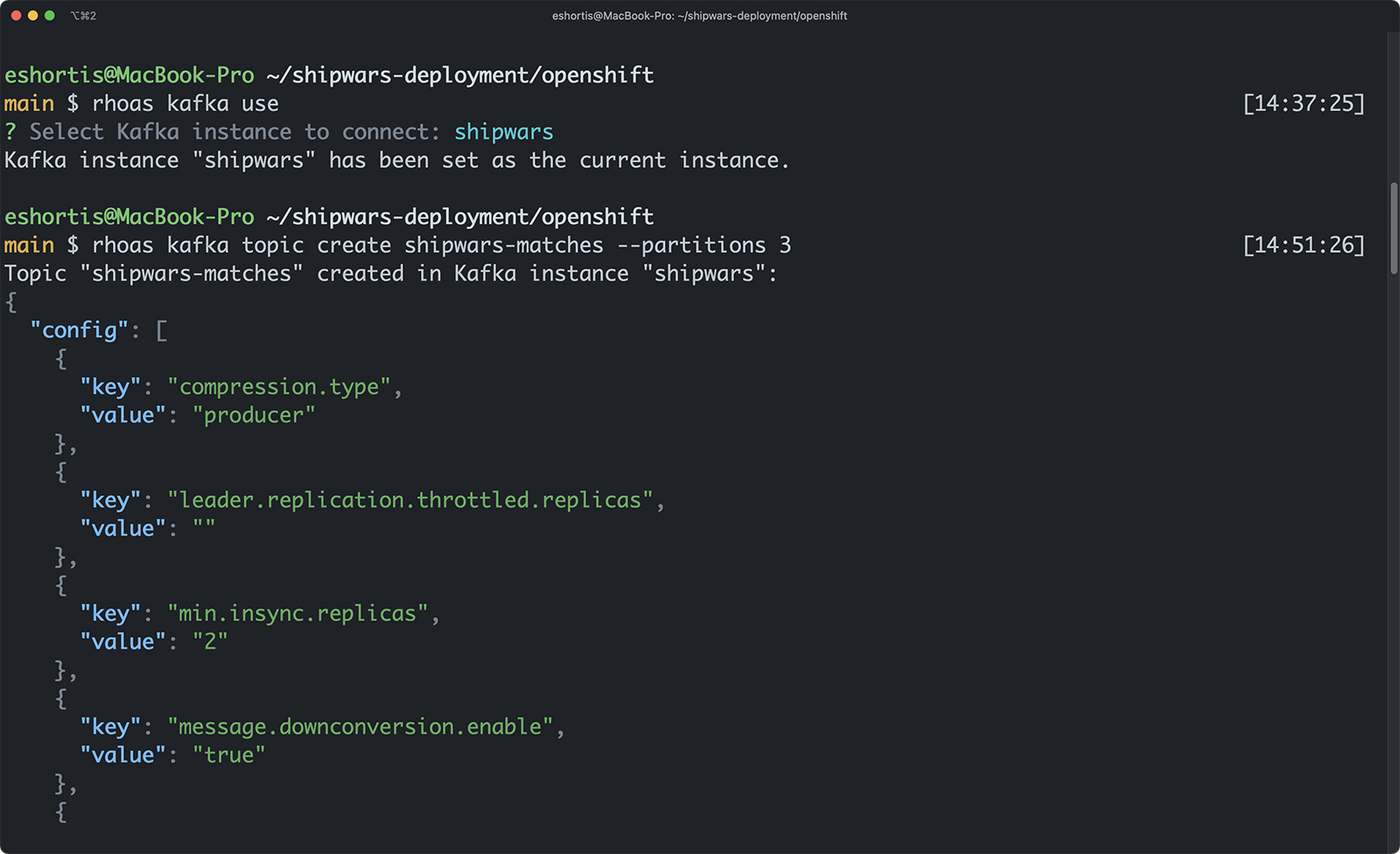
The Red Hat OpenShift Application Services CLI allows you to select a Kafka instance as the context for future commands. Select your newly created shipwars instance using the rhoas kafka use command, then create the necessary topics as follows:
# Choose the kafka instance to create topics in
rhoas kafka use
# Create necessary game event topics
rhoas kafka topic create shipwars-matches --partitions 3
rhoas kafka topic create shipwars-players --partitions 3
rhoas kafka topic create shipwars-attacks --partitions 3
rhoas kafka topic create shipwars-bonuses --partitions 3
rhoas kafka topic create shipwars-results --partitions 3
# Create topics used by Kafka Streams
rhoas kafka topic create shipwars-attacks-lite --partitions 3
rhoas kafka topic create shipwars-streams-shots-aggregate --partitions 3
rhoas kafka topic create shipwars-streams-matches-aggregate --partitions 3
The topic configuration is printed in JSON format after each topic is created, as shown in Figure 7. The only configuration that you’ve explicitly set for your topics is the partition count; other values use sensible defaults.
Service accounts used by applications to authenticate against your Kafka instance and produce or consume from topics will require configuring the necessary access rules. For simplicity, create a global access rule using the following command:
rhoas kafka acl grant-access --consumer --producer --all-accounts --topic-prefix shipwars --group "*"
Note that it is not advised to do this in production environments, but it keeps things simple for the purposes of this guide.
Connecting to the Shipwars game server
At this point, you’ve obtained a managed Kafka instance and configured it with the topics required by the Shipwars game. The next step is to configure the Node.js shipwars-game-server to connect to your topics and send events to them. This is a two-step process.
First, you need to link your OpenShift project to your managed Kafka instance. You can do this by issuing the rhoas cluster connect command. The command starts a guided process that will ask you to confirm the project and managed Kafka instance being linked, and request you to provide a token obtained from a cloud.redhat.com/openshift/token as shown in Figure 8.
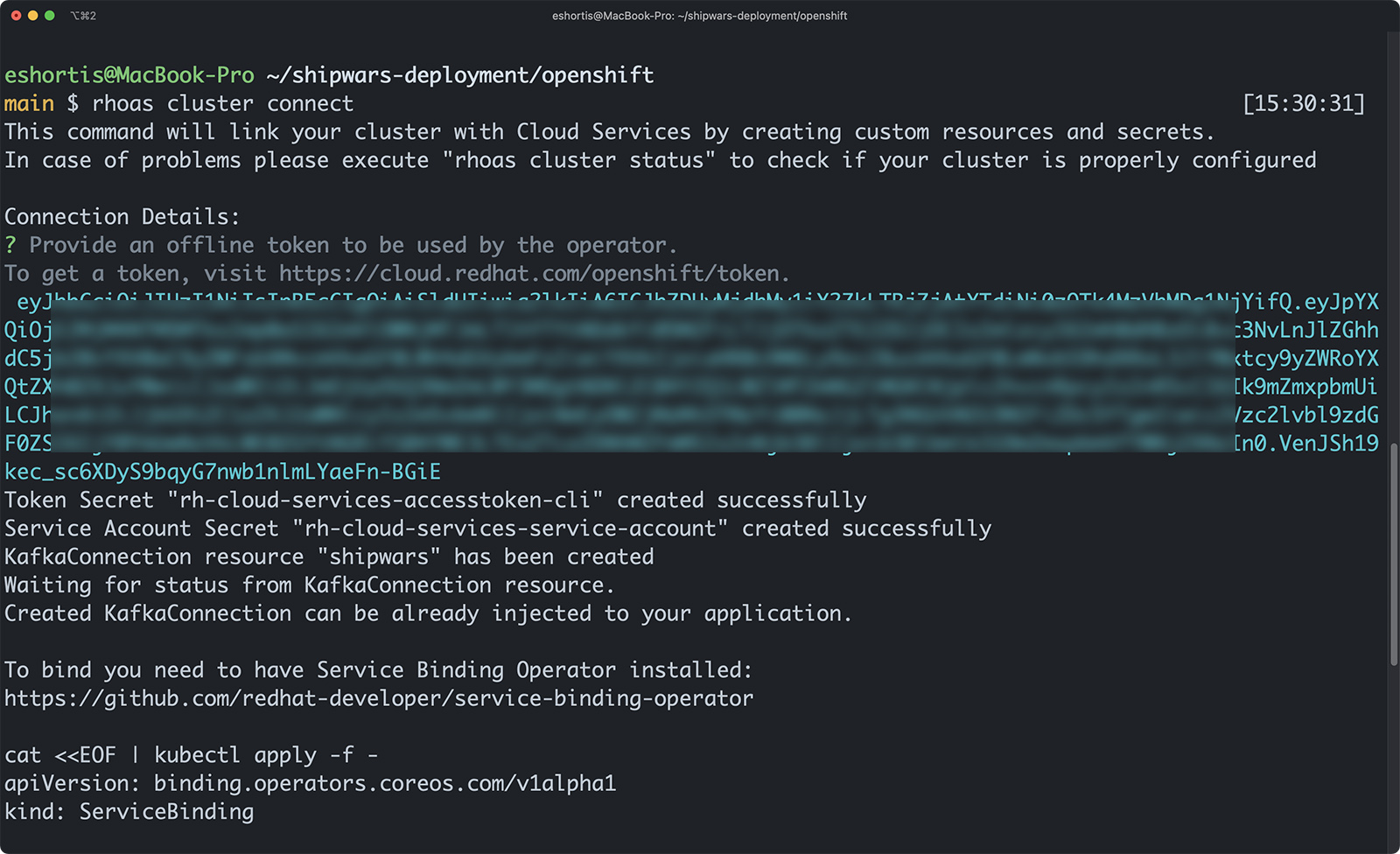
This process creates the following resources in the target OpenShift project:
- A
KafkaConnectioncustom resource that contains information such as bootstrap server URL and SASL mechanism. - A
Secretthat contains the service account credentials for connecting to the Kafka instance via SASL SSL. - A
Secretthat contains your cloud.redhat.com token.
Next, run the rhoas cluster bind command. This guides you through the process of creating a ServiceBinding and updates the shipwars-game-server Deployment with the credentials required to connect to your managed Kafka instance.
Once the binding process has completed, a new Secret is generated and mounted into a new pod of the shipwars-game-server Deployment. You can explore the contents of this secret using the OpenShift CLI or UI, as shown in Figure 9.
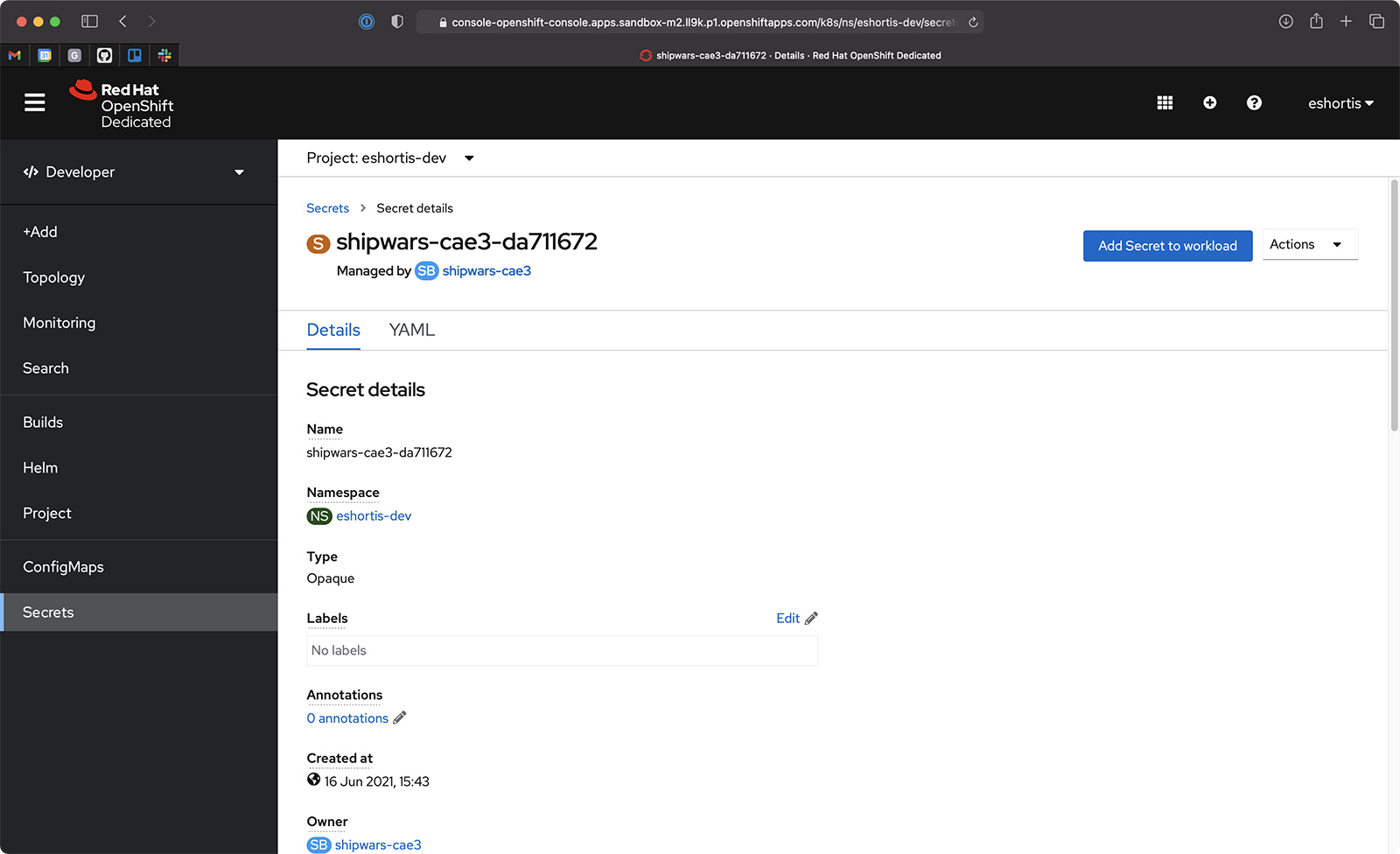
Lastly, you can confirm that the Node.js-based shipwars-game-server has connected to your managed Kafka instance by viewing its logs. Find the logs by selecting the shipwars-game-server from the OpenShift topology view, selecting the Resources tab, and clicking the View logs link. The startup logs should contain a message stating that a Kafka producer has connected to the managed Kafka instance bootstrap server URL, as shown in Figure 10.

Conclusion to Part 1
In this first half of the article, we have set up our game and our environment for analytics. In the second half, we'll run analytics and replay some games. For now, you can verify that game events are being streamed to your managed Kafka instance using a tool such as kafkacat. As an example, the following command outputs the contents of the shipwars-attacks topic as it receives events from the shipwars-game-server:
$ kafkacat -t shipwars-attacks-b $KAFKA_BOOTSTRAP_SERVER \
-X sasl.mechanisms=PLAIN \
-X security.protocol=SASL_SSL \
-X sasl.username=$CLIENT_ID \
-X sasl.password=$CLIENT_SECRET -K " / " -C
Last updated:
December 27, 2023