In today's cloud-native environments, network security is paramount. OpenShift, with its powerful network policy capabilities, allows for granular control over pod-to-pod communication. But how do you ensure these policies scale effectively under load? At the Red Hat Performance & Scale team, we've developed a comprehensive network policy workload to generate unique Access Control List (ACL) flows when network policies are created at scale and measure the latency associated with enforcing these policies.
Understanding the Challenge of Network Policy Scale Testing
Network policies in OpenShift define ingress and egress traffic rules between pods, both within the same namespace and across different namespaces. These policies can involve complex selectors, CIDR blocks, and port ranges, leading to a vast number of possible configurations. For scale testing, it's crucial to create a workload that generates unique Access Control List (ACL) flows to accurately simulate real-world scenarios.
Introducing Our Unified Template Configuration
Our journey began by developing a unified ingress and egress template that encompasses all possible network policy configuration parameters. These templates allowusers to specify the desired number of each option, such as remote namespaces, pods, CIDRs, and port ranges as job object input variables.
For example, executing the command:
kube-burner-ocp network-policy --iterations 50 --pods-per-namespace 10 --netpol-per-namespace 10 --local-pods 2 --single-ports 2 --port-ranges 2 --remotes-namespaces 2 --remotes-pods 2 --cidrs 2passes these parameters to the templates
objects:
- objectTemplate: ingress-np.yml
replicas: 10
inputVars:
namespaces: 50
pods_per_namespace: 10
netpols_per_namespace: 10
local_pods: 2
pod_selectors: 1
single_ports: 2
port_ranges: 2
peer_namespaces: 2
peer_pods: 2
cidr_rules: 2In this scenario, the first namespace would have 10 network policies from ‘ingress-0-1’ to ‘ingress-0-10’. Kube-burner then selects different configuration options for each policy. For example, the ‘ingress-0-1’ and ‘ingress-0-2’ policies might look like this:
ingress-0-1 | ingress-0-2 |
ingress: - from: - namespaceSelector: matchExpressions: - key: kubernetes.io/metadata.name operator: In values: - network-policy-perf-1 - network-policy-perf-2 podSelector: matchExpressions: - key: num operator: In values: - "1" - "2" ports: - port: 8080 protocol: TCP - port: 8081 protocol: TCP - from: - ipBlock: cidr: 1.0.6.0/24 ports: - port: 1001 protocol: TCP - port: 1002 protocol: TCP - from: - ipBlock: cidr: 1.0.7.0/24 ports: - port: 1001 protocol: TCP - port: 1002 protocol: TCP podSelector: matchExpressions: - key: num operator: In values: - "1" - "2" | ingress: - from: - namespaceSelector: matchExpressions: - key: kubernetes.io/metadata.name operator: In values: - network-policy-perf-3 - network-policy-perf-4 podSelector: matchExpressions: - key: num operator: In values: - "1" - "2" ports: - port: 8080 protocol: TCP - port: 8081 protocol: TCP - from: - ipBlock: cidr: 1.0.8.0/24 ports: - port: 1001 protocol: TCP - port: 1002 protocol: TCP - from: - ipBlock: cidr: 1.0.9.0/24 ports: - port: 1001 protocol: TCP - port: 1002 protocol: TCP podSelector: matchExpressions: - key: num operator: In values: - "1" - "2" |
Note: Please note that for the sake of clarity, certain details have been omitted from the network policy example depicted in the preceding table.
This flexibility ensures that our workload can adapt to various testing requirements.
Key Design Principles for Scale Testing
To achieve realistic scale testing, we focused on several key principles:
- Round-Robin Assignment: We employ a round-robin strategy for distributing remote namespaces across ingress and egress rules. This prevents the overuse of the same remote namespaces in a single iteration and ensures diverse traffic patterns.
- Unique Namespace and Pod Combinations: Our templating system generates unique combinations of remote namespaces and pods for each network policy. This eliminates redundant flows and creates distinct ACL entries.
- CIDRs and Port Range Diversity: Similar to namespaces and pods, we apply the round-robin and unique combination logic to CIDRs and port ranges, further enhancing the variety of network policy configurations.
Connection Testing and Latency Measurement
Our workload also includes connection testing capabilities to measure the latency associated with enforcing network policies. Here’s a breakdown of how it works:
- Proxy Pod Initialization: A proxy pod, `network-policy-proxy`, is created to distribute connection information to client pods.
- Job Execution: Two separate jobs are executed. The first creates namespaces and pods, while the second applies network policies and tests connections. The advantages with this approach are:
- OVN components are dedicated only to network policy processing
- CPU & memory usage metrics captured are isolated for only network policy creation
- Network policy latency calculation doesn’t include pod readiness as pods already exist
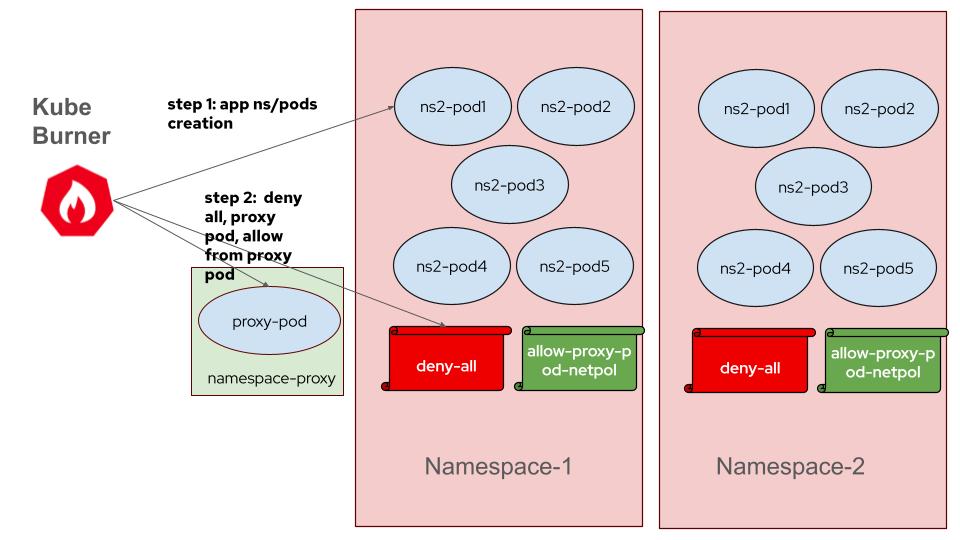
(I greatly appreciate Mohit Sheth for creating all the diagrams.)
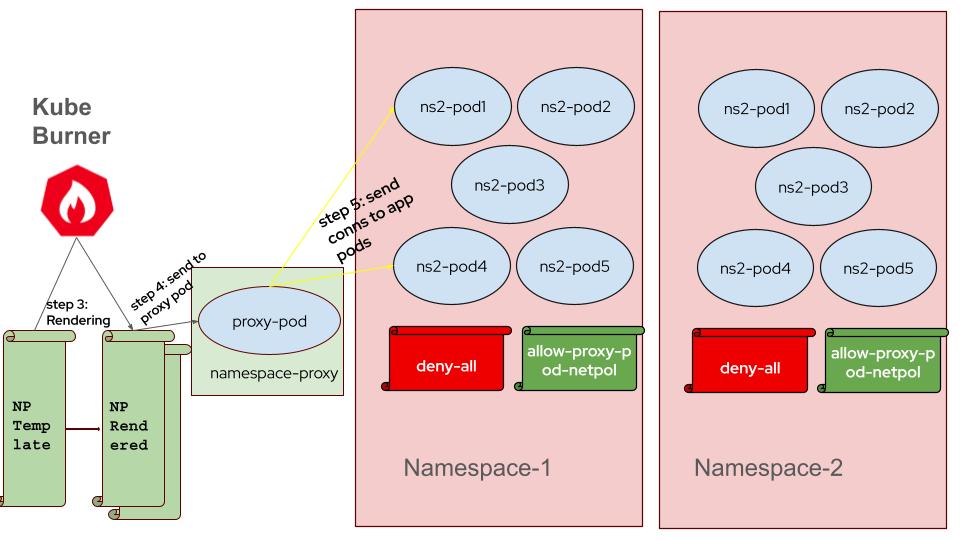
- Connection List Preparation: The workload parses the network policy template to prepare a list of connection details for each client pod, including remote IP addresses and ports.
For example, client pod1 in ns3 (10.128.10.53) has to ping client pod1 in ns2 (10.131.2.47) and client pod1 in ns1(10.130.2.209), then it receives below map,
10.128.10.53:[{[10.131.2.47 10.130.2.209] [8080] ingress-0-1}
Sending Connection Information: Kube-burner passes the prepared connection information to the client pods via the `network-policy-proxy` pod and waits until the proxy pod confirms that all client pods have received the information.
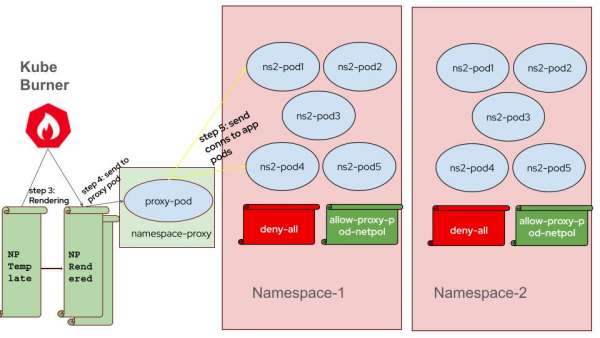
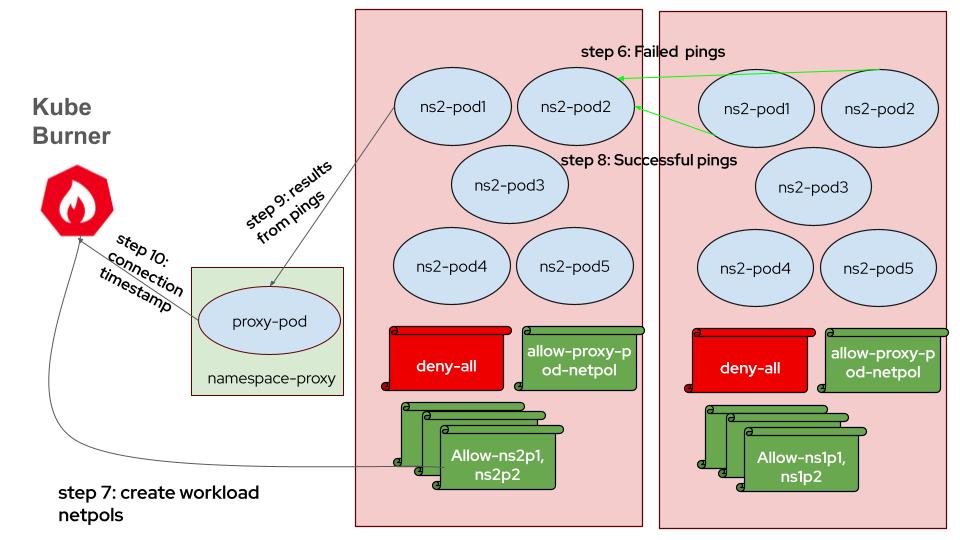
- HTTP Requests and Network Policy Creation: Client pods initially send failing HTTP requests. Once network policies are applied, these requests succeed, and the client pods record timestamps of successful connections.
- Latency Calculation: Latency is calculated by comparing the recorded connection timestamps with the timestamps of when network policies were created, representing the time for network policy enforcement.
Conclusion
Developing this network policy workload has been a significant step in ensuring the robustness and scalability of OpenShift network policies. By generating diverse and unique ACL flows and accurately measuring connection latency, our tool provides valuable insights into the performance of OpenShift's networking infrastructure under load. We finished our thorough scale testing with this network policy workload. In a follow-up blog post, we will share the detailed results, including performance metrics, observations, and key takeaways. This upcoming post will offer further insights into how OpenShift network policies perform under significant load.