In a previous blog post, we discussed the design of a new workload specifically created for network policy scale testing. This follow-up post will delve into the results of those tests, evaluating the scalability of network policies and how scaling affects OVS flow programming latency, system resources, and overall performance.
Test Objectives
Our primary objectives were to:
- Evaluate the scalability of OpenShift Network Policies.
- Measure OpenShift Network Policy readiness latency through connection testing.
- Measure CPU and Memory utilization during testing.
Testing Environment
Testing was conducted on a ROSA OCP 4.16.18 environment with 24 worker nodes.
Test Methodology
Our kube-burner network policy workload utilizes two jobs. Both jobs ran the same number of iterations and used the same namespaces. In a 24-worker node environment,
Job 1:
- Ran for 240 iterations.
- Each iteration created one namespace.
- Each created namespace contained 10 pods.
Job 2:
- Ran for a corresponding number of iterations (240)
- Each iteration targeted one of the namespaces created by Job 1.
- Within each targeted namespace, 20 network policies were created.
- Example: Job 2's first iteration created 20 network policies in namespace1 (which was created during Job 1's first iteration).
Network Policy Configuration
For our testing, each network policy had the following configurations:
| Configuration Item | Value | Description |
`single_ports` | 5 | Number of single ports in `ingress.from.ports` or `egress.to.ports`. |
`port_ranges` | 5 | Number of port ranges in `ingress.from.ports` or `egress.to.ports`. |
`remote_namespaces` | 5 | Number of namespace labels in `ingress.from.namespaceSelector.matchExpression`. |
`remote_pods` | 5 | Number of pod labels in `ingress.from.podSelector.matchExpressions`. |
`cidr_rules` | 5 | Number of `from.ipBlock.cidr` or `to.ipBlock.cidr` entries. |
`local_pods` | 10 | Number of local pods selected using `spec.podSelector.matchExpressions`. |
For a detailed explanation of how the workload configuration options translate into network policy configurations, please refer to my previous blog post.
Scenario 1: System Metrics Testing
This scenario measured system metrics by creating network policies with ingress and egress rules, focusing on resource usage rather than network policy latency.
- All the tests have 240 namespaces, each with 10 pods.
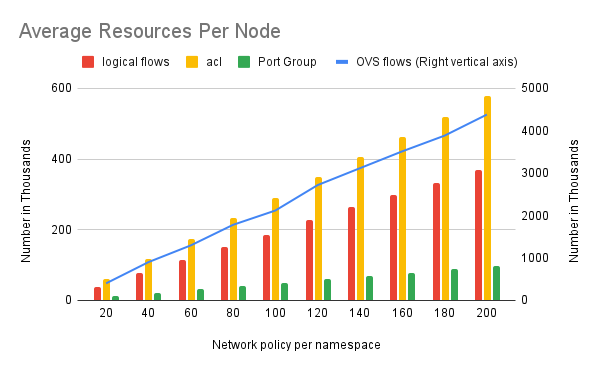
OVN resources created when we scale network policies. For example, 403K OVS flows per node created when each namespace has 20 network policies and 4381K when 200 network policies per namespace.
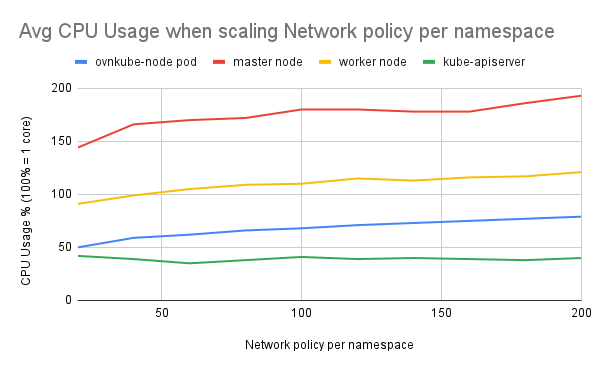
Average ovs-vswitchd CPU usage is around 5% across all the tests
Scenario 2: Network Policy Readiness Latency Testing
This scenario tested the time taken for programming OVS flows by measuring connection latency between client and server pods when a network policy is applied.
- Each network policy defined connections between 10 local pods and 25 remote pods. We test all the 250 connections for each network policy and the max latency among the 250 connections is reported as the network policy readiness latency.
- All the tests have 240 namespaces, each with 10 pods.
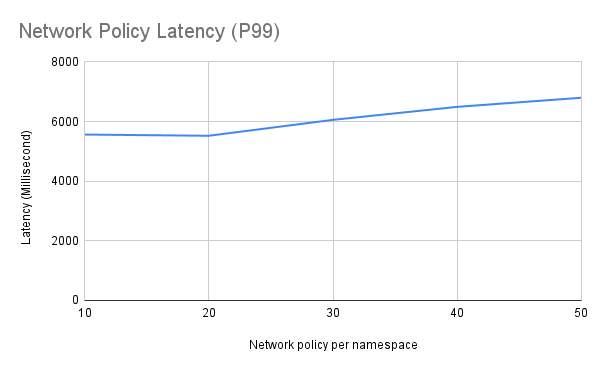
Observations
- Observed a proportional increase in OVS flows, logical flows, and ACLs with the increase in network policies.
- Successfully scaled to 4381K OVS flows per worker node.
- Average ovs-vswitchd CPU usage was around 5% across all tests.
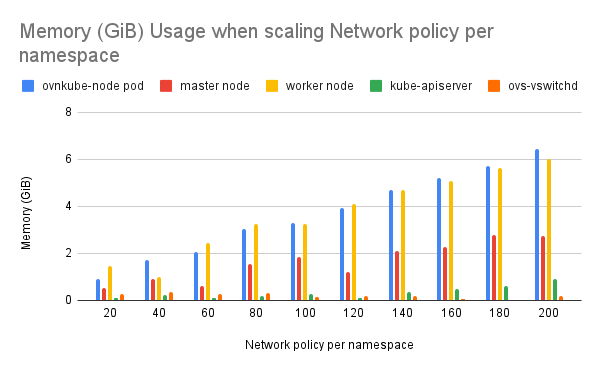
- Observed OVN components not releasing memory after resource cleanup (reported bug OCPBUGS-44430).
- Network policy readiness latency testing was successful even when the max OVS flows per worker node were 1016K. Network policy readiness latency is 5.5 seconds when we have 412K OVS flows per worker node.
- Worker node CPU usage was between 100% and 150% (100% = 1 core) during the testing.
- Worker node memory usage increased as OVS flows increased.
- Ovnkube-node pod and worker node CPU and memory usage increased with the number of network policies.
This scaling testing provides valuable insights into the performance and resource utilization of OpenShift Network Policies at scale. These results help us understand the limitations and potential bottlenecks when deploying a large number of network policies.
