Introduction
Thanks to a very important recent development in the Red Hat Cloud Services portfolio, customers can now easily lifecycle a fleet of Red Hat Openshift Services on AWS (ROSA) clusters using the newly developed Red Hat Cloud Services (RHCS) Terraform Provider (terraform-provider-rhcs). This Terraform Provider allows customers to deploy, scale & upgrade a fleet of ROSA clusters and also create & update machinepools in a turnkey fashion by taking advantage of Terraform's built-in features. In addition to that, the ROSA STS Terraform module gives customers the option to automate ROSA installation prerequisites, like operator IAM roles, policies, and identity providers. There are several blogs that provide an overview of the prerequisites and steps to use the provider and its modules and many ready-to-use templates are also available on Github.
This document delves into the performance & scale benefits of using this provider and throws light on the tips & best practices for deploying and managing a fleet of clusters using the RHCS Terraform provider.
Methodology
Testing the performance of applications/orchestrators typically has multiple layers. In this blog we will focus on understanding the performance and scale of the Terraform Provider for ROSA and discuss tunings to the Terraform configuration to help manage your ROSA cluster fleet at scale. We have used an in-house tool called hcp-burner for this scale testing, which is a wrapper to automate create-use-destroy of OCP clusters on different managed cloud platforms. For the purposes of this study, we enhanced its functionality to use terraform as a deployment method.
Terraform Configuration
We chose to use a simple terraform template to avoid complexity and keep the focus on the performance and scale aspects. We selected an example terraform template using managed OIDC configuration available in the upstream Github repository and added the below extra options for tooling.
During the test, we have used 2 key terraform options to achieve multiple cluster deployment at variable concurrency rate.
Count (Fleet size)
The count argument replicates the given resource or module a specific number of times with an incrementing counter. It works best when resources are identical, or nearly the same. In our case, we were creating a fleet of ROSA clusters of similar type and size, using the same AWS account, region and zone. Terraform tries to create all clusters at a time using its inbuilt concurrency logic, which can be controlled by another argument called Parallelism.
Parallelism (Concurrency)
This limits the number of concurrent operations as Terraform walks the graph. By default, it tries to create 10 resources at a time, so it might be a little aggressive on the API. Using this we control the deployment as it heavily impacts the results because of OCM inflight API rate limits and thresholds
Test Setup
Environment
- OCM staging environment
- ROSA classic
- STS
- Managed OIDC Config (shared)
- OCP 4.14.1
- 3 x Masters - m5.2xlarge
- 2 x Infra - r5.xlarge
- 2 x workers - m5.xlarge
- Disabled Autoscale
- Single Availability Zone clusters
Test Plan
- Simple cluster Installation performance
- Deploy a fleet of clusters using single definition
- All cluster runs on the same AWS account
- Enable Terraform Count and Parallelism to achieve best performance
Factors that impact test performance
There are some assumptions and factors to be considered that would have some implications on the observed results
- Size of each test cluster
- Number of pre-existing OCM resources which would affect response time
- External load on OCM API
- Number of pre-existing AWS resources would affect the cloud API response time
- AWS account level API rate and throttle limitation
- Environmental differences like Stage, Integration and Production. These tests were performed on staging environment
We observed that the OCM API gets overloaded during these tests because of the hcp-burner script that continuously polls for status. We set an interval of 5 seconds to control the rate of GETs and avoid DDoSing the API , so it is worth noting that the latency metrics will have a granularity of 5 seconds.
Also, the results are captured from multiple iterations of each test and these may vary depending on the above listed factors, such as the pre-existing cloud resources in the account. During these runs, the AWS account had many IAM, EC2, Route53 resources created as a part of some other testing activities, so the OCM service took a little longer to validate cloud quota and services. Therotically, the results could be slightly better on a cleaner and fresh account.
Key Performance Indicator (KPIs)
Key indicators that we have measured and recorded during these tests were installation success rate and cluster installation duration at different loads.
The different loads were generated using a combination of the below parameters:
Fleet - Number of clusters deployed using a single Terraform configuration
Concurrency - Concurrent Terraform operations
Installation Success Rate
The rate at which we can successfully complete the installation of the cluster, at different fleet sizes and concurrencies.
Latency
During installation, ROSA clusters will go through multiple phases and our tool calculates the time delta between each phase and records it. The phases are listed below
- waiting (Waiting for OIDC configuration)
- pending/validating (Checking AWS quota and Preparing account)
- installing
- ready
The time interval relies on multiple external factors as mentioned in the previous section. The latency metrics we present here measure the 99th percentile time taken in seconds for a cluster to move between phases in the fleet size tested
Init - Time taken between terraform apply and cluster showing up on performing an OCM GET. It also includes validation of the AWS account and user quota by OCM
Waiting - Time taken between Init and validating
Validating - Time taken between waiting and Install
Pre-flight - Sum of Init, Waiting and Validating
Ready - Time taken between installing and ready - this is control-plane ready duration.
The time taken for workers to become ready is not included as that depends on the cluster size and instance types.
Cloud and API Limitations
We have done a performance analysis on OCM using the API load test tool to benchmark limits and set some boundaries for these tests,
- OCM API cannot deploy more than 30 clusters per minute(tested fake clusters deployment)
- OCM API throttling while polling continuously for status(OCM returns 500 Internal Server Error)
- AWS API has a default Request rate and throttling limits so it cannot respond to API beyond that point (Failed to get service quota for service 'vpc' with quota code) and there is a bucket refill rate
- AWS API has a Resource rate and throttling limits (Longer EC2, IAM, Network resource creation time), More here
Knowing these boundaries, we designed our test parameters to create clusters with supported safe limits and as a result focus on the performance and scale testing of the Terraform Provider. We performed tests in different combinations using the below parameters.
Fleet Size - 10, 15, 30, 50 clusters
Concurrency - 3, 5, 10
Results
Cluster Installation Success Rate
On Creating multiple clusters at different Concurrencies using Terraform, it is evident that increasing parallel creation results in a higher failure rate. It was majorly due to timeouts or internal server errors from the system that processes the requests.
For this comparison, we have included a much smaller workload of a fleet of 10 clusters to show its best success rate.
The more it creates concurrently, the less the success rate is.
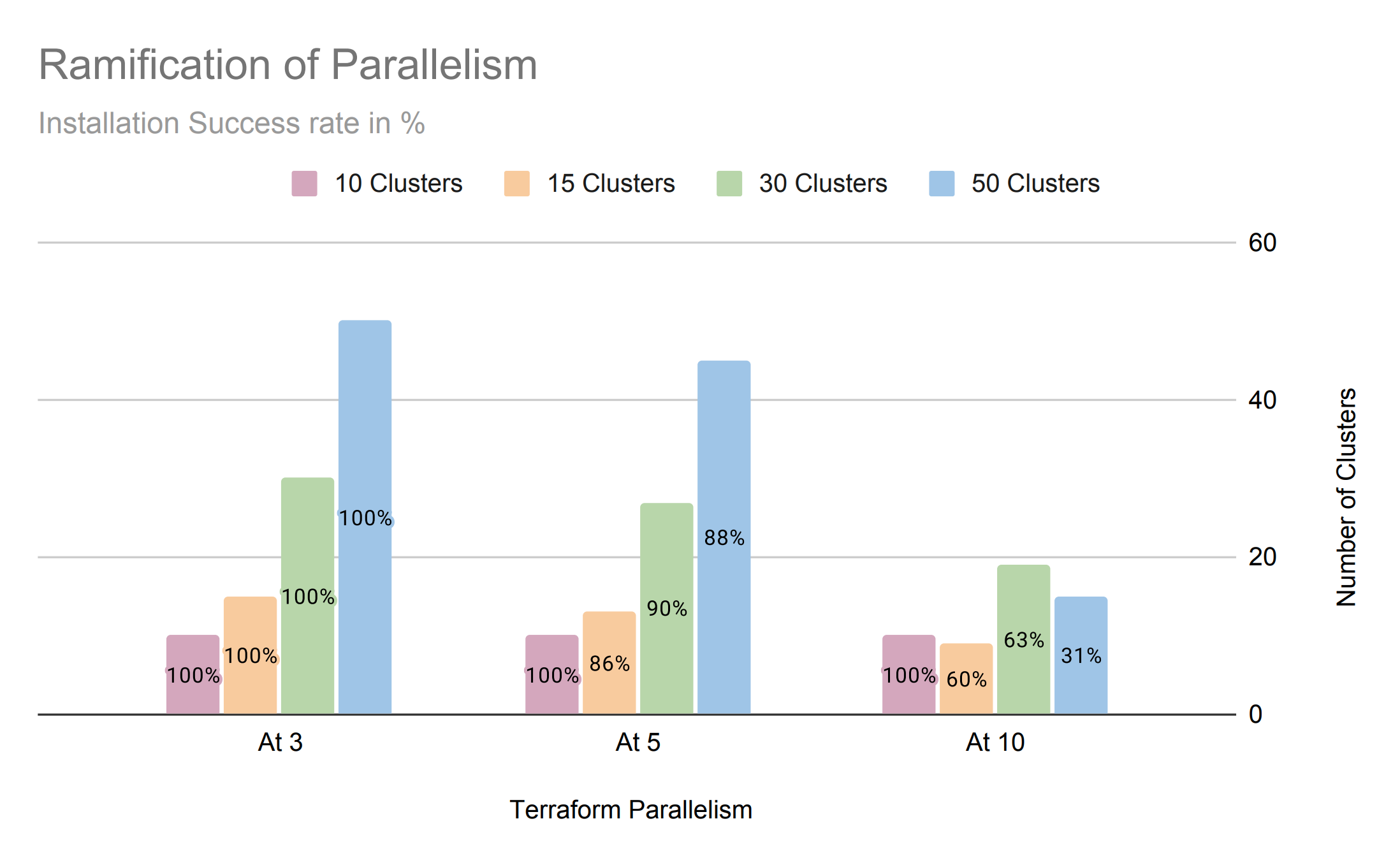
- Install Success rate is higher when parallelism is lower
- API rate limitation during initial account validation is a gate factor
- Parallelism of 10 performed consistently, deploying a fleet of 10 clusters was consistent throughout.
Install Duration
Cluster installation goes through multiple phases but can be majorly classified under 2 categories for easier comparison, first part being ‘pre-flight’ with all the preparation and validation steps and second part ‘installation’ that captures the time taken from pre-flight until the control plane of the cluster becomes ready.
The latency number we see here is 99th percentile of individual cluster timings.
On a smaller fleet, concurrency plays a key role. When it is lower the cluster creation is processed at smaller chunks at a time and that has a longer pre-flight duration, but it gets better with more concurrency.
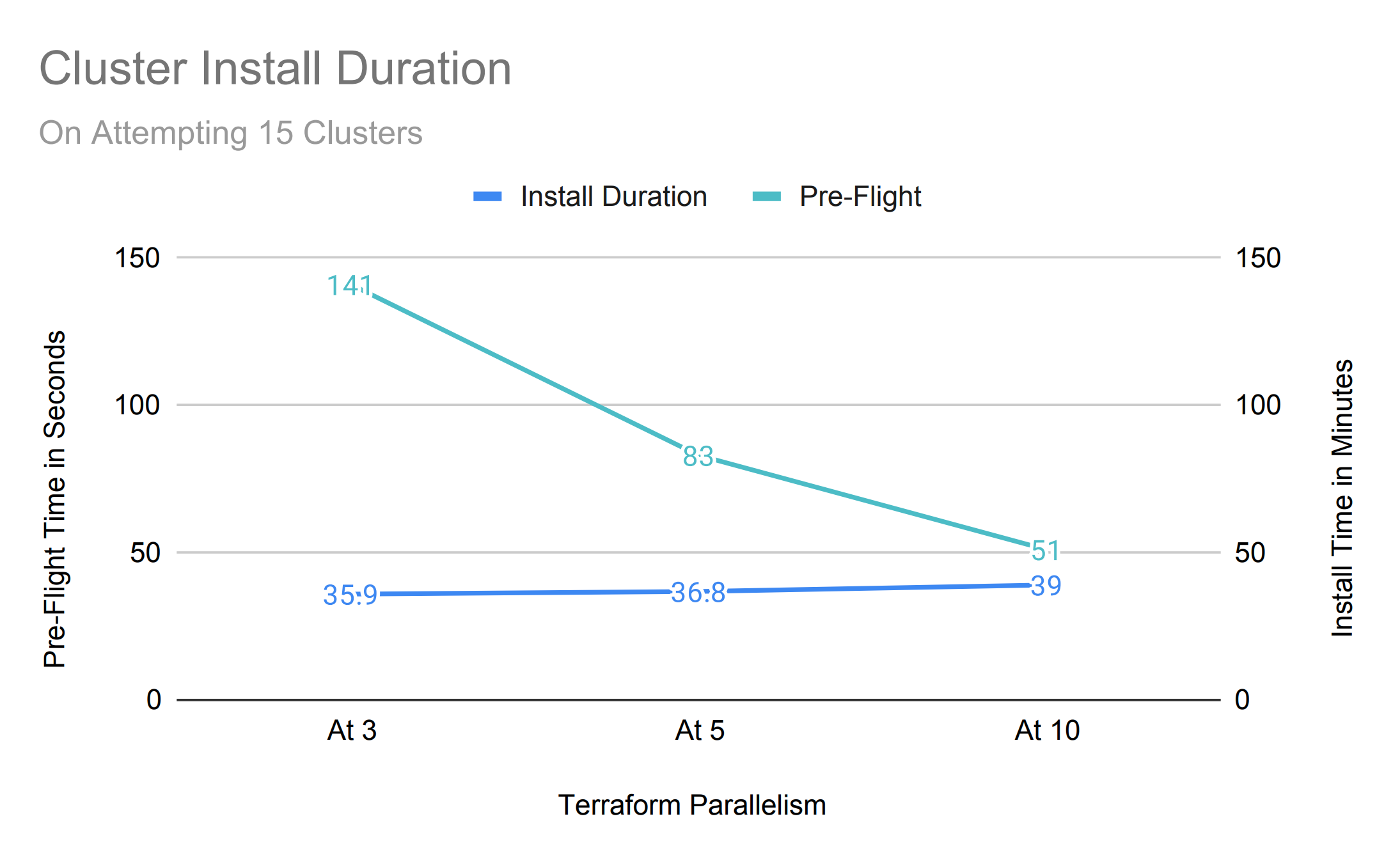
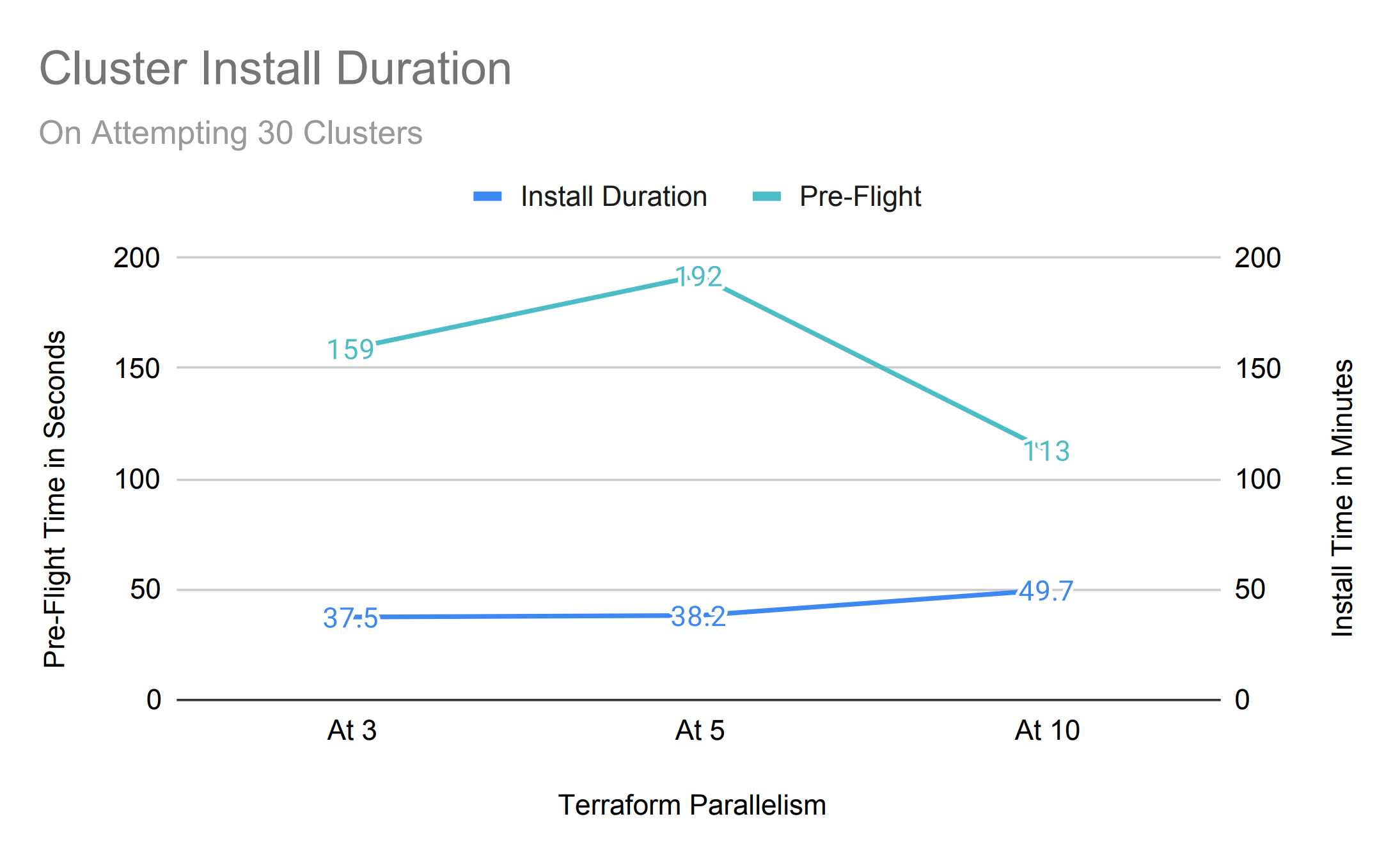
However, pre-flight duration is high with almost no benefit on increasing the concurrency when deploying a larger fleet of 50. This is a strong sign of hitting the API limits on the backend system that is processing them, it also aligns with our previous performance study on OCM and cloud API rate limits.
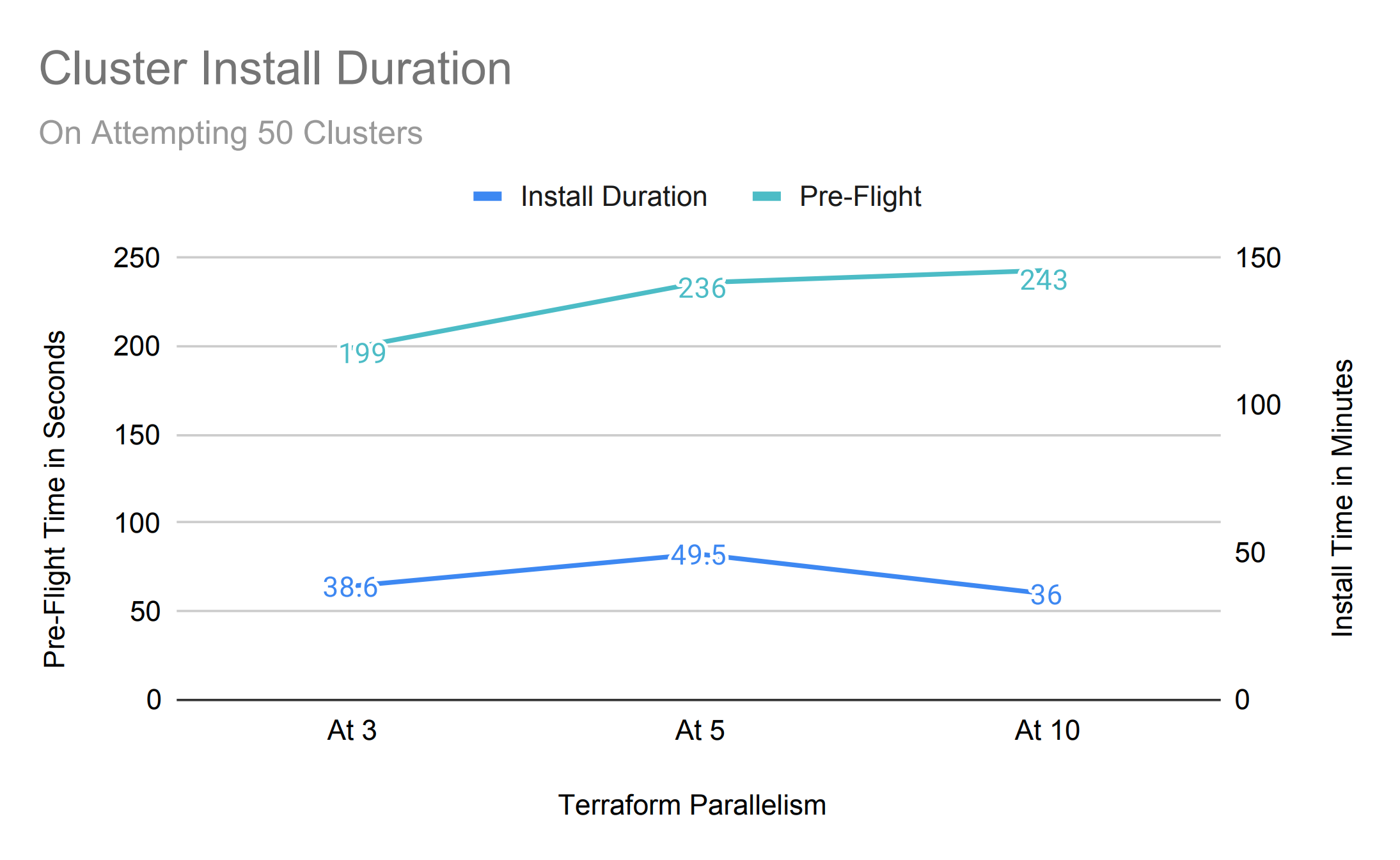
We recommended some improvements to the backend system so as to handle cloud limitations nicely and thereby reduce error rate,
- Changes to the internal OCM API calls in order to reduce the response time, tuning the API request during pre-flight and provisioning reduces the failure rate
- Reduced response size/time by picking the right resource type, in this case use vpc_id instead of hostedzone to validate AWS account resources
- Making use of AWS pagination or filters in API to speed up query when there is a lot of AWS resources
- When the existing cloud resource counts are higher, it is recommended to consider API pagination and handle response delay/timeouts
- Most importantly, any errors should be dealt with gracefully using a back off and retry to OCM.
Also, another recommendations to users to enable high inflight request rate by improving AWS API (per account) rate and throttle limits
- Possible in AWS to increase it per account, it would be performant with extended limits to handle such high rates.
Aggregating both KPIs into a single view, we can chart the correlation between concurrency, duration of installation and number of successful installations. Let's look at a single fleet with 30 clusters for simplicity,
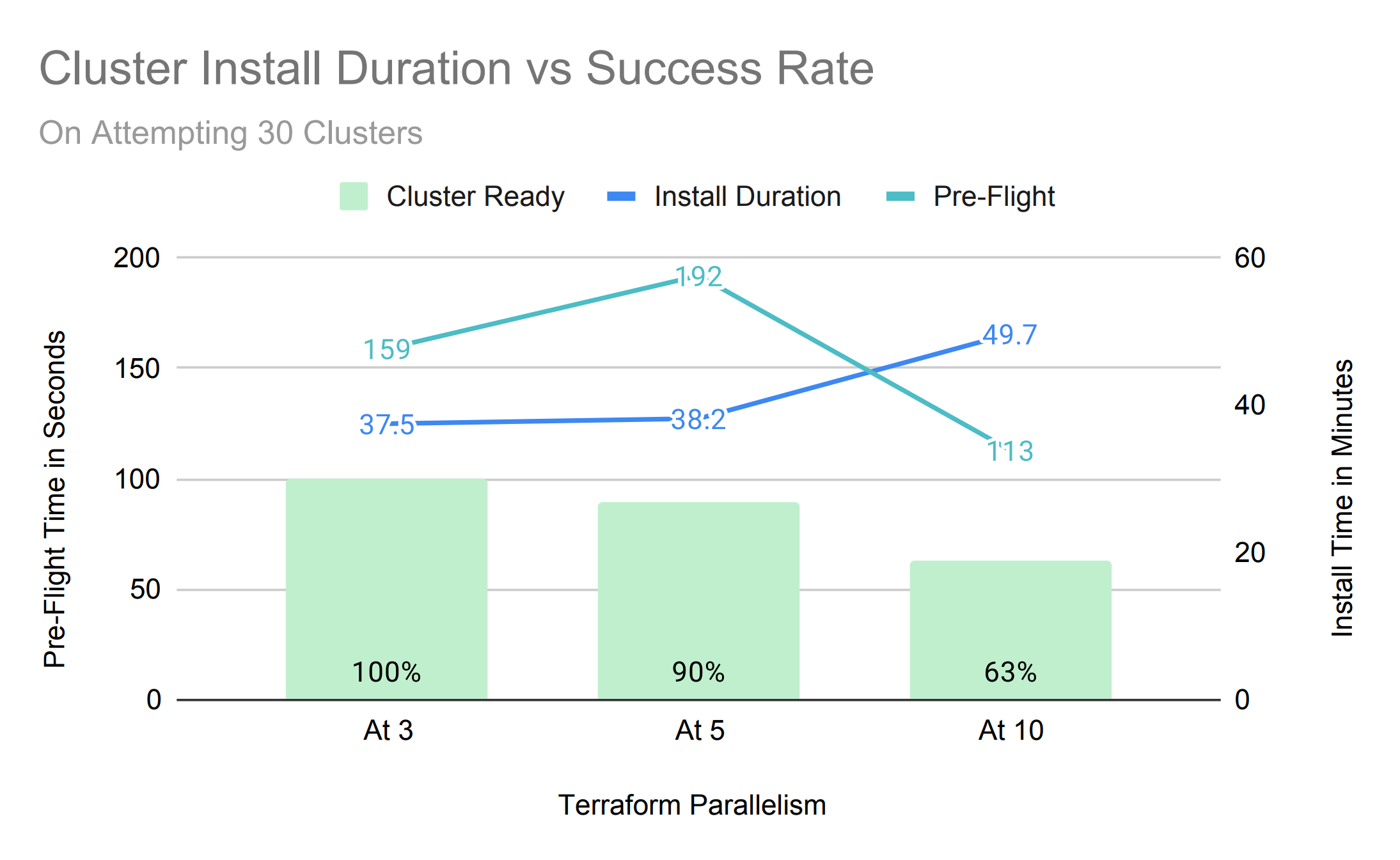
- Pre-flight duration as well as installation time is above average with lower(3) but very good at higher(10) parallelism
- 10% install failure at medium(5) parallelism was due to AWS response time out, due to too many AWS resources to fetch within expected timeout
- Installing multiple concurrent clusters also affects individual AWS resource standup time, in this case creating 30 clusters at a time(parallelism at 10) has slowed individual install processes.
Key Findings and Recommendations
- Running at parallelism of 3 gets consistent higher success rate as well as quicker cluster stand up time up to 50 clusters
- Installation of a fleet of more than 10 clusters is better handled by controlled and sequential deployment in chunks, for example parallelism set to 3 is best fit up to 50 clusters
- Installation duration is affected by various external factors as discussed in previous sections, but lower parallelism keeps it consistent if the fleet size more than 10
- API Tuning is required on the OCM side to handle the response time
- AWS throttling limits should be handled by backoff and retry mechanism on the OCM side
- Some of these things are improved on the served side already to backoff failed attempts
- Configuring higher AWS API rate and throttle limit on the user account would speed up the overall performance