Apicurio Registry is the upstream project for Red Hat Integration’s Service Registry component. Developers use Apicurio Registry to manage artifacts like API definitions and data structure schemas.
Apicurio Registry can maintain tons of artifacts, and it needs a way to store them. The registry supports several storage options, including Apache Kafka, Infinispan, and PostgreSQL. Knowing the performance characteristics of each storage option helps developers choose the appropriate storage for different use cases.
Recently, Red Hat's Performance & Scale team analyzed how Apicurio Registry performs under various storage configurations. In this article, we share the results of our performance and scalability testing on Apicurio Registry.
Note: See New features and storage options in Red Hat Integration Service Registry 1.1 GA for more about Red Hat Integration and the Service Registry component.
Overview of Apicurio Registry and the test setup
Apicurio Registry manages artifacts such as API definitions or data structure schemas like Apache Avro, which we used for these tests. As a developer, you can use API definitions and data structure schemas across your asynchronous messaging applications to validate the messages they're producing and consuming. Apicurio Registry helps you decouple the structure of your data from your applications.
Figure 1 shows a typical workflow with Apicurio Registry and Kafka.
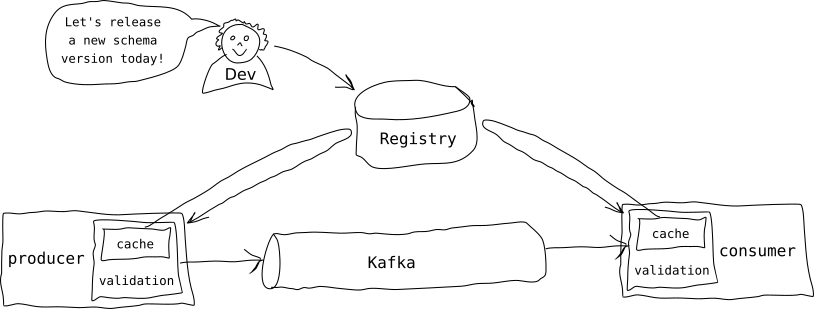
The most common operation within a schema registry is a simple GET request to its API to retrieve a given schema's latest version. Changing or updating the schema happens less frequently. As a result, the calls we used in our testing are fairly simple:
- List all of the artifacts:
GET <registry_host>/api/artifacts. (Note that there is no pagination. Usesearchif needed.) - Get the latest version of a schema:
GET <registry_host>/api/artifacts/<artifact_id>. - Create a new schema with JSON data:
POST <registry_host>/api/artifacts. - Add a new version of a schema with JSON data:
PUT <registry_host>/api/artifacts/<artifact_id>. - Delete a schema:
DELETE <registry_host>/api/artifacts/<artifact_id>.
Note: When using Apache Kafka to transfer Avro messages, the default Apicurio Registry client libraries don't load the Avro schema on every request. They only load schemas on application startup (or, for consumers, when a schema changes), so registry performance does not affect the speed of producing and consuming messages.
Performance testing Apicurio Registry
Our performance tests were basic, but each step contained multiple variants to catch various Apicurio Registry configurations:
- Clean up the registry database for a clean starting point.
- Populate the registry with a given number of schemas.
- Flood the registry with
GETrequests for the latest version using random schema from those created in the previous step.
How we tested
We used a Python script to generate a load of GETs to the registry, and we used Locust as our load testing tool. This setup might be overkill for our use case, where we're calling just one endpoint with a random schema ID, but it is a good test setup in general.
We use Locust as a library in our custom locust.py tool. Our custom tool has the added benefit of generating JSON files with the results and additional data that you can easily analyze later. Using Locust's default command-line interface tool would also work here.
Our deployment environment was Red Hat OpenShift 4 cluster running on Amazon Web Services Elastic Compute Cloud. We conducted some of our tests using an installation created by an Apicurio Registry Operator; other tests were conducted as custom deployment configurations for more control. Both the PostgreSQL database and load generation scripts could run in a pod in the same cluster. To monitor our pods, we used data from OpenShift’s Prometheus in the openshift-monitoring namespace.
Scaling the Locust script horizontally
Scaling the Locust script was one of the issues we had to solve during testing. When we raised the registry pod's CPU resources, we noticed an upper limit of about 925 requests per second. This indicated the application was scaling past two CPUs, which was unexpected. When we monitored the data, it didn't indicate that the resources were saturated on the registry or on the database, so we scaled the test script horizontally to distribute the load to more pods. When we scaled the script horizontally, we were able to generate many more requests.
Figure 2 shows the flow for scaling the Locust script horizontally.
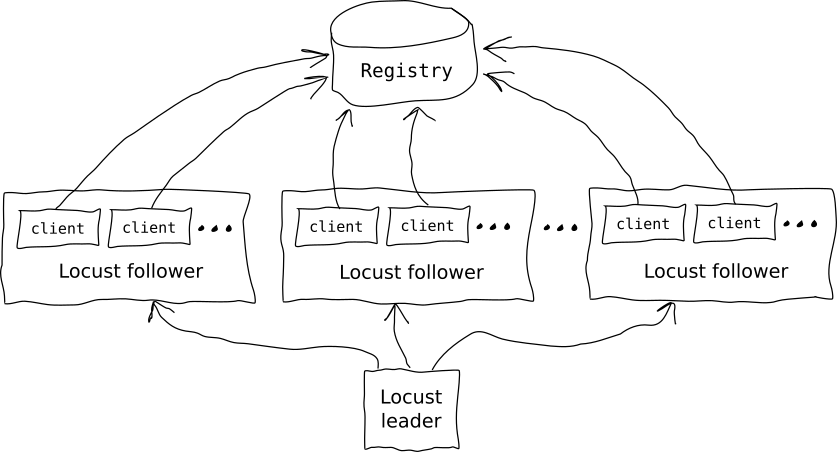
Figure 3 shows the requests per second (RPS) for different CPU resources with one Locust follower node.
 (PostgreSQL)")
Figure 4 shows the requests per second after scaling for 10 Locust follower nodes.
 (PostgreSQL)(1)")
Conclusion
We found the following results from testing Apicurio Registry's performance and scalability:
- Apicurio Registry works consistently and isn't affected by the number of artifacts it has in the database. We tested the registry with one million schemas, each with 10 versions and each version with 345 bytes of serialized JSON on average.
- Apicurio Registry's performance grows linearly as we allocate more CPU resources to it.
- Apicurio Registry's performance grows linearly as more registry pods are started. We tested 10 pods, which provided schemas at a rate of 4,201 requests per second.
We conclude that Apicurio Registry is capable of handling a wide range of deployments. We can always test more, but the current results show that Apicurio Registry with a PostgreSQL storage backend is a good option for future deployments.
Last updated: February 5, 2024