Red Hat Decision Manager helps organizations introduce the benefits of artificial intelligence to their daily operations. It is based on Drools, a popular open source project known for its powerful rules engine.
In Part 1 of this article, we built a machine learning algorithm and stored it in a Predictive Model Markup Language (PMML) file. In Part 2, we'll combine the machine learning logic with deterministic knowledge defined using a Decision Model and Notation (DMN) model. DMN is a recent standard introduced by the Object Management Group. It provides a common notation to capture an application's decision logic so that business users can understand it.
Note: Examples in this article build on the discussion in Part 1. If you have not already done so, please read the first half of this article before continuing.
The PMML advantage
The end goal of a machine learning algorithm is to predict a value given a certain input. As I discussed in Part 1, there are many different machine learning algorithms, and each one has its own structure, training options, and logical execution. Most of the time, end users don't need to know how an algorithm obtains its results; we only need to know that the results are accurate.
PMML hides the implementation details. It also gives us a common-language descriptor that we can use to combine predictive models created with different tools. The sklearn-pmml-model project integrates PMML with scikit-learn.
PMML also separates the machine learning domain from the knowledge engineering domain. This separation makes it easier for specialists to manage each domain's details, then use the common-language descriptor to integrate them.
JPMML
JPMML is a well established Java implementation of PMML provided by Openscoring.io. Drools and Red Hat Decision Manager use JPMML for PMML execution inside the same process that executes the DMN logic, making the whole execution extremely efficient.
Drools and JPMML are released with different open source licenses, and JPMML is not packaged with the Drools binaries nor with Red Hat Decision Manager. As a user, you will need to download the JPMML libraries and place them in the lib folder of the KIE Server and Business Central repository associated with your Red Hat Decision Manager instance.
Our example project's source code comes with a Maven configuration that copies all the project dependencies to the dependency folder. Here is the command to download the dependencies:
mvn dependency:copy-dependencies
You will need to copy the following libraries:
pmml-evaluator-1.4.9.jar pmml-agent-1.4.11.jar pmml-model-1.4.11.jar pmml-evaluator-extension-1.4.9.jar kie-dmn-jpmml-7.33.0.Final-redhat-00003.jar
The last entry is a Drools library that enables JPMML within the DMN runtime.
Using PMML and DMN with machine learning
The only drawback to using PMML is that it’s more focused on data science than machine learning. As a result, the specification doesn't include all of the available machine learning algorithms. You can still use DMN combined with machine learning, but it might be less comfortable in terms of user experience.
In fact, DMN can use externally-defined functions to execute Java code. This approach lets you leverage machine learning implementations that are not included with the specification, whether they are Java libraries or other technologies. It's even possible to call a remote evaluation that isolates the machine learning execution in a separate microservice.
Knowledge engineering meets machine learning
A machine learning algorithm delivers a prediction. How to handle the result is a decision, which is based on the knowledge context. The simple case study I introduced in Part 1 includes a reference price table for different product types. The table changes over time as prices are adjusted, and those changes influence the decision outcome.
Now, let's say that we want to introduce a business requirement that supply orders must be directed to a manager for any expense exceeding $1,500. The policy will let us know upfront what to do with larger expense requests, but how should we implement it?
We could train the algorithm to reject any order over $1,500, but that would be a bad choice. We shouldn't rely on a prediction when we have access to certainty. To say it differently, if you have a clear policy, use knowledge engineering, not machine learning.
The example project
To use PMML in a decision, we have to import it in Business Central (also known as Decision Central). The diagram in Figure 1 shows how the output from scikit-learn feeds into Red Hat Decision Manager and Decision Central.
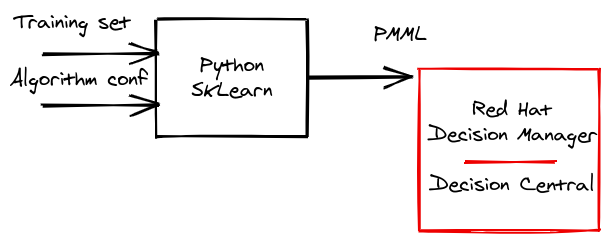
We can import the GitHub repository for this project directly into Decision Central: The PMML file is already imported, and the DMN file includes it by reference.
Note: If you need a quick introduction to DMN, see Learn DMN in 15 minutes.
The DMN logic
For this example, we've tried to keep the DMN logic minimal to focus on the PMML integration, but a few features are worth exploring. To start, consider the decision requirement diagram in Figure 2.

Figure 3 is a closer look at the OrderInfo datatype.

Notice the following:
- The input data categories are product type, price, category, and urgency.
- The Target Price is computed and used with the other data to get a Prediction.
- A Prediction triggers a machine learning call (ML call). The box with the clipped corner is the business knowledge model and represents the machine learning algorithm's execution.
- Finally, Auto Approve is based on the Prediction plus additional logic.
The Target Price decision shown in Figure 4 captures the company policy for asset reference prices with a simple decision table.

The Prediction decision node, shown in Figure 5, calls the machine learning execution (ML call). This node might seem complex. Really, it translates the category and urgency of a decision to numbers. The machine learning algorithm returns a prediction of true (probability(true)) when the probability is over the threshold of 0.5.

The business knowledge model
The project's business knowledge model is straightforward, as shown in Figure 6.

A user chooses the PMML document and model from a drop-down list. The PMML introspection automatically infers the input parameters.
Invoking the machine learning algorithm
From a decision expert's perspective, invoking a machine learning algorithm is simple: The information contract is defined by the PMML file and automatically imported. If a decision expert needs to understand a rule's semantics (for example, that “low” urgency translates to 0), they can speak to the data scientists.
For a slightly less obvious rule, consider how the model result is mapped in DMN. We can find those lines in the PMML file:
<Output> <OutputField name="probability(false)" optype="continuous" dataType="double" feature="probability" value="false"/> <OutputField name="probability(true)" optype="continuous" dataType="double" feature="probability" value="true"/> </Output>
They are translated in the following Friendly Enough Expression Language (FEEL) context:
{
“probability(true)” : number,
“probability(false)”: number
}
The top node is used to make the final decision of whether or not to auto-approve an order. Remember from Part 1 that this decision includes a simple company policy: Automatic approval can happen when the expense is less than $1,500. Here is how to implement that policy with a FEEL expression:
if order info.price < 1500 then Prediction else false
Figure 7 shows the decision lifecycle at a high level. Note that the design phase is split between Python and Decision Central. The runtime is the KIE Server (also known as Decision Central).

Trust automatic decisions
The more critical a decision is, the more you need to trust the system that determines its outcome. A suboptimal product suggestion might be acceptable, but what about a decision to reject a loan or decisions concerning medical findings? Additionally, ethics and legislation expect accountability in we use personal data is used to make decisions. (As an example, see the European Union's General Data Protection Regulation.)
Inspection
When an automatic decision-making system is introduced in an enterprise context, it is crucial to keep it under control by monitoring the decisions made over time. You should be able to use tools in your decision-management technology to investigate specific cases and highlight the features that influenced any given decision.
With Red Hat Decision Manager, users can use the common monitoring stack from Prometheus and Grafana to track decisions. By analyzing DMN execution results, you can inspect your intermediate outcomes and correlate them with the enterprise policy captured in a specific decision node.
Machine learning algorithms are more opaque: You get the input data and the output. In this sense, a machine learning model is a black box, providing no clues about how it works. An expert will understand from the algorithm parameters how it behaves, but most business users don't have access to that information.
Using the knowledge context
In our order approval example, the knowledge-based elements are key to understanding the final decision. If you can see that the price of a phone is far from the reference price in the model, you can use that information to interpret the decision outcome for your request. Our model is simple, so the conclusion is obvious. Surrounding a machine learning algorithm with a knowledge context is even more valuable for complex models. Having the context helps end users better understand decision outcomes.
Note: In the future, Red Hat Decision Manager's development team will extend its inspection features to better cope with the TrustyAI challenge.
Conclusion
In this two-part article, we have seen that artificial intelligence is more than just machine learning. By combining multiple techniques, we can increase the intelligence of a machine learning model. Moreover, this approach could increase an organization's overall confidence in machine learning outcomes. Business users and end users benefit from the transparency provided by a knowledge context.
We crafted a machine learning model for our example project, which we then consumed from a DMN model. The result was an "AI-augmented" decision. However, we only scratched the surface of what is possible with artificial intelligence. If you want to go further, I suggest this free course from Harvard University: CS50's Introduction to Artificial Intelligence with Python. The Python example we used in this article is based on a similar example from the course.
I also found the explainable AI (XAI) course on LinkedIn Learning (formerly Lynda) very useful.
Acknowledgments
A special thanks to my colleagues in the engineering team: Edson Tirelli, Matteo Mortari, and Gabriele Cardosi, for their suggestions and ideas to improve this article. Gabriele also wrote the "PMML advantage" section for this article.
Last updated: January 20, 2021