The supersonic subatomic Java singularity has expanded!
42 releases, 8 months of community participation, and 177 amazing contributors led up to the release of Quarkus 1.0. This release is a significant milestone with a lot of cool features behind it. You can read more in the release announcement.
Building on that awesome news, we want to delve into how Quarkus unifies both imperative and reactive programming models and its reactive core. We'll start with a brief history and then take a deep dive into what makes up this dual-faceted reactive core and how Java developers can take advantage of it.
Microservices, event-driven architectures, and serverless functions are on the rise. Creating a cloud-native architecture has become more accessible in the recent past; however, challenges remain, especially for Java developers. Serverless functions and microservices need faster startup times, consume less memory, and above all offer developer joy. Java, in that regard, has just in recent years done some improvements (e.g., ergonomics enhancements for containers, etc.). However, to have a performing container-native Java, it hasn't been easy. Let's first take a look at some of the inherent issues for developing container-native Java applications.
Let’s start with a bit of history.
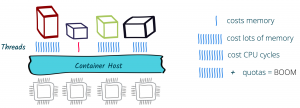
Threads and containers
As of version 8u131, Java is more container-aware, due to the ergonomics enhancements. So now, the JVM knows the number of cores it's running on and can customize thread pools accordingly — typically the fork/join pool. That's all great, but let's say we have a traditional web application that uses HTTP servlets or similar on Tomcat, Jetty, or the like. In effect, this application gives a thread to each request allowing it to block this thread when waiting for IO to occur, such as accessing databases, files, or other services. The sizing for such an application depends on the number of concurrent requests rather than the number of available cores; this also means quota or limits in Kubernetes on the number of cores will not be of great help and eventually will result in throttling.
Memory exhaustion
Threads also cost memory. Memory constraints inside a container do not necessarily help. Spreading that over multiple applications and threading to a large extent will cause more switching and, in some cases, performance degradation. Also, if an application uses traditional microservices frameworks, creates database connections, uses caching, and perhaps needs some more memory, then straightaway one would also need to look into the JVM memory management so that it’s not getting killed (e.g., XX:+UseCGroupMemoryLimitForHeap). Even though JVM can understand cgroups as of Java 9 and adapt memory accordingly, it can still get quite complex to manage and size the memory.
Quotas and limits
With Java 11, we now have the support for CPU quotas (e.g., PreferContainerQuotaForCPUCount). Kubernetes also provides support for limits and quotas. This could make sense; however, if the application uses more than the quota again, we end up with sizing based on cores, which in the case of traditional Java applications, using one thread per request, is not helpful at all.
Also, if we were to use quotas and limits or the scale-out feature of the underlying Kubernetes platform, the problem wouldn't solve itself; we would be throwing more capacity at the underlying issue or end up over-committing resources. And if we were running this on a high load in a public cloud, certainly we would end up using more resources than necessary.
What can solve this?
A straightforward solution to these problems would be to use asynchronous and non-blocking IO libraries and frameworks like Netty, Vert.x, or Akka. They are more useful in containers due to their reactive nature. By embracing non-blocking IO, the same thread can handle multiple concurrent requests. While a request processing is waiting for some IO, the thread is released and so can be used to handle another request. When the IO response required by the first request is finally received, processing of the first request can continue. Interleaving request processing using the same thread reduces the number of threads drastically and also resources to handle the load.
With non-blocking IO, the number of cores becomes the essential setting as it defines the number of IO threads you can run in parallel. Used properly, it efficient dispatches the load on the different cores, handling more with fewer resources.
Is that all?
And, there's more. Reactive programming improves resource usage but does not come for free. It requires that the application code embrace non-blocking and avoid blocking the IO thread. This is a different development and execution model. Although there are many libraries to help you do this, it's still a mind-shift.
First, you need to learn how to write code executed asynchronously because, as soon as you start using non-blocking IOs, you need to express what is going to happen once the response is received. You cannot wait and block anymore. To do this, you can pass callbacks, use reactive programming, or continuation. But, that's not all, you need to use non-blocking IOs and so have access to non-blocking servers and clients for everything you need. HTTP is the simple case, but think about database access, file systems, and so on.
Although end-to-end reactive provides the best efficiency, the shift can be hard to comprehend. Having the ability to mix both reactive and imperative code is becoming essential to:
- Use efficiently the resources on hot paths, and
- Provide a simpler code style for the rest of the application.
Enter Quarkus
This is what Quarkus is all about: unifying reactive and imperative in a single runtime.
Quarkus uses Vert.x and Netty at its core. And, it uses a bunch of reactive frameworks and extensions on top to help developers. Quarkus is not just for HTTP microservices, but also for event-driven architecture. Its reactive nature makes it very efficient when dealing with messages (e.g., Apache Kafka or AMQP).
The secret behind this is to use a single reactive engine for both imperative and reactive code.
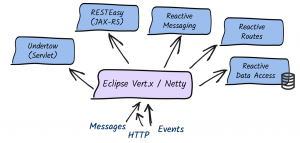
Quarkus does this quite brilliantly. Between imperative and reactive, the obvious choice is to have a reactive core. What that helps with is a fast non-blocking code that handles almost everything going via the event-loop thread (IO thread). But, if you were creating a typical REST application or a client-side application, Quarkus also gives you the imperative programming model. For example, Quarkus HTTP support is based on a non-blocking and reactive engine (Eclipse Vert.x and Netty). All the HTTP requests your application receive are handled by event loops (IO Thread) and then are routed towards the code that manages the request. Depending on the destination, it can invoke the code managing the request on a worker thread (servlet, Jax-RS) or use the IO was thread (reactive route).
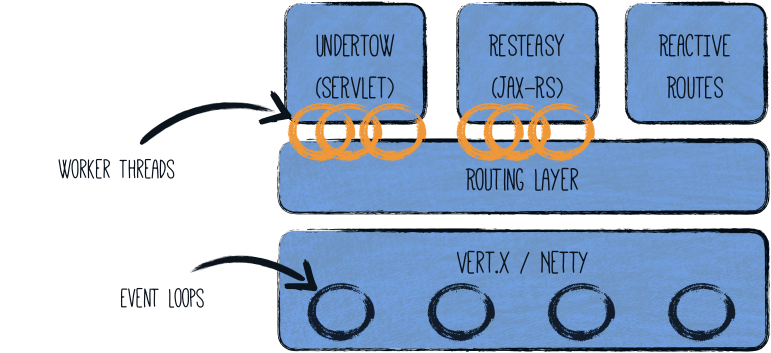
For messaging connectors, non-blocking clients are used and run on top of the Vert.x engine. So, you can efficiently send, receive, and process messages from various messaging middleware.
To help you get started with reactive on Quarkus, there are some well-articulated guides on Quarkus.io:
- Using Reactive Routes
- Reactive SQL Clients
- Using Apache Kafka with Reactive Messaging
- Using AMQP with Reactive Messaging
- Using Vertx API
There are also reactive demo scenarios that you can try online; you don't need a computer or an IDE, just give it a go in your browser. You can try them out here.
Additional resources
- Four reasons to try Quarkus
- Quarkus website: http://quarkus.io
- Quarkus GitHub project: https://github.com/quarkusio/quarkus
- Quarkus Twitter: https://twitter.com/QuarkusIO
- Quarkus chat: https://quarkusio.zulipchat.com/
- Quarkus mailing list: https://groups.google.com/forum/#!forum/quarkus-dev