This is a transcript of a session I gave at EMEA Red Hat Tech Exchange 2017, a gathering of all Red Hat solution architects and consultants across EMEA. It is about considerations and good practices when creating images that will run on OpenShift. This second part focuses on how you should structure images and group of images to achieve the objectives stated in part one.
Creating a Golden Image
To achieve a "golden image" the container image should be self-contained. No dependency (library, script) should be copied or downloaded at runtime. Application configuration needs, however, a closer look. It is important to differentiate between generic and environment specific configuration. All generic configurations should be put into the image and I would include under those things like database drivers, connection and thread pools parameters and connector types. This ensures that non-functional requirements are also addressed in a consistent way between environments. On the other hand, environment, the specific configuration should be set when a new container instance gets started. Examples of environment specific configuration items are endpoints (generally hostnames/IP addresses and port numbers) for databases, message brokers and other services the applications depend on, certificates and credentials. They may change between environments (integration and production for instance) and have them configurable is the only way to be able to promote the image from one environment to the other without changing it.
Kubernetes and OpenShift provide different ways of injecting environment specific information when the container starts up:
- Environment variables set in the deployment/deployment configuration.
- ConfigMaps that can be used as a source for environment variables or contain files that can be mounted into the container file system.
- Secrets, similar to configMaps but with security restrictions.
You need to plan their usage at design time and document what environment variables can be specified, where certificates should be mounted, etc. This needs to be reflected in the image documentation.
Defining an Image Hierarchy
Having a layered approach greatly facilitates image reuse and maintainability. Patching a parent image can automatically trigger a rebuild with the fix of the child images. Therefore, you can define an image change trigger in the build configuration. Have at least separate images for:
- Operating system
- Runtime libraries like JVM
- Application server is used
- Application
Additional intermediary images can be created for instrumentation or specifics of a standard operating environment.
Image hierarchies can simply be created by having the "FROM" in Dockerfile pointing to a parent image. OpenShift S2I process uses a builder image making S2I scripts available. The image created by the S2I process is a child of the builder image. As such, it can be automatically recreated when the builder image is patched.
Being in control of the image hierarchy is also an easy way to define what the company standard operating environments are. Application developers just have to reuse predefined parent images, i.e. standard environments for building their final application image.
Image Source
Not every structure is an inverted tree. You may have dependencies to libraries like drivers for connecting to databases or messaging brokers that may not fit in a simple hierarchy, as it would require the copy of these libraries in multiple images. The combinations may induce an explosion of the number of images. This would make the image landscape unmanageable. This pitfall can be avoided by using image sourcing. If image hierarchy were similar to class inheritance in object programming the match for image sourcing would be composition.
The libraries can then be kept in a central image and injected where required at build time. This provides a central point for patching and the cascade build mechanism applies.
In OpenShift this can be achieved by having something similar to the following in the build configuration:
images:
- from:
kind: ImageStreamTag
name: myinputimage:latest
namespace: mynamespace
paths:
- destinationDir: injected/dir
sourcePath: /usr/lib/somefile.jar
- from:
kind: ImageStreamTag
name: myotherinputimage:latest
namespace: myothernamespace
pullSecret: mysecret
paths:
- destinationDir: injected/dir
sourcePath: /usr/lib/somefile.jar
Further explanation can be found in OpenShift documentation.
On the docker side, it is possible starting with version 17.05 to use multistage builds to achieve the same. Note: docker 17.05 is not yet supported in OpenShift but you can just use image source if you build on it.
Chaining Builds
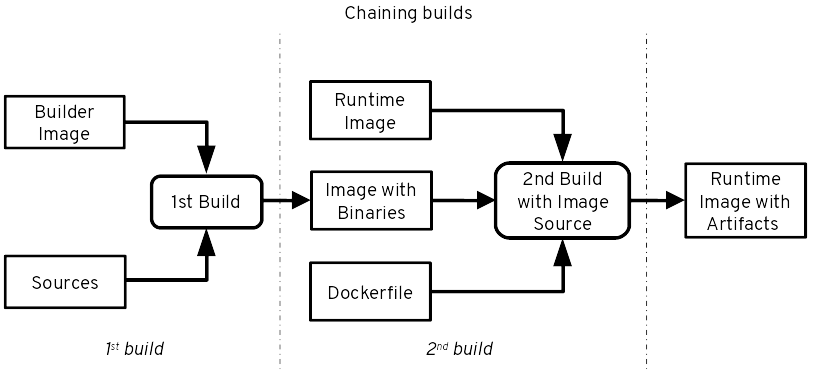
Chaining builds allows you to separate build and runtime images. The first build creates your application artifacts and may require build tools (maven, gradle), compilers (GCC, JDK) or credentials to access artifact repositories like Nexus or Artifactory for that. This is provided by the builder image and associated components. Your final application image is however generated by a second build based on a runtime-only image. This image may only have a JRE and no maven for instance. This reduces the attack surface, size of the final image and doesn't expose internal mechanisms. The second build can be done with a 2 line Dockerfile (FROM, COPY) or with an S2I assemble script doing a simple copy. This uses the image source approach described above to get the application artifacts into the final image. More information in OpenShift documentation.
Choosing a Distro

Choosing a Linux distribution is key for the support of the lifecycle of your images. With OpenShift, Red Hat provides support for RHEL but let look at a few considerations that drive this choice:
- The architecture: Bullet proven libraries, package format, and core utilities.
- Security: Creation of updates and patches, vulnerability detection and dashboard, security response team for addressing issues in a timely fashion.
- Performance: Tracking issues, automated tests and reactiveness to problems.
Other approaches are being developed with images based on light distros or even distro less. Mind with the former that in term of size the expensive part is RAM, not storage and that what matters for storage is the size on disk when you have pulled the dependencies required by your application and you have considered the layers that may be shared between containers running on the same host.
The distro less approach seems interesting as it drastically reduces the attack surface but two questions need to be addressed:
- How do you easily patch hundred+ images with a fix for a userspace library?
- How do you troubleshoot your container with little or no tooling available inside the image?
A very good article was written by Scott McCarty on this subject. I recommend its reading.
Build Types

There are different tools available for building your images.
You can use a docker daemon to create an image thanks to a Dockerfile where you specify instructions and thanks to a build context from where you can copy files. Here are characteristics of this type of build:
- Support for inheritance
- Batch like syntax
- Can be done on or off OpenShift.
- Flexible: you can become root and have full control of the image.
- Requires mounting the docker socket, which may be a security hazard for the host and other containers.
- Syntax complexity
This type of builds on OpenShift should only be done by trusted staff, which often means cluster administrators.
OpenShift S2I is on the other hand based on scripts provided by the builder image. Its characteristics are
- Simplicity: Only required to provide source location: a git repository or a local directory for instance.
- Configuration through an environment variable.
- Customization: Custom build and run scripts can be injected from the source repository.
- Security: No mount of docker socket required.
The flexibility docker build provides, makes it a good candidate for creating base images. OpenShift S2I thanks to its simplicity and security is, however, the best candidate for application image factories matching your SOE, where new builds are launched any time the application source code changes. You may have tenths of application builds reusing the same S2I builder image.
Other approaches for building container images are being developed that deserve to be mentioned. Ansible allows creating images in a way similar to the provisioning of a VM or a bare-metal server. It uses docker engine, Kubernetes or OpenShift under the hood. More information here.
Buildah is a tool designed after two important considerations:
- A container image is nothing more than a tar file and you should not require a runtime daemon for building an image. Image creation is then possible without any specific privileges.
- You can mount the root file system of your container for manipulation. A bonus is that you don't need any tooling inside the container you can use what is available at the host level.
More information here.
Base Images
As stated in the first part of this blog series you should give a thought on an image hierarchy. Combined with the image source approach it will give you a landscape easy to maintain where libraries are patched once. Using supplier images for Linux distribution or middleware products will allow the externalization of the lifecycle management of these components. For what is specific to your enterprise, the docker build strategy allows creating a shared/base image where your libraries or scripts can be added. But don't reinvent the wheel and use FROM in your Dockerfile.
Aligned with this strategy when libraries provided by upstream images need to be updated avoid yum update, contact the image maintainer instead. Another aspect is ensuring that subsequent builds produce the same result. Therefore, the docker context should be stable. Scripts and other files may be stored in a source versioning system like git. Curl or wget should only be used inside a Dockerfile to copy libraries from an artifact repository like Nexus or Artifactory.
Docker creates an image layer for each line in a Dockerfile. Chaining commands in a line group them in a single layer. Clean temporary files in the same line as you cannot remove them from a previous layer even if they are not visible in the final image. Mind the order of the instructions and put the most stable ones at the top. This will avoid cache invalidation and provides quicker builds (the layers before the change don't need to be rebuilt).
The approach of running an image, applying changes and storing the result as a new image is without further considerations not reproducible. For this reason, prefer Dockerfiles to using docker commit.
There are clear benefits of putting common libraries into a base image. The fact that it provides a central point for patching has already been mentioned. Here are other aspects:
- It makes the image bigger, hence slower to push/pull when the layers are not already present on the node.
- It speeds up assembly (S2I).
- The layer containing the libraries is shared among containers running on the same host.
Consider squashing. Squashing layers means:
- A smaller size and quicker to push and pull.
- It takes more time to rebuild (when first instructions haven’t changed).
- It may prevent sharing layers.
Having a user statement at the end makes clear, what the default user is when the image is run. Prefer UIDs rather than usernames as it is not visible with names whether they map to UID 0 (root). Note however that OpenShift will per default run for security reasons, containers with high user ids to make sure that they don't match users existing on the host.
Provide files and directories access through GID 0. The container user is always a member of the root group, hence can read and write these files. The root group does not have any special permission on the host.
Synchronize time zones. If you don’t synchronize you may have logs in different TZ on a host. There is an OpenShift RFE to mount /etc/local time inside the container.
Builder Images
Builder images are factories for easily creating application images that conform to the standard operating environment you have defined. OpenShift S2I is the best approach for this as it also limits the rights required by the user. To enable your builder image for S2I you just need a few scripts:
- assemble
- run
- save-artifacts
- usage
- test/run
It is not possible to cover all scenarios or configuration combinations of middleware products like application servers. Therefore, it is important when you design your builder image to create extension points where additional logic or components may easily be added without rewriting the layers you have created.
In a similar fashion, it is critical that environment specific configuration can be injected at runtime to support the creation of a golden image that can be promoted between environments. This needs to be foreseen in the builder image. Use environment variables and mount points for this purpose.
The Pre-population of local repositories (maven) used during builds can significantly quicken build processes. This is especially meaningful when it is combined with chained builds and runtime only images.
Companies may have invested in automated and integrated CI/CD pipelines and related infrastructure before the introduction of container technologies. It surely makes sense to use OpenShift capabilities for this purpose as it simplifies the maintenance and extends the possibilities of the pipelines but the migration may take time. Enabling external builds where application artifacts are created outside of OpenShift and only the container image inside allows rapid integration in existing processes. This can easily be done with a couple of lines in the assemble script.
Runtime Images
Besides the injection of environment specific configuration, the runtime image needs to take care of a few aspects.
The application process should receive signals sent by the orchestration platform like SIGTERM. If your application is started by a shell script, it means that "exec" should be combined with the start command.
Readiness and liveness probes allow the orchestration platform to know about the health of your application. Your runtime images can offer shell scripts, HTTP endpoints or TCP sockets that can be interrogated by OpenShift for this purpose.
As stated earlier chaining builds may help with limiting the attack surface. Init containers may also be used for running operations that require for instance special credentials before the application is started.
Your runtime container also needs to adapt to limited resources CPU/RAM available at the container level. Until Java 9, recently released, Java default configuration (heap, ForkJoinPool) was based on the host capacity, not taking cgroups settings in consideration. The cgroup files are mounted inside the container image and the information they provide can be used to configure sound values when the JVM gets started.
Containers in production should be run read-only as it provides better security and performance, especially when overlays are used. Volumes should be used for persistent data, emptyDir for temporary writes. Everything else should be read-only. Quotas can also be applied to emptyDir and volumes to control resources. Mkfifo can be used when containers inside a pod need to exchange information through the file system.
Avoid binding ports under 1024, as it requires special privileges.
Static Content
A network mount best provides static content when the size is significant. It can then be shared between container instances, which reduces the amount of storage consumed by it.
That said when the release process of the static content is bound to the application image and its size is small you may pack it in the image at build time and use image sourcing for code/content segregation. This is an easy way of having its release versioned and following a controlled process.
References
https://docs.openshift.com/container-platform/3.6/creating_images/guidelines.html
http://docs.projectatomic.io/container-best-practices/
https://docs.docker.com/engine/userguide/eng-image/dockerfile_best-practices/
Last updated: April 3, 2023