Red Hat JBoss Data Virtualization (JDV) provides several capabilities for caching data including: materialized views, result set caching, and code table caching. These techniques can be used to significantly improve performance in many situations.
With the exception of external materialized views, the cached data is accessed through the BufferManager. For better performance, the BufferManager setting should be adjusted to the memory constraints of your installation. See the Admin Guide for more on parameter tuning.
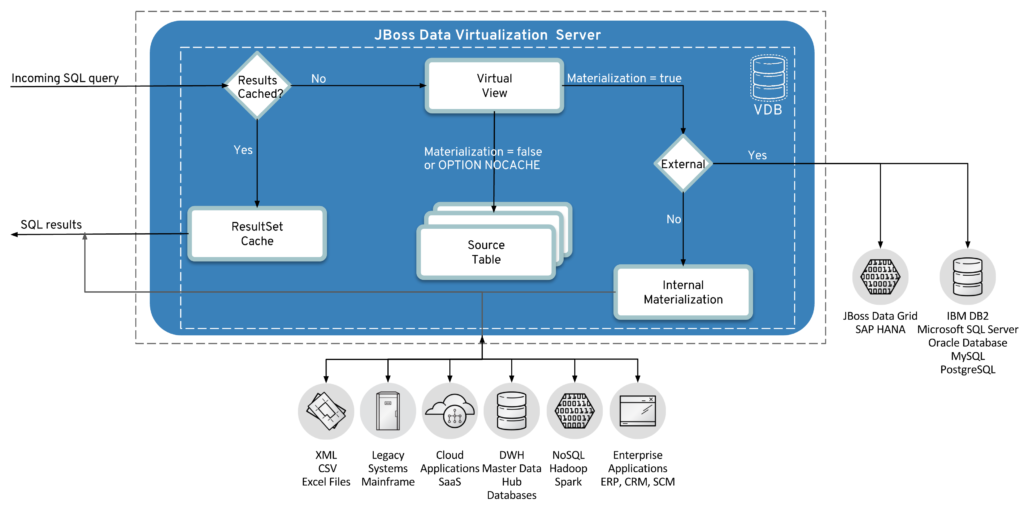
JDV supports two kinds of caching:
- Caching of final results of a user query, called result set caching.
JDV provides the capability to cache the results of specific user queries and virtual procedure calls. This caching technique can yield significant performance gains if users of the system submit the same queries or execute the same procedures often. User query result set caching will cache result sets based on an exact match of the incoming SQL string and PreparedStatement parameter values if present. Caching only applies to SELECT, set query, and stored procedure execution statements. Similar to materialized views, cached virtual procedure results are used automatically when a matching set of parameter values is detected for the same procedure execution. Usage of the cached results may be bypassed when used with the OPTION NOCACHE clause. - Caching contents of a virtual table, called "materialized views". The queries written using this virtual table are served from the cached contents instead from the original source. JDV supports:
- Internal materialized views
- External materialized views
Materialized views are just like other views, but their transformations are pre-computed and stored just like a regular table. When queries are issued against the views through the JDV Server, the cached results are used. This saves the cost of accessing all the underlying data sources and re-computing the view transformations each time a query is executed. Materialized views are appropriate when the underlying data does not change rapidly, or when it is acceptable to retrieve data that is "stale" within some period of time, or when it is preferred for end-user queries to access staged data rather than placing additional query load on operational sources.
Materialized views are defined in Teiid Designer by setting the materialized property on a table or view in a virtual (view) relational model. Setting this property's value to true (the default is false) allows the data generated for this virtual table to be treated as a materialized view.
The target materialized table may also be set in the properties. If the value is left blank, the default, then internal materialization will be used. JDV provides a shortcut to creating an internal materialized view table via the lookup function. The lookup function provides a way to accelerate getting a value out of a table when a key value is provided. The function automatically caches all of the key/return pairs for the referenced table. This code table caching is performed on demand, but will proactively load the results to other members in a cluster. Subsequent lookups against the same table using the same key and return columns will use the cached information. This code table caching solution is appropriate for integration of "reference data" with transactional or operational data. Reference data is usually static and small data sets that are used frequently. Examples are ISO country codes, state codes, and different types of financial instrument identifiers.
Otherwise, for external materialization, the value should reference the fully qualified name of a table (or possibly view) with the same columns as the materialized view. For most basic scenarios, the simplicity of internal materialization makes it the more appealing option.
In JDV, a view is a virtual table based on the computing (loading / transforming / federating) of a complex SQL statement across heterogeneous data sources. JDV external materialization process can cache the view data to external data source systems on a periodic basis. When a user issues queries against this view, the request will be redirected to this external data source system where cached results will be returned, rather than re-computing results from source systems. Materialization can prove to be time and resource saving if your view transformation is complex and/or access to the source systems is constrained.
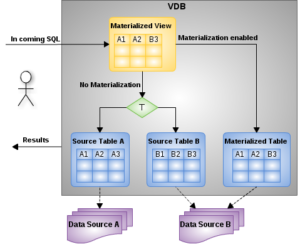
Reasons to use external materialization:
-
The cached data needs to be fully durable. Internal materialization does not survive a cluster restart.
-
Full control is needed of loading and refresh. Internal materialization does offer several system supported methods for refreshing, but does not give full access to the materialized table.
-
Control is needed over the materialized table definition. Internal materialization supports secondary indexes, but they cannot be directly controlled. Constraints or other database features cannot be added to internal materialization tables.
-
The data volume is large. Internal materialization (and temp tables in general) have memory overhead for each page. A rough guideline is that there can be 100 million rows in all materialized tables across all VDBs for every gigabyte of heap.
The following are the types of data sources that have been tested to work in the external materialization process:
- RDBMS - a relational database should work.
Example databases: MS SQL Server, MySQL, Oracle, PostgreSQL, SAP HANA, etc. - Red Hat JBoss Data Grid (JDG) - for in-memory caching of results.
In this article we'll describe how to use JDG for the external materialization process. The process of materializing data in JDG will require 3 caches defined in the JDG server. These caches are referred to in the JDV JDG HotRod connector as cache, staging cache and alias cache. The "cache" is general because, in the data source use case, there is only 1 cache needed. However, in the materialize use case, JDV will manage the cache mapping in the alias cache. The cache mapping, upon installation, will be set to:

When the materialize process is performed, it will first truncate the cache associated with "staging-cache" key. Then the data will be loaded into the "staging-cache". Once data is loaded, the process will swap the JDG Cache Names, updating the alias cache, resulting in:

Now subsequent queries will be retrieving the data from the primary cache, which is now pointing to the "staging-cache" cache name. This cycle of swapping the caches is a continual process as materialization is performed. If the server is shutdown and restarted, it will retrieve the latest mapping stored in the alias cache so that it maintains what was determined as the latest updated cache.
The following sections will describe how to configure a JDV view as a materialized view to load data into a JDG remote cache, via Hot Rod Client, and then access the cached data for improved query performance. See External Materialization for details on using external materialization.
Prerequisites
- JDV 6.3 environment
Download: https://developers.redhat.com/products/datavirt/overview
Install: https://developers.redhat.com/products/datavirt/hello-world/#_install-configure-jboss-data-virtualization
We will refer to the installation directory of JDV 6.3 as $JDV_HOME. - JDV 6.3.4 patch
Download: JBoss Data Virtualization Update 04
Install:$ java -jar binaries/jboss-dv-6.3.4-patch.jar --server {{ JDV_HOME }} --update jboss-dv - JDG 6.6.0 environment
Download: Red Hat JBoss Data Grid 6.6.0 Server
Install: https://developers.redhat.com/products/datagrid/overview
We will refer to the installation directory of JDG 6.6.0 as $JDG_HOME. - JDG 6.6.1 patch
Download: Red Hat JBoss Data Grid 6.6.1 Server Update
Install:$ cd $JDG_HOME/bin $ ./standalone.sh $ ./cli.sh --connect [standalone@localhost:9999 /] patch apply jboss-datagrid-6.6.1-server-patch.zip
- JDG 6.6.1 Hot Rod Java Client Module for JBoss EAP
Download: Red Hat JBoss Data Grid 6.6.1 Hot Rod Java Client Module for JBoss EAP
Install:$ unzip jboss-datagrid-6.6.1-eap-modules-remote-java-client.zip $ cd jboss-datagrid-6.6.1-eap-modules-remote-java-client $ cp -R modules/ $JDV_HOME
Note: If installing JDG 6.6, one needs to install the JDG 6.6.1 patch that upgrades the infinispan module:
org.infinispan.protostream to protostream-3.0.5.Final.jar - Red Hat JBoss Developer Studio (JBDS) 10.3.0 with JBoss Data Virtualization Development installed
Download: https://developers.redhat.com/download-manager/file/devstudio-10.3.0.GA-installer-eap.jar
Install: https://developers.redhat.com/products/datavirt/hello-world/#_set-up-dev-environment
What are we going to create?
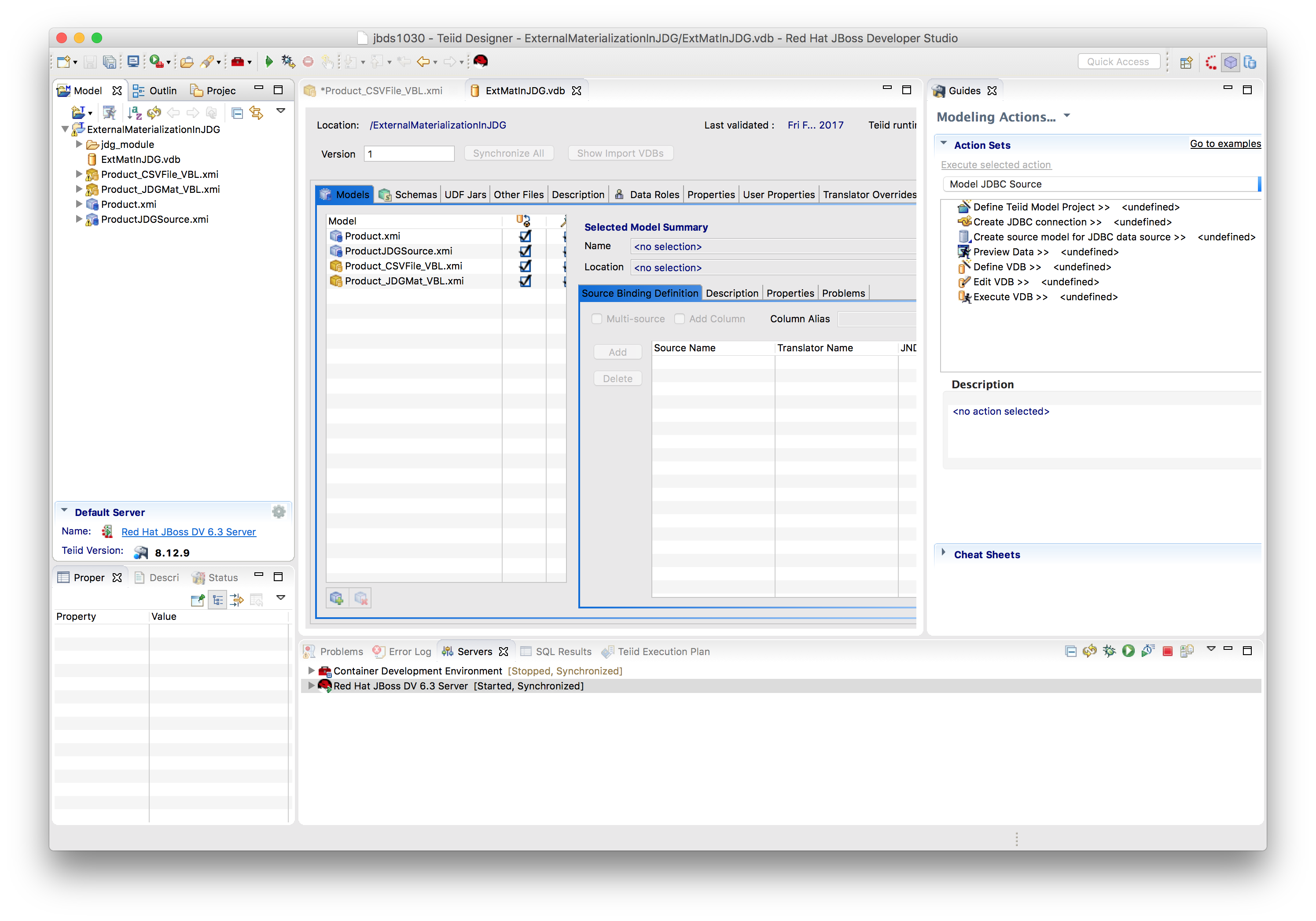
We are going to create a virtual database (or VDB) called ExtMatInJDG, which is a metadata container for components used to integrate data from multiple data sources so that they can be accessed in an integrated manner through a single, uniform API. The image depicted below will be the end result.
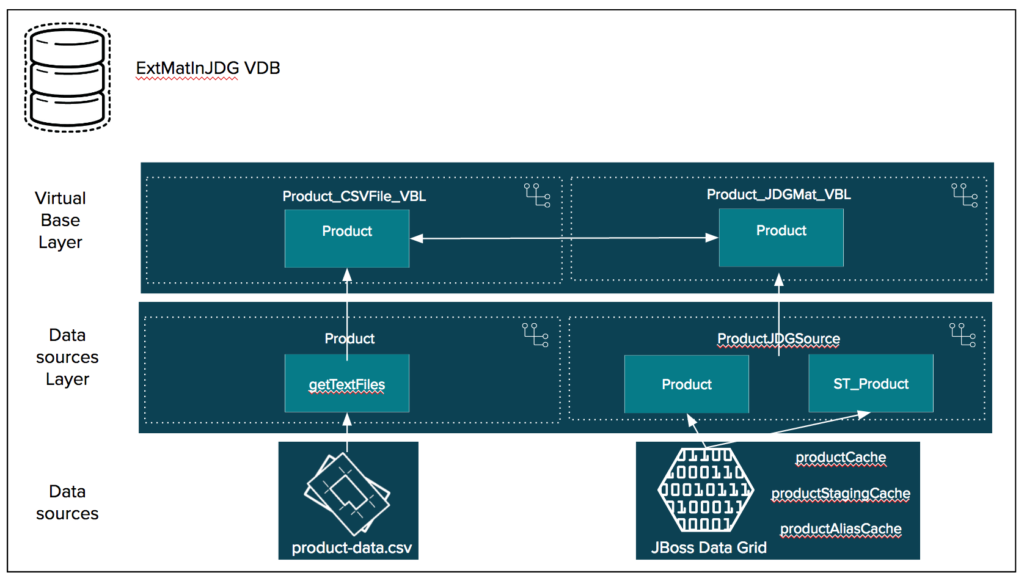
A VDB typically contains multiple schema components (also called as models), and each schema contains the metadata (tables, procedures, functions). There are two (2) different types of schemas.
-
Source Schema (also called Physical or Foreign schema) as part of the Data source layer, which represents an external/remote data sources like in our case JBoss Data Grid, CSV Files etc. As depicted in the image above we have two source schemas Product and ProductJDGSource.
-
Virtual Schema as part of the Virtual Base Layer. This is a view layer or logical schema layer, which is defined using schema elements from source schemas. For example, creating a view table using multiple foreign tables from different sources, thus hiding the complexities of the definition of the view from the user. As depicted in the image above we have two virtual schemas called Product_CSVFile_VBL (reading product data from a CSV file) and Product_JDGMat_VBL (used for external materialization in JBoss Data Grid).
One important thing to note is, a VDB only contains metadata, never copies/has the actual data.
Design flow
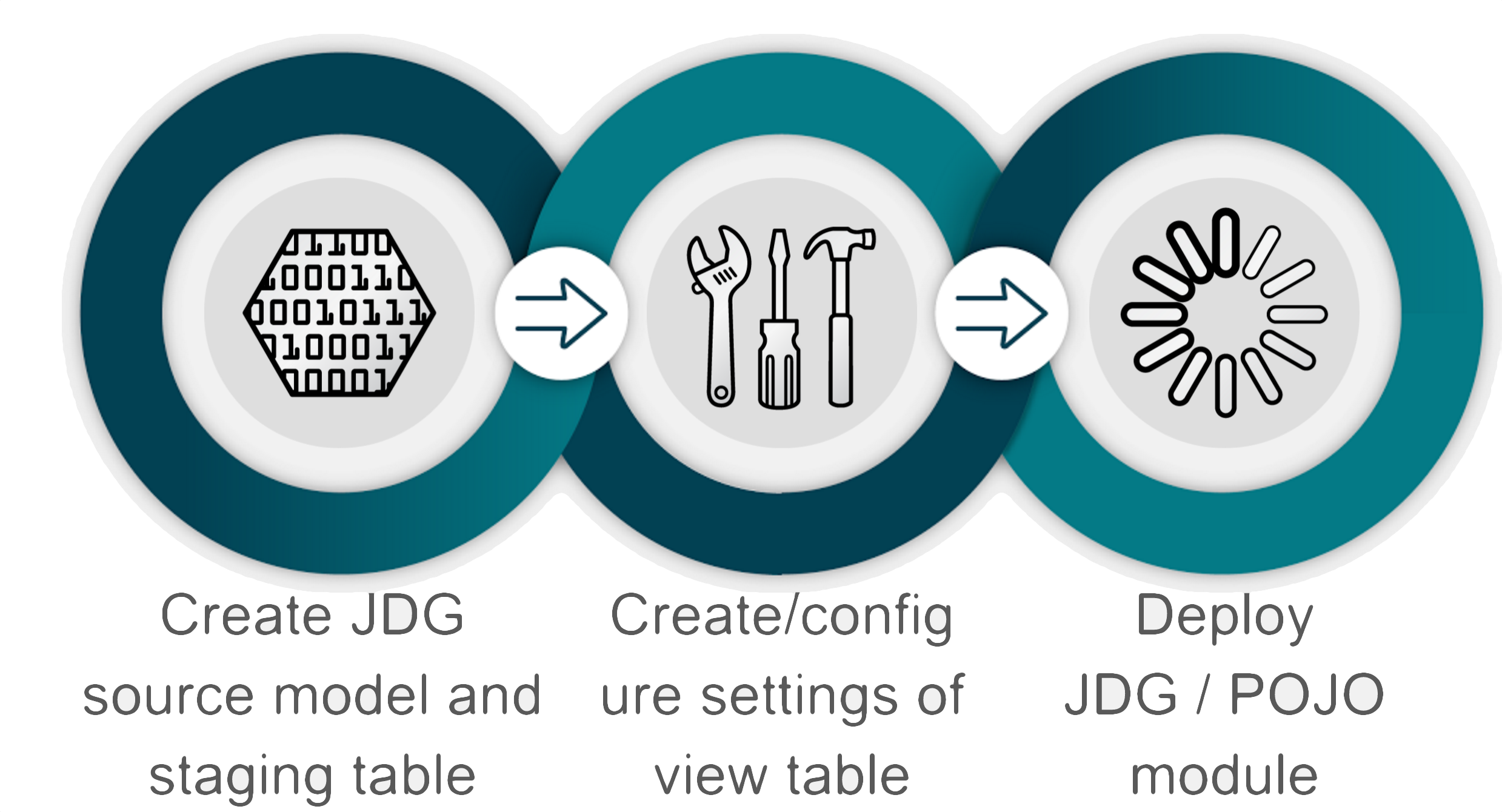
The following will describe the steps using Teiid Designer to create the artifacts needed to materialize a view into JDG.
From a Teiid Designer perspective, a user will have views they wish to materialize and access via a JDG instance to return cached data rather than repeatedly access the data from the actual data source. The steps below expect that model Product_CSVFile_VBL, which reads data from the product-data.csv already exists in your modeling project.
The general workflow is as follows:
- Generate JDG source model and staging table
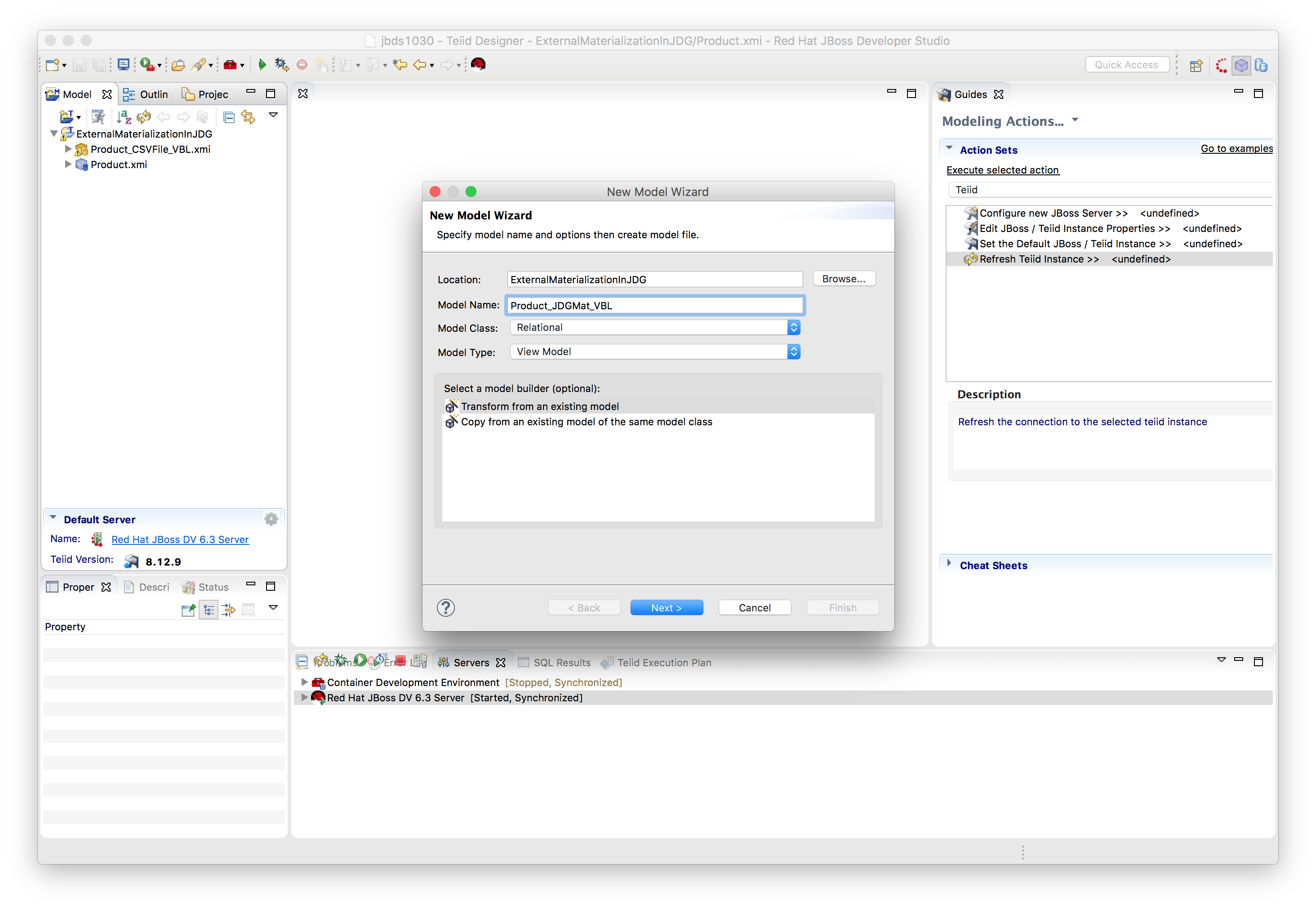
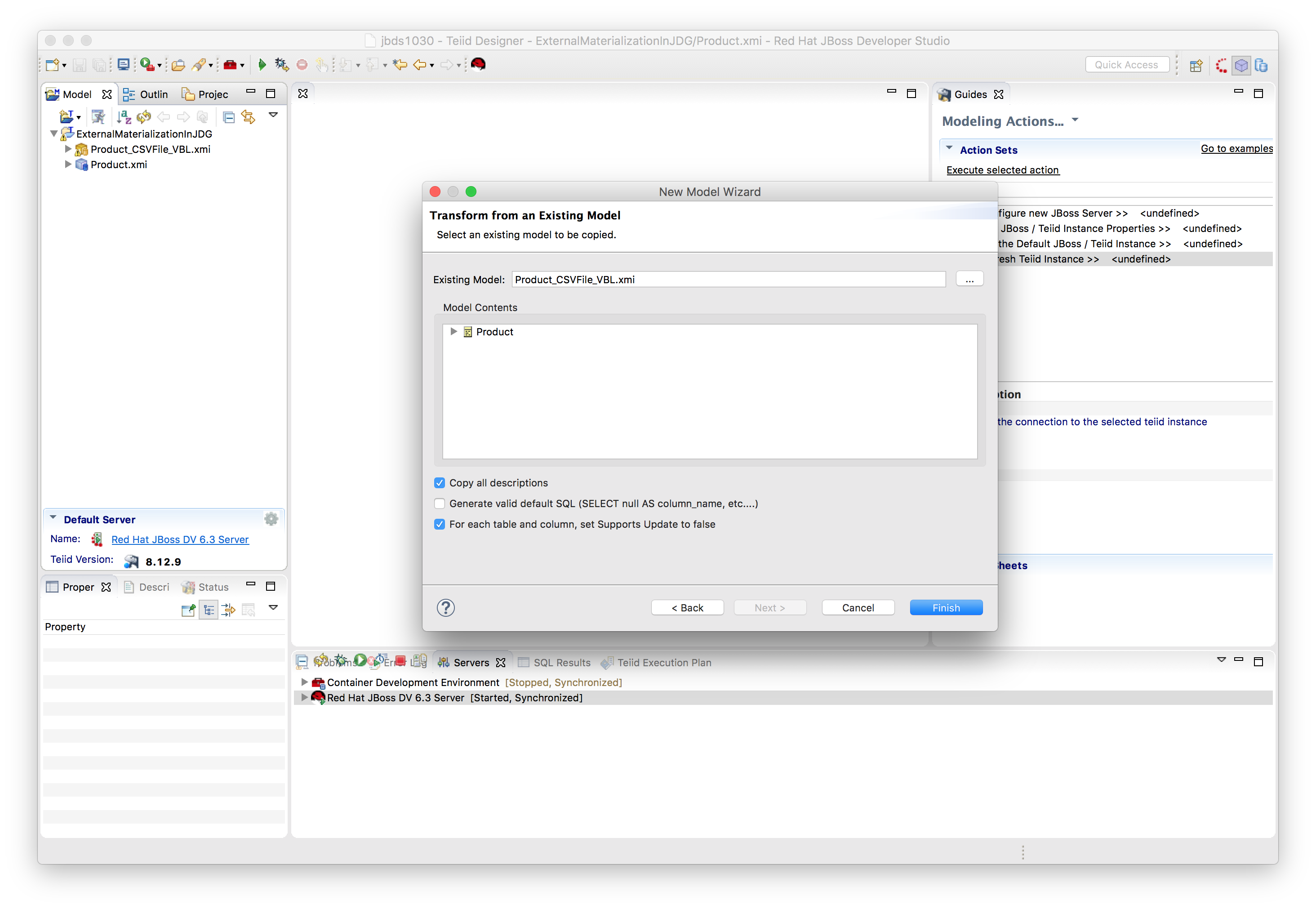
Create View, which will be materialized. In our case,,,,,,, we are creating a new view called Product_JDGMat_VBL , which will be creating based on the Product_CSVFile_VBL model. File → New → Teiid Metadata Model. Name the model i.e. Product_JDGMat_VBL and select View Model for Model Type and select option Transform from existing model i.e. Product_CSVFile_VBL user schema with model products.
Click Next.
Click Finish.
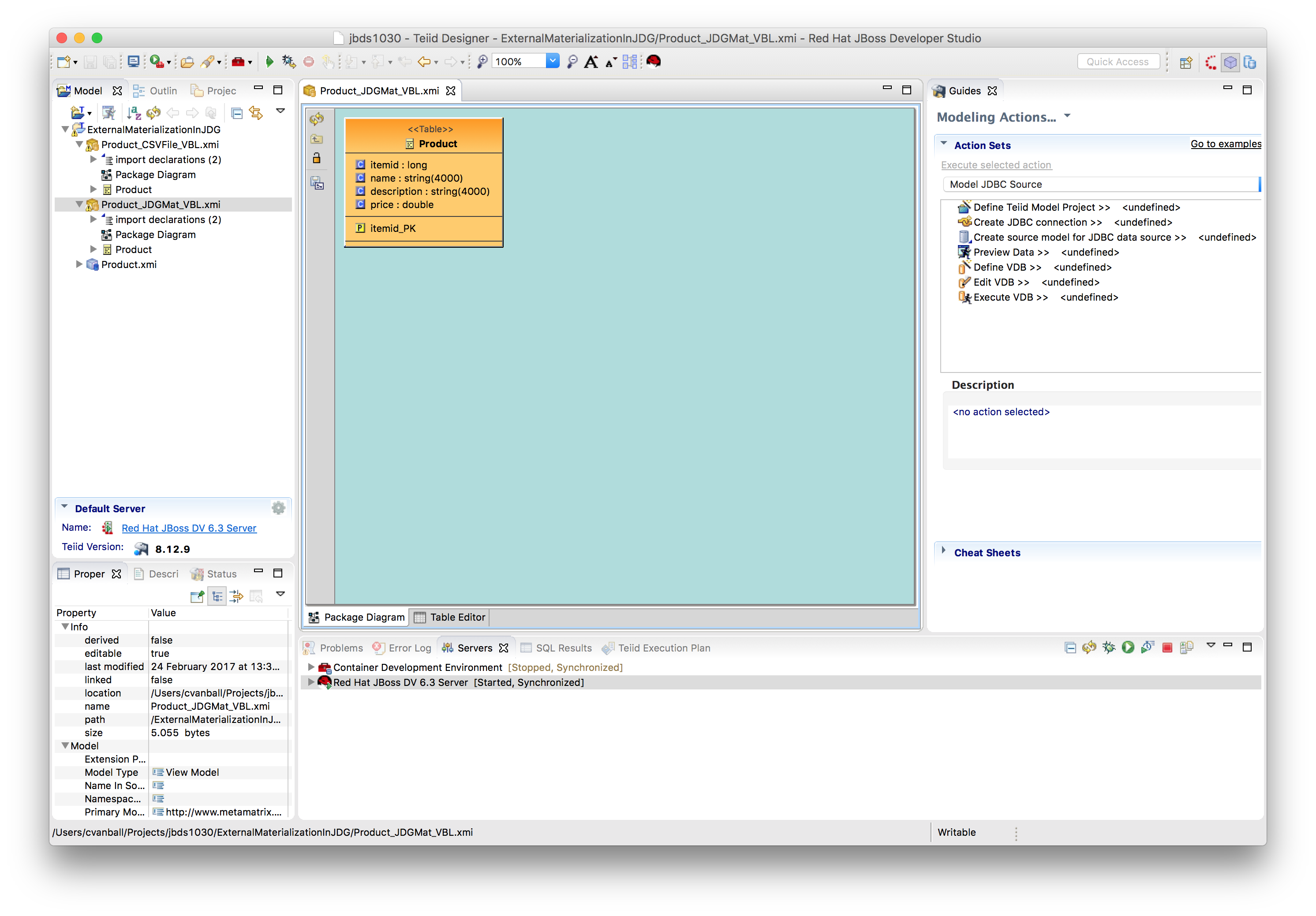
Consider adding the primary key to the View, which will be used as the primary key on the newly created materialized tables. Why is it better to add the primary key on the view?
The primary key will then be created on the newly created materialized tables. If the view is changed, the materialized process needs to be rerun in order to propagate the changes to the POJO and materialized tables. If the primary key was not done in the view, then the materialized tables will have to be manually updated again. Only simple POJO's are supported for materialization. Use native data types for the view columns. - Create/configure materialized view model
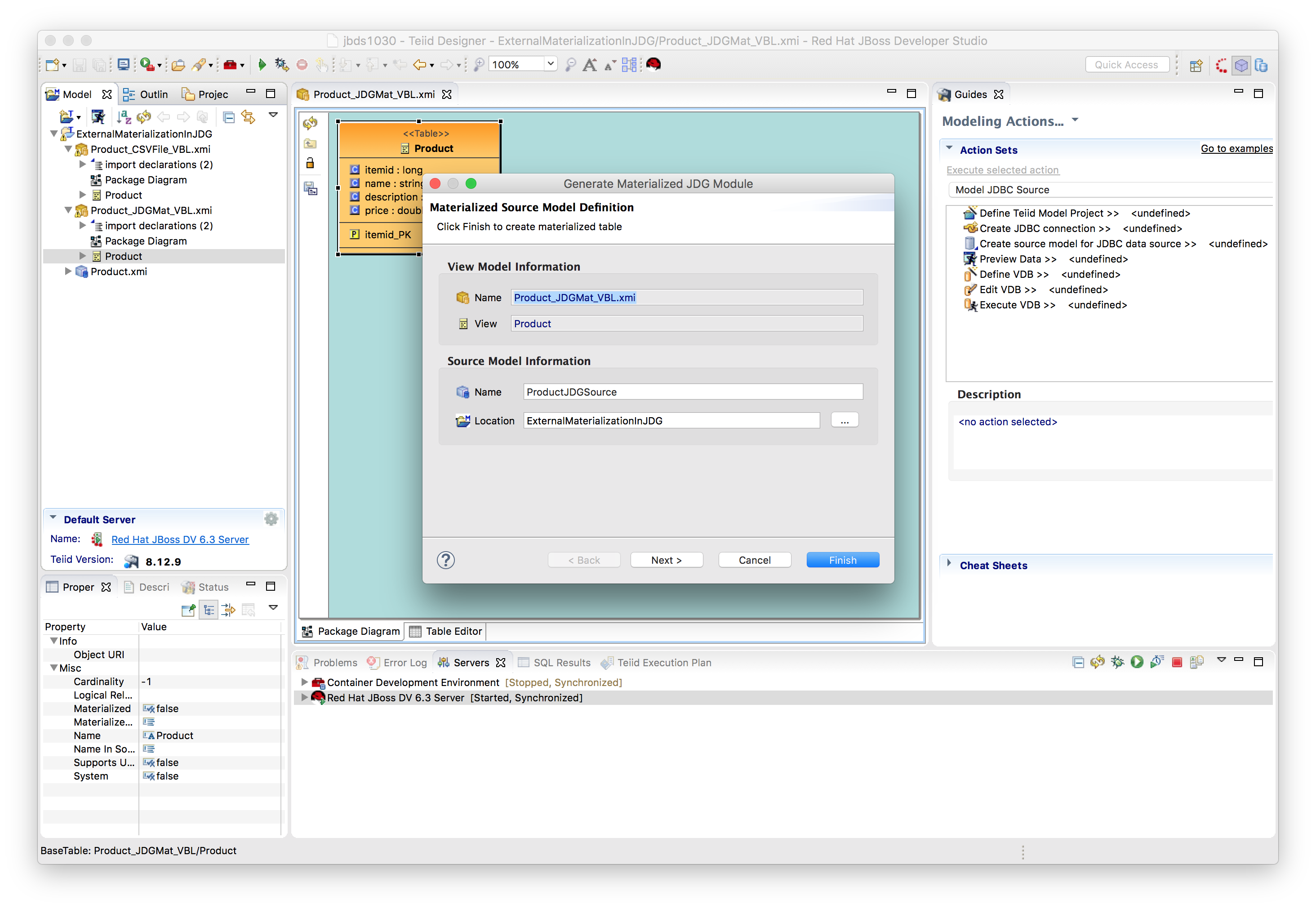
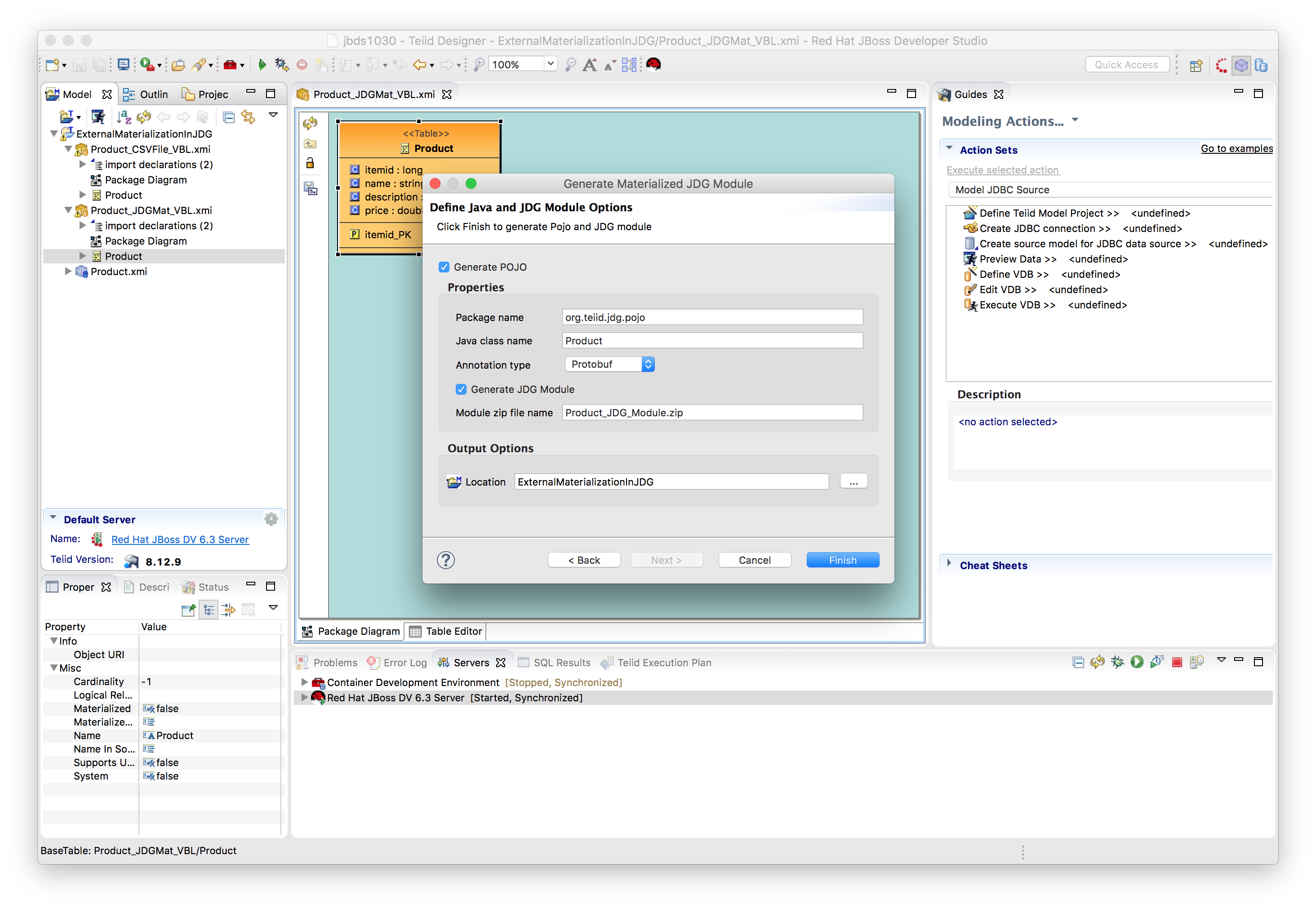
Right click on selected view i.e. Product_JDGMat_VBL Product, select Modeling → Materialize option to Generate JDG Source Tables, POJO and Module Zip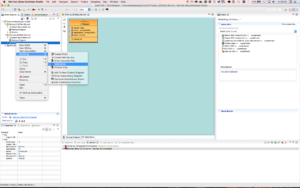
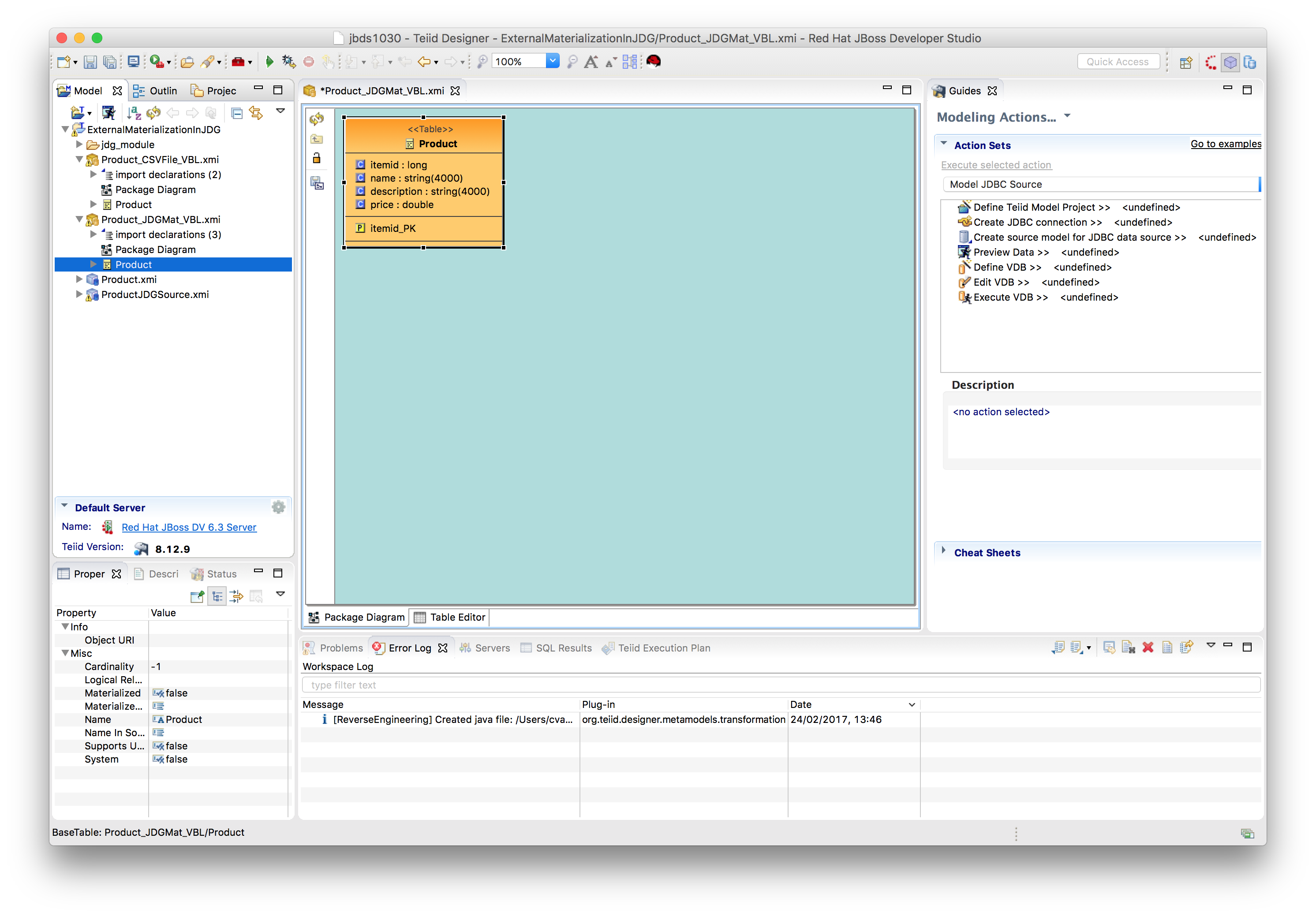
- Creates the JDG source model productsJDGSource and staging table (i.e, prefixed with ST_ by default)
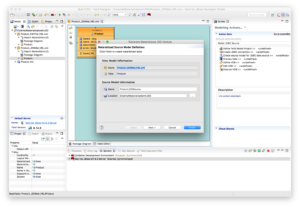
Press Next. - Creates POJO from selected relational table and columns
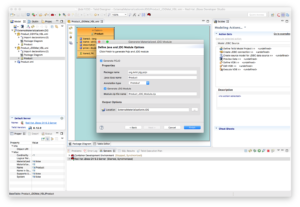
Click Finish, to generate the JDG module and JDG source model.
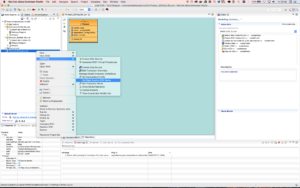
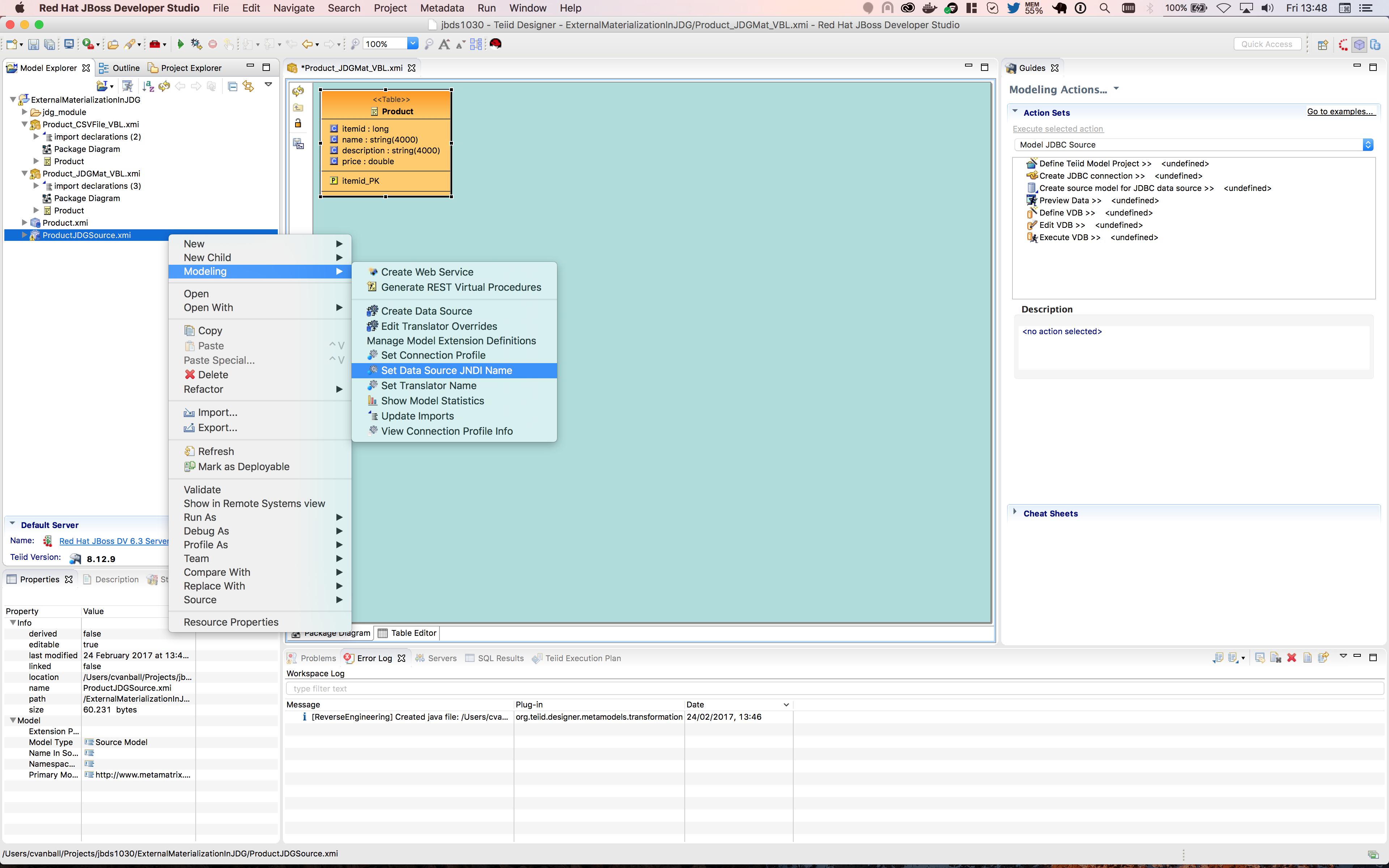
Note: make sure that the translator name is set correctly to infinispan-cache-dsl and data source JNDI name set correctly to productDS on the generated JDG source model i.e. ProductJDGSource by using
Modeling → Set Translator Name and use infinispan-cache-dsl as the value
Modeling → Set Data Source JNDI Name and use productDS as the value as depicted in the image below.
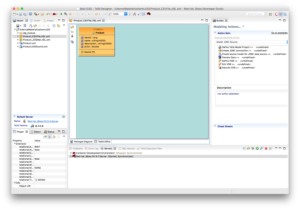
After performing the materialization wizard, you can update the view materialize extension properties- Set relational: Time To Live (ms) time to indicate the frequency of the refresh to be performed. I.e. 60000 (= 60 seconds)
- Consider enabling being been management controlled and set the status table.
- See View Extension Properties for all the possible options for configuring the view options.
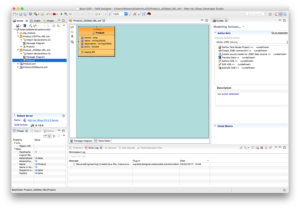
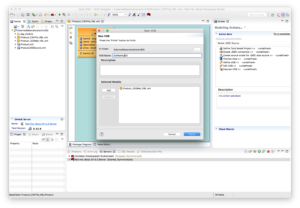
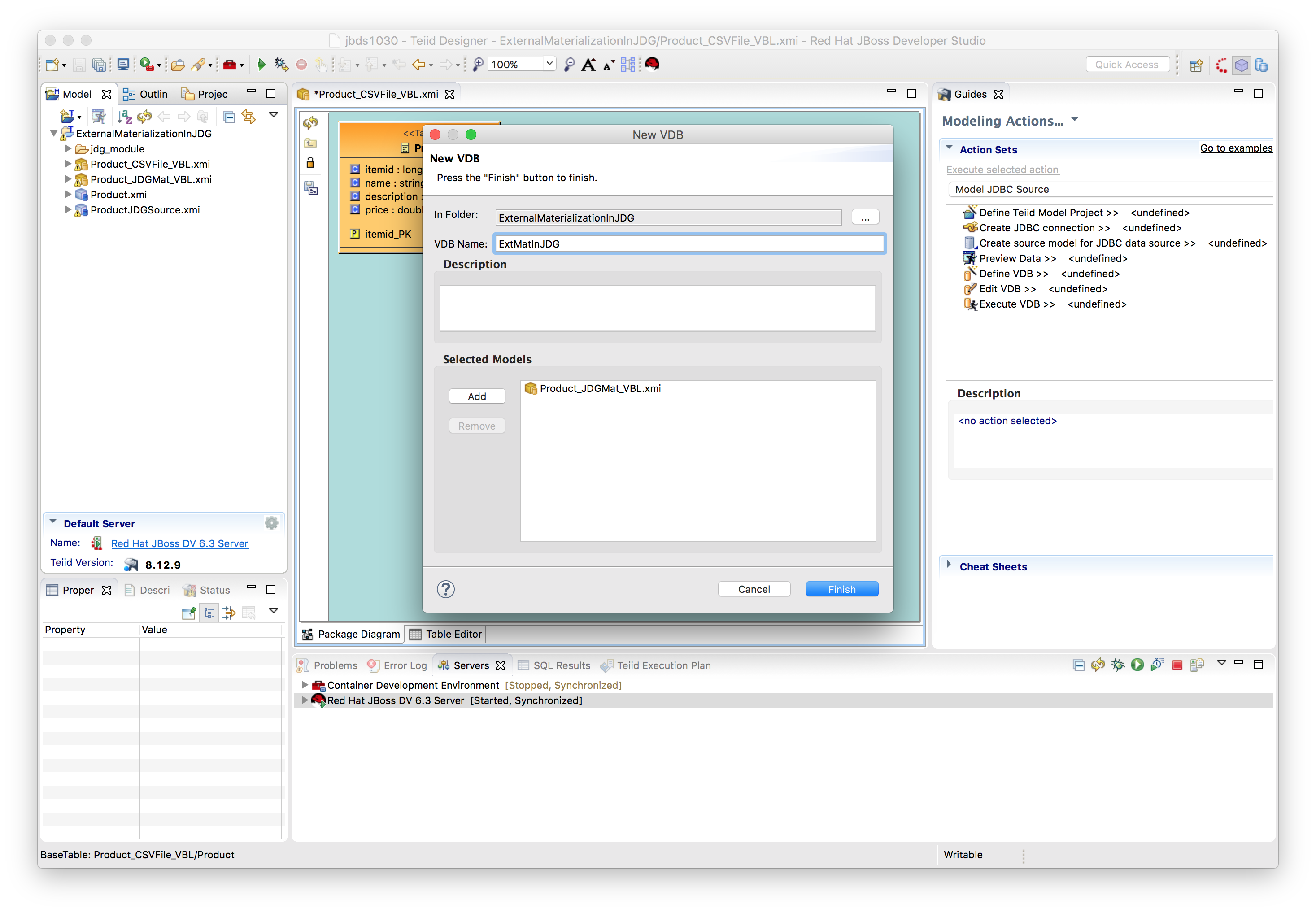
Create a VDB called ExtMatInJDG by using File → New → Teiid VDB and add the model Product_JDGMat_VBL to the VDB as depicted below.
Click Finish.
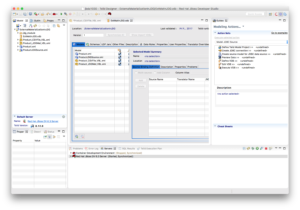
- Creates the JDG source model productsJDGSource and staging table (i.e, prefixed with ST_ by default)
- Deploy POJO zip
Deploy POJO module to the server by unzipping at the root directory of the JDV server installation.
If using POJO annotations which we do, edit the module.xml for org.jboss.teiid.resource-adapter.infinispan.dsl resource adapter to add the POJO module dependency Location: /modules/system/layers/dv/org/jboss/teiid/resource-adapter/infinispan/dsl/main/module.xml- Deploy POJO module to the server by unzipping at the root directory of the Teiid server installation.
- If using POJO annotations as we do, one need to edit the module.xml for org.jboss.teiid.resource-adapter.infinispan.dsl resource adapter to add the POJO module dependency Location: /modules/system/layers/dv/org/jboss/teiid/resource-adapter/infinispan/dsl/main/module.xml


Steps to show case external materialization to JDG
-
- Start your local JDG 6.6.1 environment.
$ cd $JDG_HOME/bin $ ./standalone.sh -Djboss.socket.binding.port-offset=100
Note: We are using port-offset 100 to run JDG on a different port otherwise JDG and JDV will be running on the same port.
- Start your local JDV 6.3 environment.
$ cd $JDV_HOME/bin $ ./standalone.sh
- Start your local JDG 6.6.1 environment.
To test the external materialization we need to deploy the ExtMatInJDG VDB first and add some product data to the productCache in JDG first, see also previous blog article Unlock your Red Hat JBoss Data Grid data with Red Hat JBoss Data Virtualization. Once we have some data in the cache we can start retrieving query results as shown below.
Retrieve data from source table i.e.
SQL> select * from Product_CSVFile_VBL.Product;
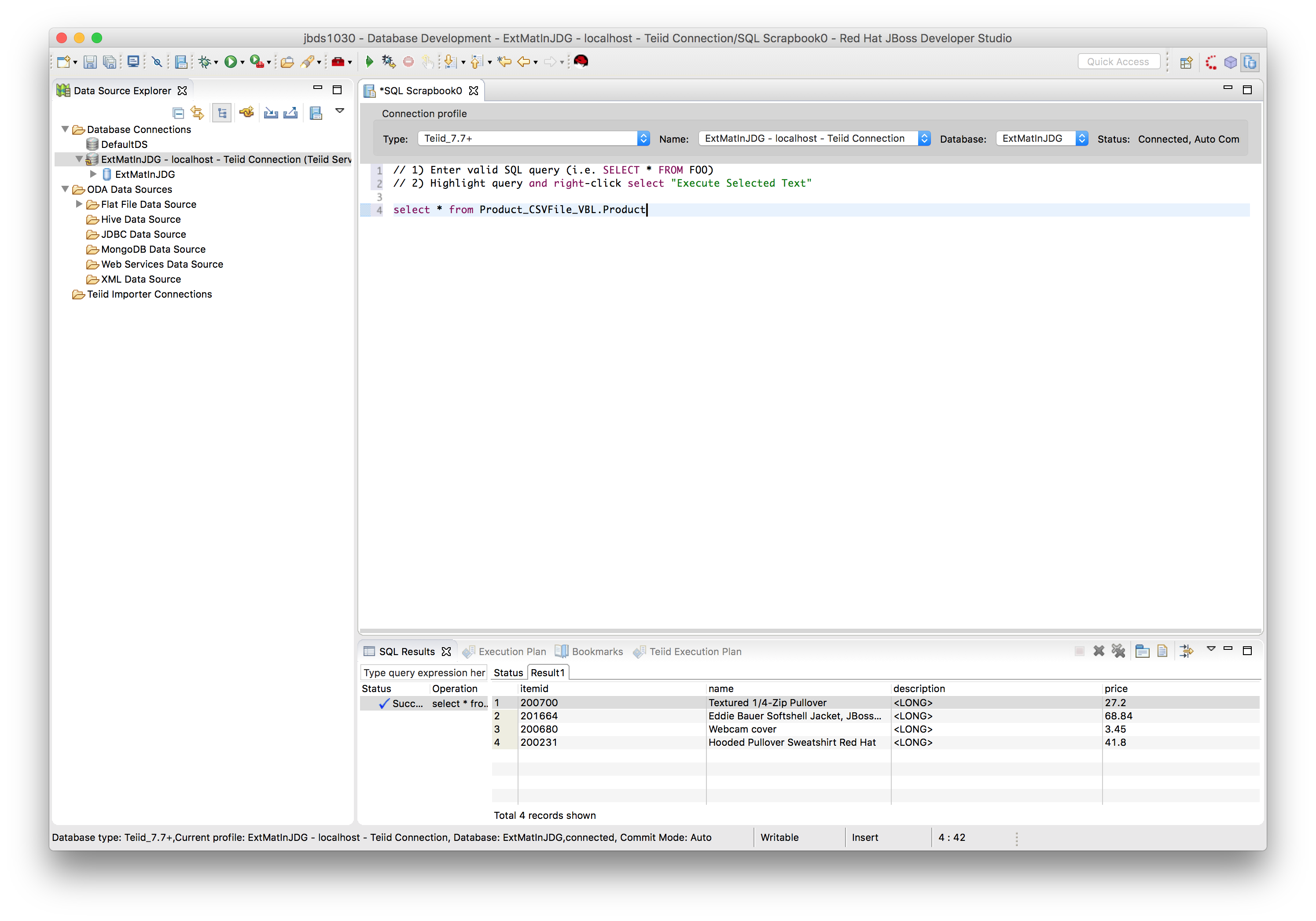
Retrieve data from materialized view i.e.
SQL> select * from Product_JDGMat_VBL.Product;

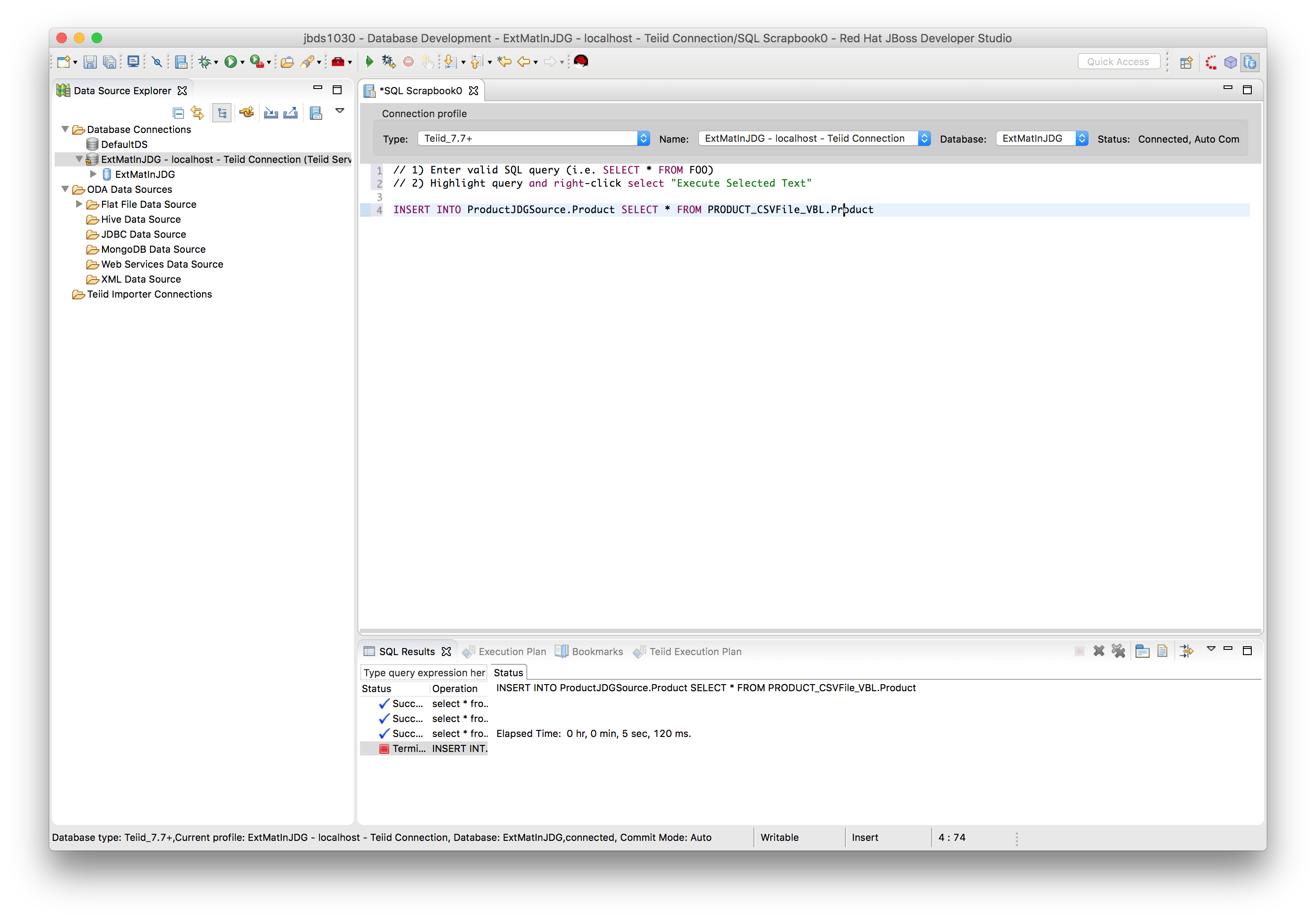
The above query will be served through the virtual table (ProductJDGSource.Product) from the cached contents instead from the original source. Since we didn't add any entries in the cache, the result of the query is no rows. One need to determine a load and refresh strategy, with the schema created, the simplest approach is to load the data using an INSERT statement. You can load the data using the following command:
SQL> INSERT INTO ProductJDGSource.Product SELECT * FROM PRODUCT_CSVFile_VBL.Product
The server.log file should contain following log entry:
GENERATE CANONICAL: SELECT Product_JDGMat_VBL.Product.itemid, Product_JDGMat_VBL.Product.name, Product_JDGMat_VBL.Product.description, Product_JDGMat_VBL.Product.price FROM Product_JDGMat_VBL.Product LOW [Materialized View] The query against Product_JDGMat_VBL.Product was redirected to the materialization table ProductJDGSource.Product. - null
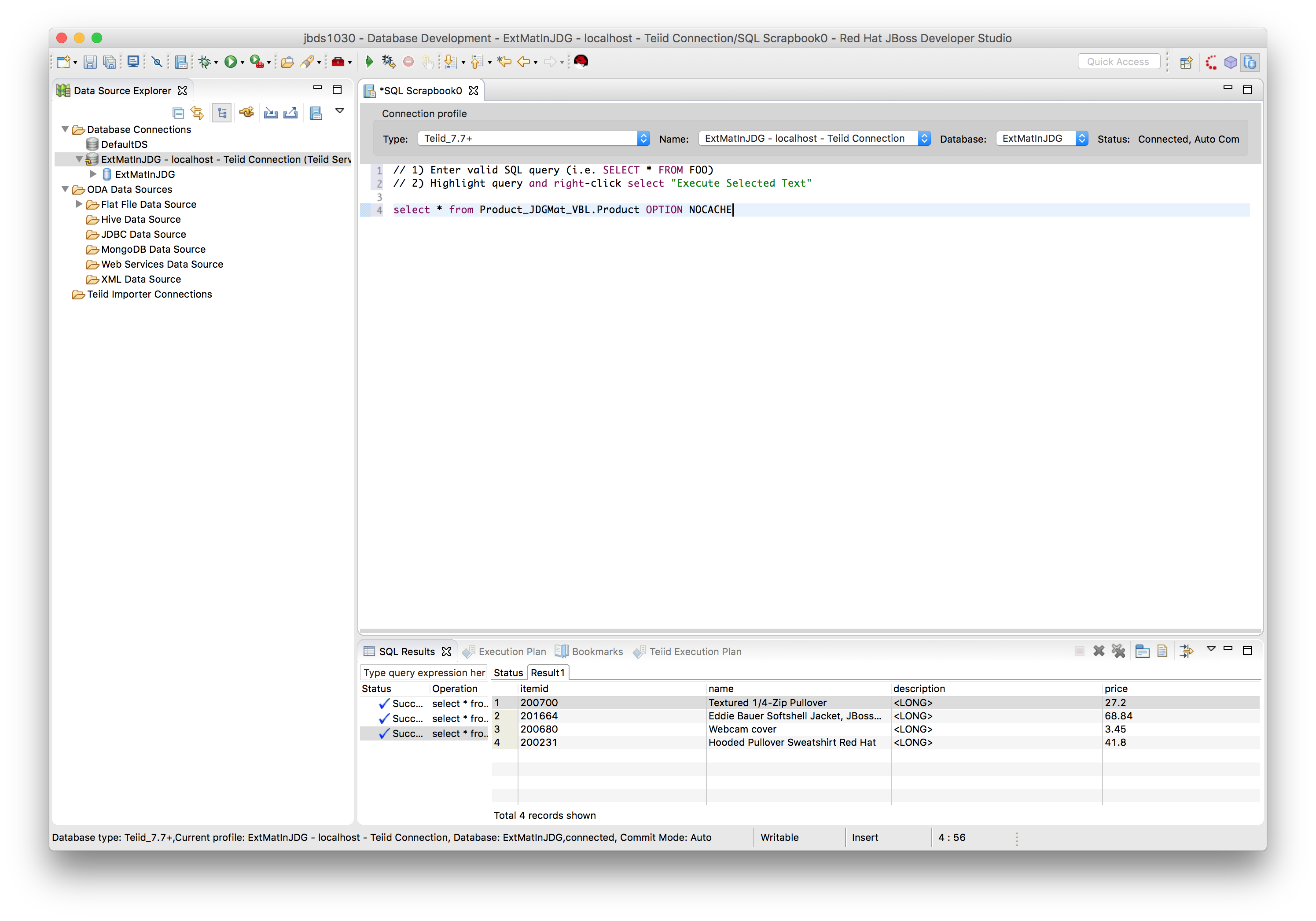
Retrieve data from materialized view but bypass the cached results in the materialized view which is equal to select * from Product_CSVFile_VBL.Product;
SQL> select * from Product_JDGMat_VBL.Product OPTION NOCACHE;
What about automating configuration?
A question you might ask: Can we automate the most of the above configuration steps?
The answer is yes; we can, with Ansible, by Red Hat.

As you can imagine, I like drinking our own champagne (Kool-Aid).
Ansible is a radically simple IT automation engine that automates cloud provisioning, configuration management, application deployment, intra-service orchestration, and many other IT needs. It uses no agents and no additional custom security infrastructure, so it’s easy to deploy – and most importantly, it uses a very simple language (YAML, in the form of Ansible Playbooks) that allow you to describe your automation jobs in a way that approaches plain English.
For your convenience, the above steps are automated in an ansible playbook called jdgmaterialization on GitHub and to run you only need to run one command and you should see a similar output as shown below:
$ ansible-playbook local.yaml PLAY [Demystified - Using external materialized views in Red Hat JBoss Data Grid with Red Hat JBoss Data Virtualization] *** TASK [setup] ******************************************************************* ok: [localhost] TASK [Install JBoss Data Grid 6.6.0] ******************************************* changed: [localhost] TASK [Install Red Hat JBoss Data Grid 6.6.1 Server Update] ********************* changed: [localhost] TASK [Install Red Hat JBoss Data Virtualization 6.3] *************************** changed: [localhost] TASK [Install Red Hat JBoss Data Virtualization Server 6.3.4 Update] *********** changed: [localhost] TASK [Create $JDV_HOME/teiidfiles/data to /Users/cvanball/test/jboss-dv-6.3.0/teiidfiles/data] *** changed: [localhost] TASK [Copy product data csv file $JDV_HOME//teiidfiles/data] ******************* changed: [localhost] TASK [Unzip Red Hat JBoss Data Grid Hot Rod Java Client Module] **************** changed: [localhost] TASK [Install the Red Hat JBoss Data Grid Hot Rod Java Client Module into the JDV server] *** changed: [localhost] TASK [Execute JDV Management CLI file(s)] ************************************** changed: [localhost] => (item=configure_jdv.cli) TASK [Execute JDG Management CLI file(s)] ************************************** changed: [localhost] => (item=configure_jdg.cli) TASK [Unzip JDG Product schema Module in the JDV environment] ****************** changed: [localhost] TASK [Copy module.xml including module to Product POJO to JDG Resource Adapter] changed: [localhost] TASK [Copy ExtMatInJDG VDB to JDV deployments directory] *********************** changed: [localhost] PLAY RECAP ********************************************************************* localhost : ok=14 changed=13 unreachable=0 failed=0
See http://github.com/cvanball/unlock-your-data/tree/master/jdgmaterialization for more information.
Conclusion
In this post, we’ve shown the steps one needs to perform in order to use Red Hat JBoss Data Grid for external materialization with Red Hat JBoss Data Virtualization. We have shown that Ansible is not only targeted at system administrators but that it’s also an invaluable tool for developers, testers, etc. I encourage you to experiment with the simple basics provided in this article and expand the functionality of your playbook gradually to create even more sophisticated provisioning scripts.
Now we are ready to add other data sources from physically distinct systems into the mix such as SQL databases, XML/Excel files, NoSQL databases, enterprise applications and web services etc.
For more information on Ansible, Red Hat JBoss Data Grid and Red Hat JBoss Data Virtualization please refer to the Ansible, Red Hat JBoss Data Grid and Red Hat JBoss Data Virtualization websites:
For more information on Red Hat JBoss Data Virtualization a data supply and integration solution and Red Hat JBoss Data Grid an intelligent, distributed caching solution.
Last updated: October 26, 2023