As a consultant for Red Hat, I have the privilege of seeing many customers. Some of them are working to find ways to split their applications in smaller chunks to implement the microservices architecture. I’m sure this trend is generalized even outside my own group of the customers.
There is undoubtedly hype around microservices. Some organizations are moving toward microservices because it’s a trend, rather than to achieve a clear and measurable objective.
In the process, these organizations are missing a few key points, and when we all awake from this microservices “hype”, some of these organizations will discover that they now have to take care of ten projects when before they had one, without any tangible gain.
To understand what it takes to reap real benefits from microservices, let’s look at how this neologism came to being.
Microservices, as a term, was born in the context of some of the Silicon Valley unicorns (such as Facebook, Google, PayPal, Netflix). These companies were splitting their large monolithic code bases in smaller chunks and assigning these new codebases to small and autonomous teams. The results seemed amazing, and industry observers decided to coin a new word to describe this process.
Unluckily, although the contribution of these consultants was huge for the IT community at large, the word choice was poor because it leads people to think that the size of your services has some relevance, while size does not matter.
Also, the service part of the name is not particularly meaningful. In fact, after SOA, we have learned everything there is to know about services and the microservices style does not add too much to that discussion (yes, REST has replaced SOAP, but that is irrelevant from an architectural perspective).
What this definition fails to capture is that the key reason for the success of those avant-garde companies were the small autonomous teams (this concept is also known as the 2-pizza team). These teams (four to eight people) had the ability to self-provision the resources necessary to run their apps and had end-to-end responsibility for them, including for the production environment (so, yes, they were carrying a pager). A better definition could have been micro and autonomous teams, putting the emphasis on the organizational aspects. But the name stuck, and it’s not going to change.
The full autonomy, the lack of bureaucracy and the full automation of all the processes (including infrastructure provisioning) were the factors that made those small teams successful.
I believe the roadmap to microservices can be an incremental one and I have summarized one process that is working in a few companies (see this blog for example). These steps are self-contained and each one of them will bring value even if the following are not pursued, here they are:
- Build a cloud capability.
- Deploy your applications to your cloud.
- Automate your delivery pipeline.
- Give your delivery teams full end-to-end responsibility for their code.
- Break-up your delivery teams and code in smaller units.
Notice that when the aforementioned consultants were visiting those Silicon Valley companies, step one, two and three were already completed and probably that is why these steps were so overlooked, but many traditional enterprises are not there yet and should worry about them before jumping to splitting the code.
Build a cloud capability
A cloud capability is necessary to give your delivery team the ability to self-provision the infrastructure they need. This is a foundational step towards full application team autonomy.
Much has been already written on how to create an enterprise strategy to build a cloud capability (whether it is on-premise or on a vendor cloud). The only thing I have to add is that today cloud means container-based cloud (here you can find some reasoning around this concept).
If you don’t yet have a cloud capability, consider jumping directly to a container-based cloud.
If you have a virtual machine-based cloud strategy in flight, consider layering a container-based cloud strategy on top of it. You can use your VM-based cloud to run your container cluster manager and other workloads that you don’t want to containerize, but you should give your delivery teams access only to the container-based cloud.
Deploy your applications to your cloud
Make your “cloud migrant” applications able to work in the cloud and deploy them there. Keep working on your applications until they become cloud native.
The type of work needed to make your application work in the cloud is application-dependent and cloud-dependent. But, there are some commonalities.
Things in the cloud are extremely dynamic (for example servers don’t necessarily have always the same IP) and your application needs to adapt to it.
In order to cope with the cloud and at the same time leverage some of the features of the cloud, such as self-healing capability and elasticity, your applications will need to adapt over time some of best practices contained in 12-factor principles or implemented the Netflix OSS stack. In this article, you can find a series of architectural cross-cutting concerns that I believe you should consider when migrating your workloads to the clouds.
If you complete this step, you’ll be able to easily change your application architecture and topology, thanks to the fact that you can dynamically provision your infrastructure quickly. This opens the door to fast experimentation. For example, you want to try Redis as a distributed memory cache as opposed to the enterprise-approved tools, you just deploy it and try it.
Automate your delivery pipeline
There is no need to highlight more on how important is to automate your delivery process as much as possible. Here is an enlightening video on what a delivery pipeline should look like.
The objective here is to reduce the cost and time of moving your code through environments and eventually to production while improving deployment accuracy, consistency, and repeatability.
I recommend applying the principles of immutable infrastructure when designing your delivery pipeline. In other words, the only way to modify your infrastructure should be to destroy and rebuild it with the new definition.
In my experience, the most difficult step to achieve is automated integration tests, so my advice is to start working on it as soon as you can. Automating integration tests may have organizational impacts because the team doing manual tests will be required to turn into a team that writes code (test code). This can be a difficult transformation. A good automated test suite is a suite that everybody trusts to the point that nobody feels the need to do manual tests (except for exploratory testing and UAT).
It is important to understand that if you don’t automate your tests, you won't be able to increase your speed of delivery beyond a certain value. That value is exactly how long it takes your test team to manually retest the entire application. From what I’ve seen, this value tends to hover around three/four weeks. If your objective is to deliver with a higher frequency than that, the only way to remove that constraint is to fully automate your tests.
Given the plasticity of the environment that you have created in the previous steps, it is now relatively easy to add environments dynamically so that you can spin them up and down based on need. You should use this capability to automate load tests.
Give your delivery teams full end-to-end responsibility
Many companies’ IT looks like the below diagram from an organizational standpoint:
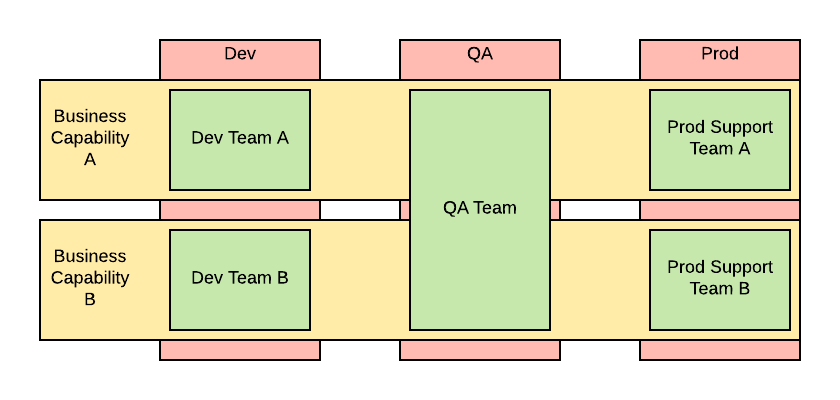
In order to give your delivery team full end-to-end accountability you need to move your organization towards something that looks like the following:
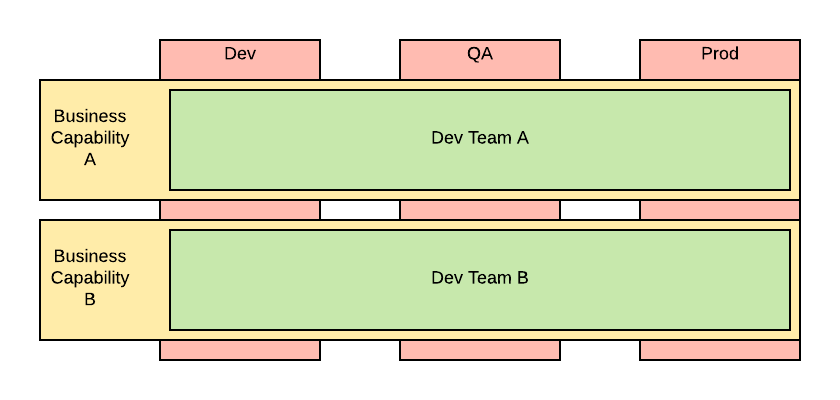
This is what many of the Silicon Valley startups do, and it is described in more details in a famous Spotify blog (part 1 and part 2).
This step eliminates meetings and bureaucracy because now your delivery team is in charge of all the aspects of your application lifecycle.
Obviously, in order for your delivery team to be successful in this role, you will have to beef it up with new skills. You will need “T” type people as opposed to “I” types. The shape of the letter refers to the skill profile of an individual. An “I” type can do one thing very well. A “T” type is specialized in one thing, but can also do other things at a decent level (for example code well in Java, but also create basic containers).
This is going to be an important transformation for your organization and I am skeptical that all organizations will really want to go through it. In this new configuration, your Ops team becomes much slimmer and focused only on keeping your cloud services up and running. Your cloud infrastructure will run all your applications and it will have to be more reliable and more available than any of the applications you run on it.
Conversely, your delivery teams will become larger and acquire new responsibilities. This growth is what will bring you to the last step.
Break-up your delivery teams and code in smaller units
Your delivery teams may have become bulkier and slower moving than you wanted in the previous step. This step corrects the issue by splitting the teams and consequently the code they manage into smaller chunks. As mentioned before the ideal size of the 2-pizza teams seems to be around 4 and 8 people. This may be a difficult process because all teams still need to have the right balance of skills, which can be difficult to achieve with smaller teams.
In the end, your organization will look like the following:
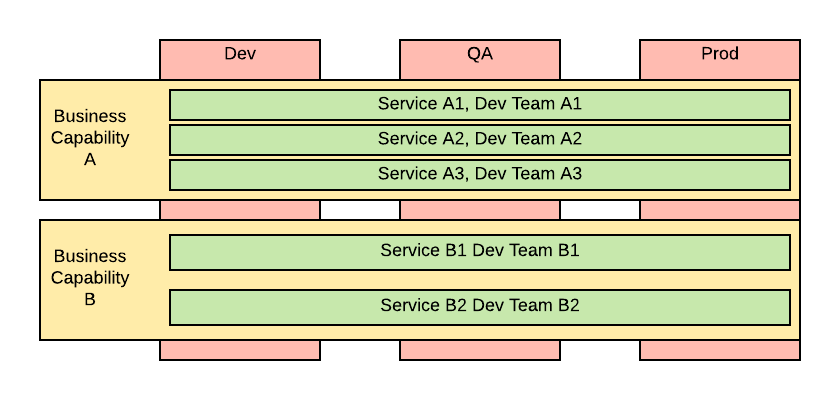
This step will make your organization look like one of the Silicon Valley unicorns and in theory, will enable you to achieve the same level of delivery speed. That means the very high frequency of delivery or even continuous releases in which every time a code push is sent to your versioning systems a new release in production is performed.
Conclusions
As I was saying in the introduction, I’m seeing several customers doing step number 5 (for the code only), without having completed the previous steps. I don’t recommend doing that. I also don’t think that microservices as in steps one to five are necessarily for every organization. I argue that many organizations (especially those that are heavily regulated) would gain enormous benefits from just moving their workloads to the cloud and by fully automating their processes (steps one to three).
Join Red Hat Developers, a developer program for you to learn, share, and code faster – and get access to Red Hat software for your development. The developer program and software are both free!
Last updated: August 29, 2023