In part one of this series of blog posts, we discussed the importance of user experience within the mobile industry, and how your API has a significant effect on this. In the this article, we’ll outline a number of techniques that you can leverage on an MBaaS solution such as Red Hat Mobile Application Platform to reduce the data downloaded by mobile devices when they make requests to your RESTful API.
Reducing the size of a response is conceptually simple; the fewer bits you're pushing through a connection, the less time a user spends waiting for said bits to download. To minimize the size of the payload we’re sending back, we will:
- Add gzip compression to our responses
- Strip data that the client doesn’t utilise from responses
- Avoid sending any data to the device by using the ETag header
We’ve prepared a sample application that will be updated as we progress through this series of blog posts. You can find the starting point code here with a README.
Take a look at the /jobs endpoint in this example application. You will see that the response size is 88.5KB, which isn’t a significant amount of data, but we’ve made no effort to reduce the payload size for our mobile users --- right now we might be sending far more than is necessary! In the following paragraphs we’ll reduce the payload size using several techniques (listed above).
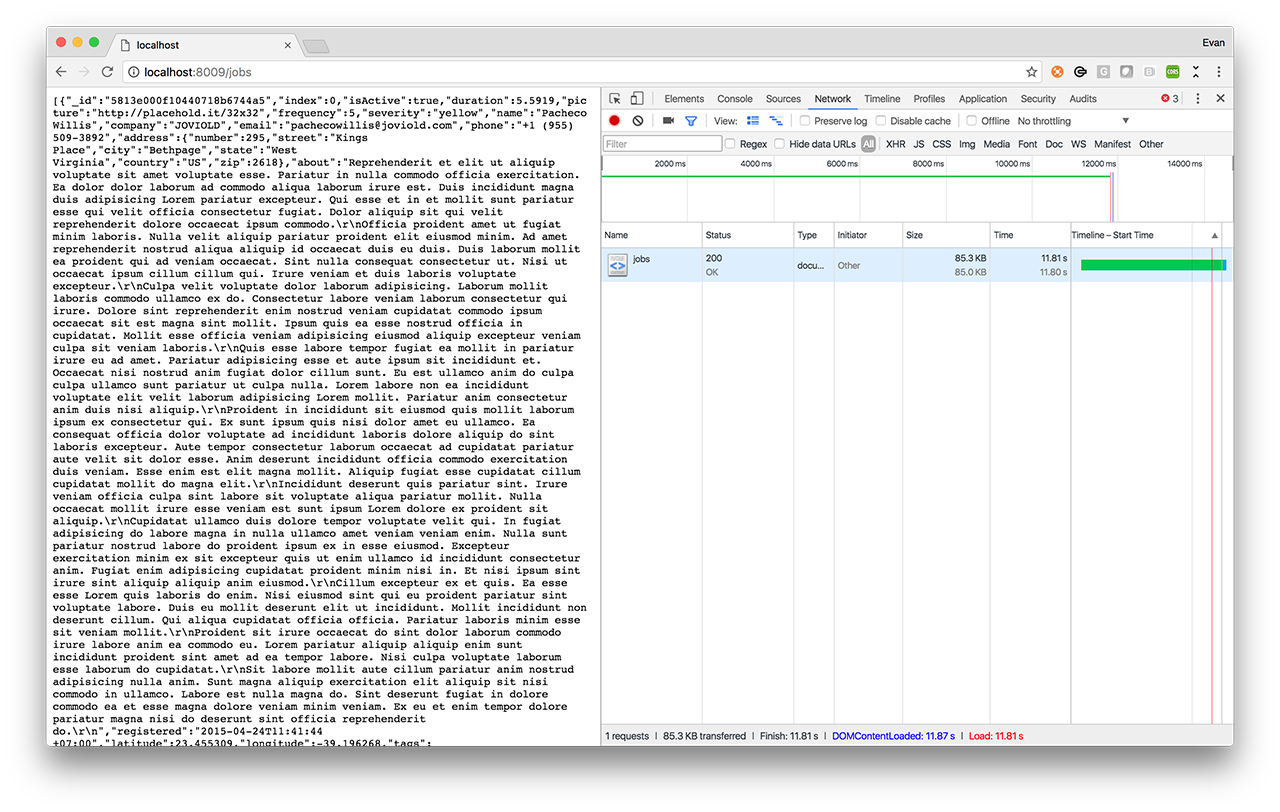
Our initial API implementation returns 85KB of JSON within 10-15 seconds
Removing Unnecessary Data From Responses
It might sound obvious, but it’s absolutely worth mentioning since it’s easily overlooked. Your new mobile API will often need to integrate with older systems originally designed to power desktop applications, and therefore it may also produce the large amounts of data that those bulkier applications need.
Your mobile devices may not utilise all of this data, so sending it wastes not only battery, but also bandwidth and the time of users who are forced to download it. Stripping data like this out of responses from our mobile API, and performing data marshalling are core use cases for an MBaaS solution such as Red Hat Mobile Application Platform.
How can you strip these values without writing excessively verbose code? By leveraging the fact that JavaScript is awesome!
Since Red Hat Mobile Application supports the npm ecosystem, you can install JavaScript utilities such as the excellent lodash and Ramda. Both of these modules simplify data marshalling and are excellent examples of the power of functional programming. Executing the omit function on JSON data allows you to return a copy of the same data, but with any number of keys removed. Take a look at this modified example of the /jobs route to see this in action:
// Create a curried function that will iterate (map) over jobs and omit certain keys var stripUnusedKeys = R.map( R.omit([ 'latitude', 'longitude', 'index', 'about', 'tags' ]) ); // Fetch jobs, process them, and send to the client esb.getJobs() .then(getWeatherForJobs) .then((jobsWithWeather) => stripUnusedKeys(jobsWithWeather)) .then((formattedJobs) => res.json(formattedJobs)) .catch(next);
By dropping this function generated by Ramda into our chain of operations (JavaScript Promises), we seamlessly strip fields from the data that aren’t used by a mobile device. If we check the response size for this API endpoint now, we’ll note that the data it returns has been reduced in size from 85.5KB to 15.5KB - that’s an 85% reduction! Your mileage for this technique will vary based on the structure of your data, and which fields are required by your mobile solutions, but it’s incredibly easy apply this technique!
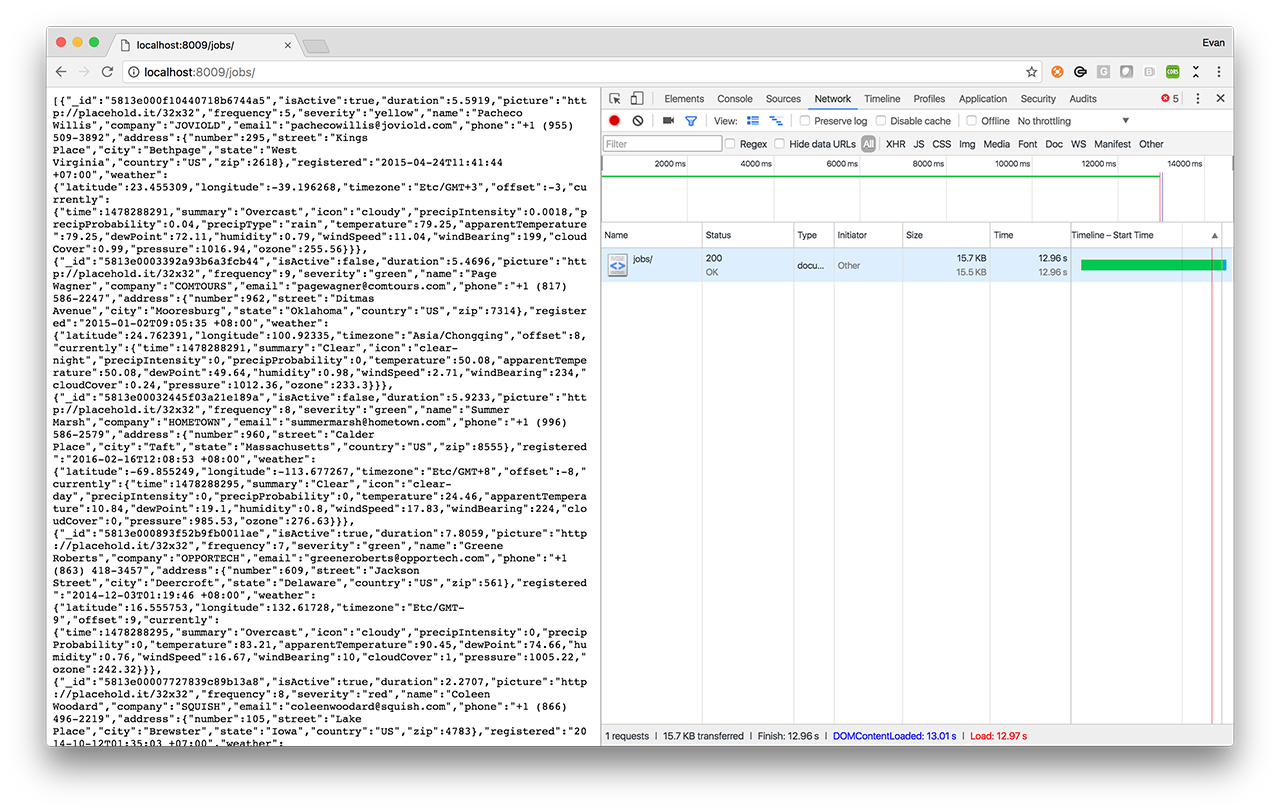
Stripping unused data removed 73KB of data from our response payload
HTTP GZIP Compression
If you're not familiar with HTTP compression via gzip, then you can read about it at this link, but in summary, it will compress your HTTP responses before sending them across the wire, or cell network in the case of our mobile API. Performing compression reduces the time a mobile device spends downloading data from your server, since it needs to transfer significantly fewer bytes.
Adding gzip compression to a node.js application running on Red Hat Mobile Application Platform is probably the easiest improvement discussed in this series of blog posts. We simply need to add the following piece of middleware to our express application.
// Compress all responses from the server app.use(require('compression')());
As you can see, enabling compression is a matter of adding just a single line of code to your application. The screenshots below demonstrate that the bandwidth usage over the wire in our example is more than halved by using gzip compression. This means significantly less bandwidth and battery is consumed by mobile devices accessing this API since only 22KB is transferred over the network, but it ultimately expands to our original 85KB of data.
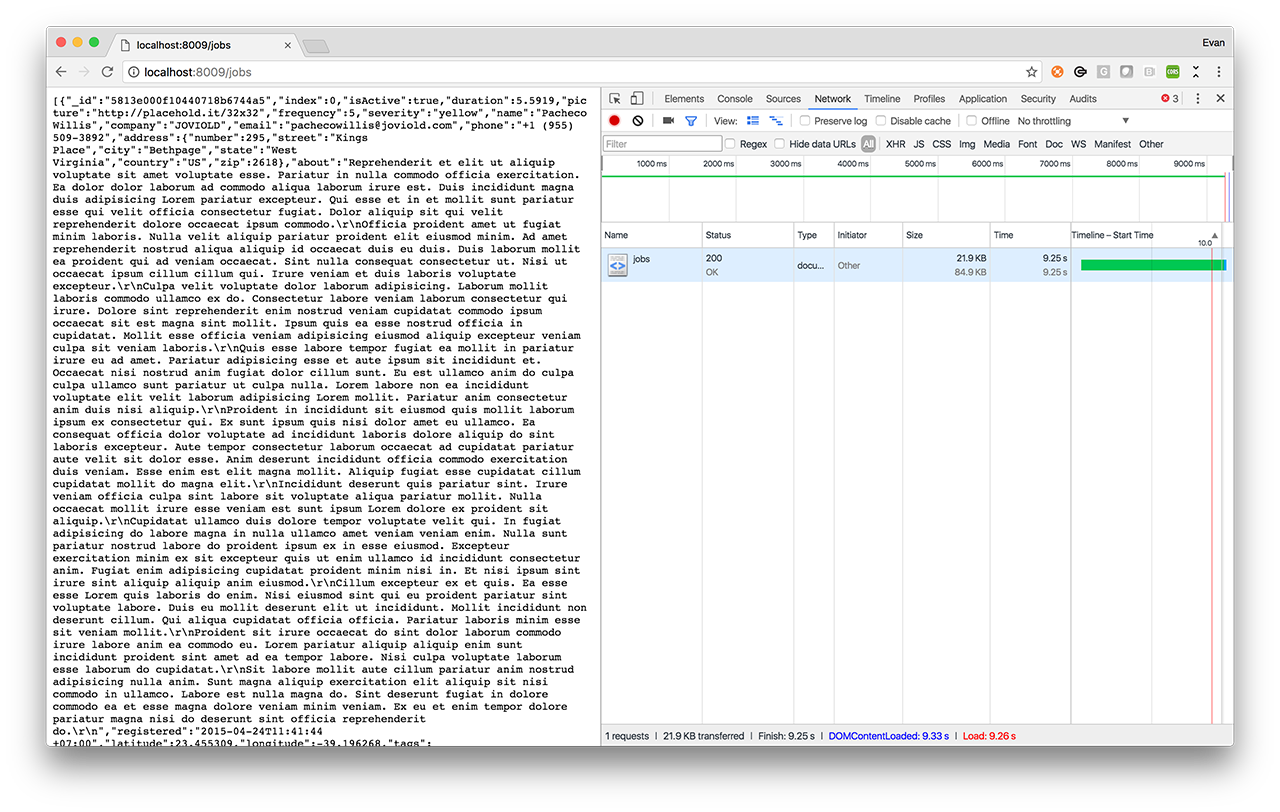
22KB of gzipped data is transferred across the network, but expands to 84.9KB
You may now be curious to see what happens if we combine our techniques for omitting unused data from responses with techniques for compression. Doing so reduces our original 85KB payload to a mere 4.4KB (expands to 15KB once downloaded) across the wire --- that’s a 95% reduction in data being sent to the device! 95% fewer bits being transferred will result in significantly less battery utilisation and a more responsive mobile application.
ETag Header
We’ve already seen that omitting unnecessary data and using GZIP can drastically reduce network overhead for mobile devices accessing our API, but wouldn't it be great if your application didn’t need to download any data at all? This is possible if the application has already fetched the latest version. Better yet, imagine if your web server automatically determined if the response to a request is unchanged, and therefore simply responded with a "304 - Not Modified" for a given API call. If you update to Express 4.12 or higher that's exactly what you'll get.
Newer versions of Express generate a weak ETag header for all request responses. This means that when you respond to an incoming request, express automatically generates a unique identifier for the current representation of the response and sends it to the client with the response body. A mobile device should then store this ETag header locally. When making a subsequent request for the same URL the mobile device should include the ETag value in an “If-None-Match” header. Once our express server has generated the response to the request, it can verify if the response ETag matches the incoming “If-None-Match” value. If they do, the server will respond with a 304 Not Modified instead of the entire response. This prevents a client wasting bandwidth and battery by continuously re-downloading the same data.
If you’re using ETags, then congratulations are in order --- you've helped the environment by sparing mobile devices from wasting battery and bandwidth. You’ve made end users happier, and all you had to do was install a newer version of express, like so:
npm install express@4.14 --save
Wondering what this looks like in action? If you use Chrome DevTools you can see that the server responded to our request with a HTTP 304 response, and the browser appropriately loaded a locally cached copy of the data. This even works for XHR requests!
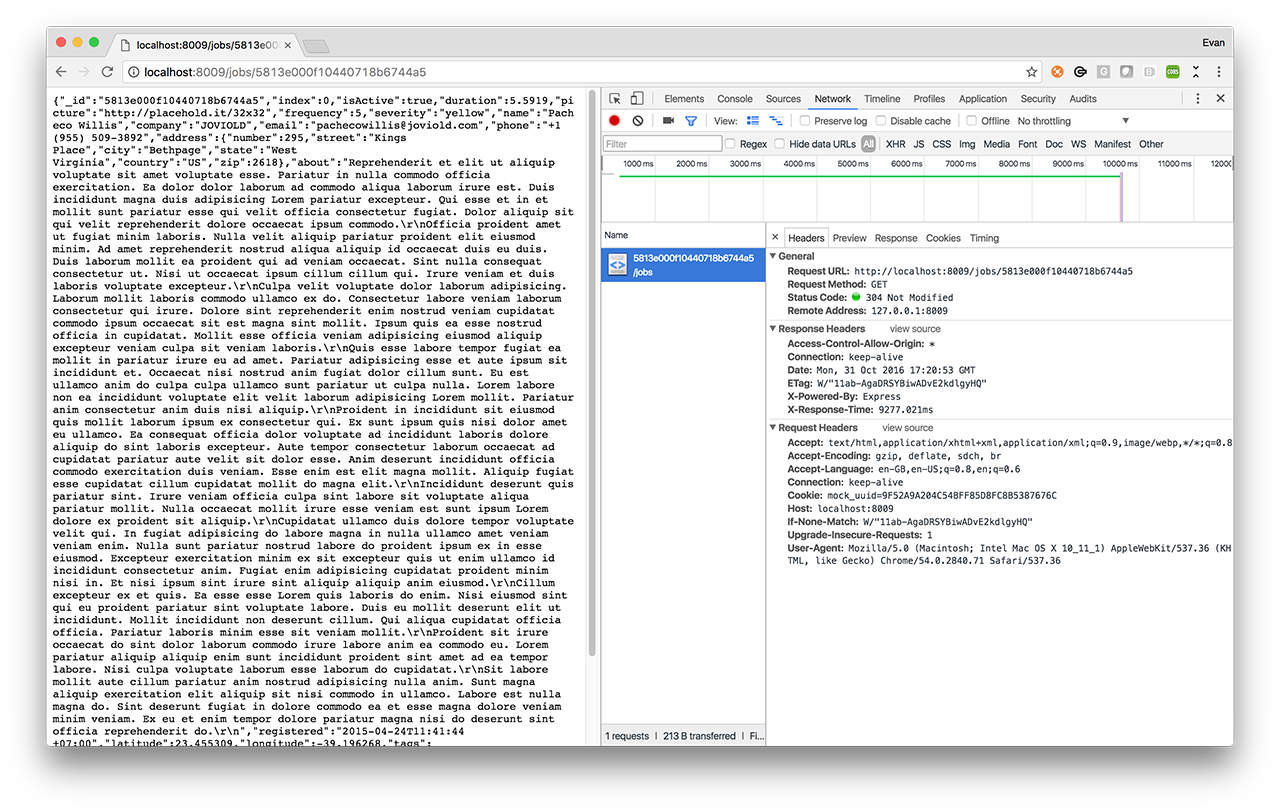
A “304 Not Modified” is returned for subsequent requests for the same resource
Summary
If we were to combine the above techniques we’d significantly reduce the battery and bandwidth overhead our API has on mobile devices. We’d also dramatically reduce the time a user spends waiting for data to download. The screenshot below demonstrates that we’re now sending just 4.5KB of data down to devices vs. the original 85KB - that’s roughly a 95% reduction!
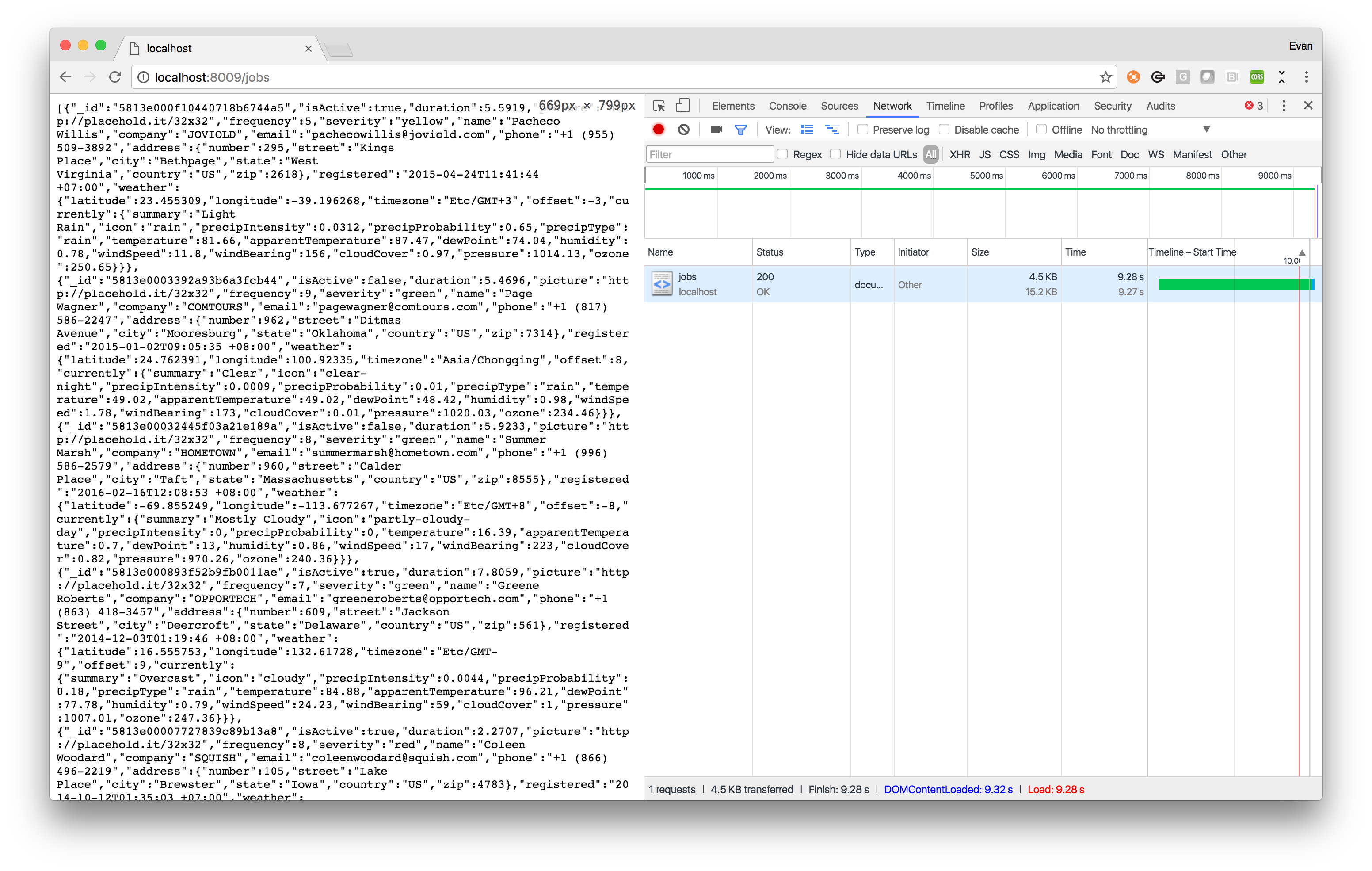
By omitting unused data and using GZIP we now send just 4.5KB over the network
Combine this with ETags to prevent devices unknowingly downloading the same data twice and you’ll have a significantly positive impact on the overall user experience in applications that depend on your API. However, while our API now returns smaller, more efficient payloads, it still takes around 10 seconds to process a request - we’ll tackle this in part 3!
If you’d like to see the code after adding the enhancements in this post you can find it here. For a changeset between the initial code and updated code take a look here. Stay tuned for the next part in our series!
Last updated: September 19, 2023