Microservices are currently enjoying immense popularity. It is rare to find a tech conference without at least a few mentions of them in corridor conversations or titles of talks, and for good reason: microservices can provide a path to better, more maintainable, higher quality software delivered faster. What's not to love?
Of course there are the "negatives" and details in the implementation of microservices that can trip up even the most seasoned architect-developer, but at the same time we are collectively learning from mistakes and creating or reusing fantastic open source projects and products that can help smooth over those rough bits.
One such project is Apache Camel (and Fuse, its Red Hat-supported distribution.) Created way before the microservices revolution, Apache Camel was born to ease integration of disparate computing systems by implementing well-tested enterprise integration patterns (EIPs) and supplying a developer-friendly interface for writing code to do the integration.
Microservices are by their nature an integration problem, where you have many decoupled services that need to work together. In working with Camel over the last few months, I have observed that it gets most of its credit from its large collection of components that can talk the language of many existing systems. But in the microservices context, what's even more interesting to me are the EIPs and how they align very well with microservices architectures (I am not the first to observe this, but I don't think it gets enough credit!)
In this post I'm going to show you how I used Camel to implement a microservice pattern, the API Gateway, replacing hand-crafted code with a much more elegant solution (in my opinion.) The example application for this is a demo I developed for making a more eye-catching and real-world version of the excellent Red Hat Developers Hello World Microservices demo, while still being able to demonstrate various aspects of microservices-oriented applications (such as the use of API Gateways, call tracing, circuit breakers, CI/CD pipelines, etc). It is a retail store demo, with typical store elements such as a product catalog, inventory service, shopping cart, etc.
In this application, the API gateway serves to provide a single, load-balanced point of entry for clients like mobile apps, and in some cases to aggregate data from multiple microservices into a single result. There are benefits and drawbacks to including this aggregation logic in the API Gateway, and it may make sense to separate them, especially if you include more detailed business logic in the aggregation, but for my purposes, I had no need for any actual business logic, so I decided to combine them. Your mileage may vary.
The general arrangement of services and their runtimes is illustrated below:

Here, we have several microservices providing the retail store services running on an OpenShift Container Platform, SSO for authentication using Red Hat SSO, call metrics with Hystrix+Turbine and a UI for our customers (thanks PatternFly!) The UI shows product names, descriptions, prices, and availability of products across the various brick-and-mortar stores of the shop. The idea is that the inventory service is a legacy backend mainframe, the pricing service is a modern rules-driven thing to dynamically calculate discounts, taxes, etc and the catalog is some other system. To construct the initial UI, the client could make individual calls to each (exposing each on the internet, requiring multiple round-trips to get the data, etc), but instead we introduce the API Gateway to mediate and aggregate data, and provide a single response. So the simple call to "give me the products to show" looks like:

Here, the call to the /api/products endpoint requires the gateway to first fetch the list of products, then for each one, fetch its availability (via the inventory service), aggregate the results into a single JSON blob and return to the client.
Cut 1: Brute force using a for() loop:
I didn't actually implement this, but you can imagine what it would look like via this pseudo-code:
List<Product> products =
HttpClient.get("http://catalog-service/api/products").convertToProductList();
forEach(Product product : products) {
Inventory inventory =
HttpClient.get("http://inventory-service/api/availability/" + product.itemId)
.convertToInventory();
product.setInventory(inventory);
}
return products;
It's short, easy to understand code, but not very resiliant to timeouts/failures, and is completely serial in execution.
Cut 2: Concurrency and Resilience
I started here for the implementation, taking the simple code from Hello World MSA's API Gateway and bolting on my attempt at using Java Concurrency to handle the async REST calls and stream operations to handle the aggregation:
final CompletableFuture<List<Product>> productList = CompletableFuture.supplyAsync(() ->
feignClientFactory.getPricingClient().getService().getProducts(), es);
return productList.thenCompose((List<Product> products) -> {
List<CompletableFuture<Product>> all =
products.stream()
.map(p -> productList.thenCombine(
CompletableFuture.supplyAsync(() ->
feignClientFactory.getInventoryClient().getService().getAvailability(itemId), es),
(pl, a) -> {
p.availability = a;
return p;
}
)
)
.collect(Collectors.toList());
return CompletableFuture.allOf(all.toArray(new CompletableFuture[all.size()]))
.thenApply(v -> all.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList()
)
);
}
).get();
This is better functionally, but IMO Java Concurrency is way too "wordy" and this is not very intuitive or readable. It's still essentially a for() loop, but doing all the network calls asynchronously, and using Feign to make a more type-safe REST call, and Hystrix for circuit breaking when the underlying inventory service is too slow or dead.
Cut 3: Camel
Camel's DSL for REST looked very promising, and when I learned there were components for Hystrix and implementations of EIPs for aggregation, I thought I'd give it a shot. The Enricher EIP in particular sounded exactly like what I was doing:
"The Content Enricher uses information inside the incoming message (e.g. key fields) to retrieve data from an external source. After the Content Enricher retrieves the required data from the resource, it appends the data to the message." - from Enterprise Integration Patterns
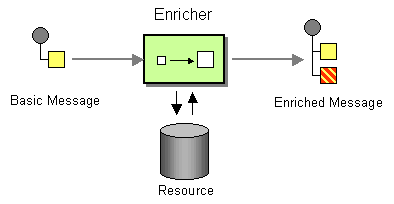
After trial and error (but not much!), here is what's currently in the codebase for this API's Camel route:
.hystrix()
.to("http://catalog-service:8080/api/products")
.onFallback()
.to("direct:productFallback")
.end()
.unmarshal()
.split(body()).parallelProcessing()
.enrich("direct:inventory", new InventoryEnricher())
Again, still essentially a for() loop (which incidentally could be improved by making the inventory service handle batch requests), but IMO much more compact and elegant. The "magic" aggregation happens by split()'ing the list of products into a stream and then enrich()'ing the stream by fetching the inventory (inside another route), setting the inventory into the product object via the InventoryEnricher, and returning the resulting enriched list of products.
The route to fetch the inventory also circuit breaks the inventory service using Hystrix:
.hystrix()
.setHeader("itemId", simple("${body.itemId}"))
.setHeader(Exchange.HTTP_URI, simple("http://inventory-service:8080/api/availability/${header.itemId}"))
.to("http://inventory-service")
.onFallback()
.to("direct:inventoryFallback")
.end()
.unmarshal()
The fallbacks in this case are additional Camel routes which do the same as Hello World MSA, namely generate a hard-coded substitute value:
.transform().constant(new Inventory("0", 0, "Local Store", "http://redhat.com"))
In summary, aside from Camel's collection of integration code for Facebook, Twitter and various other modern services, it implements a ton of patterns that are super useful for connecting microservices together without having to re-invent the wheel. Ride on!
Future improvements
- Caching service calls (e.g. using Camel Cache)
- Improving batch capabilities of the underlying services
- Adding Feign-like typesafe API infrastructure
- Integrating other Red Hat OpenShift xPaaS services such as Fuse and BRMS
- More domain separation (currently the API gateway must know too much about the catalog and cart structures)
Feedback and contributions are always welcome!
Last updated: November 9, 2023