Live migrating virtual machines is an interesting ongoing topic for virtualization: guests keep getting bigger (more vCPUs, more RAM), and demands on the uptime for guests keep getting stricter (no long pauses between a VM migrating from one host to another).
This discussion will go through the simple design from the early days of live migration in the QEMU/KVM hypervisor, how it has been tweaked and optimized to where it is now, and where we're going in the future. It will discuss how live migration actually works, the constraints within which it all has to work, and how the design keeps needing new thought to cover the latest requirements.
The discussion will also cover known unknowns, i.e TODO items, for interested people to step up.
This article is based on a presentation I recently delivered at the devconf.cz conference. The PDF version of slides are available here, but you won't need them to follow this post. The format followed for this article is: a textual representation of the slides, followed by a description of the content, roughly corresponding to what I would say during the presentation.
Table of Contents
- Virtualization
- QEMU
- KVM
- Live Migration
- QEMU Layout
- Getting Configuration Right
- Stages in Live Migration
- Ending Stage 2 (Transitioning from Live to Offline State
- Other Migration Code in QEMU
- VMState
- VMState Example
- Updating Devices
- Subsection Example
- Things Changed Recently
- New Features
- Stuff That's Lined Up
- Future Work
Virtualization
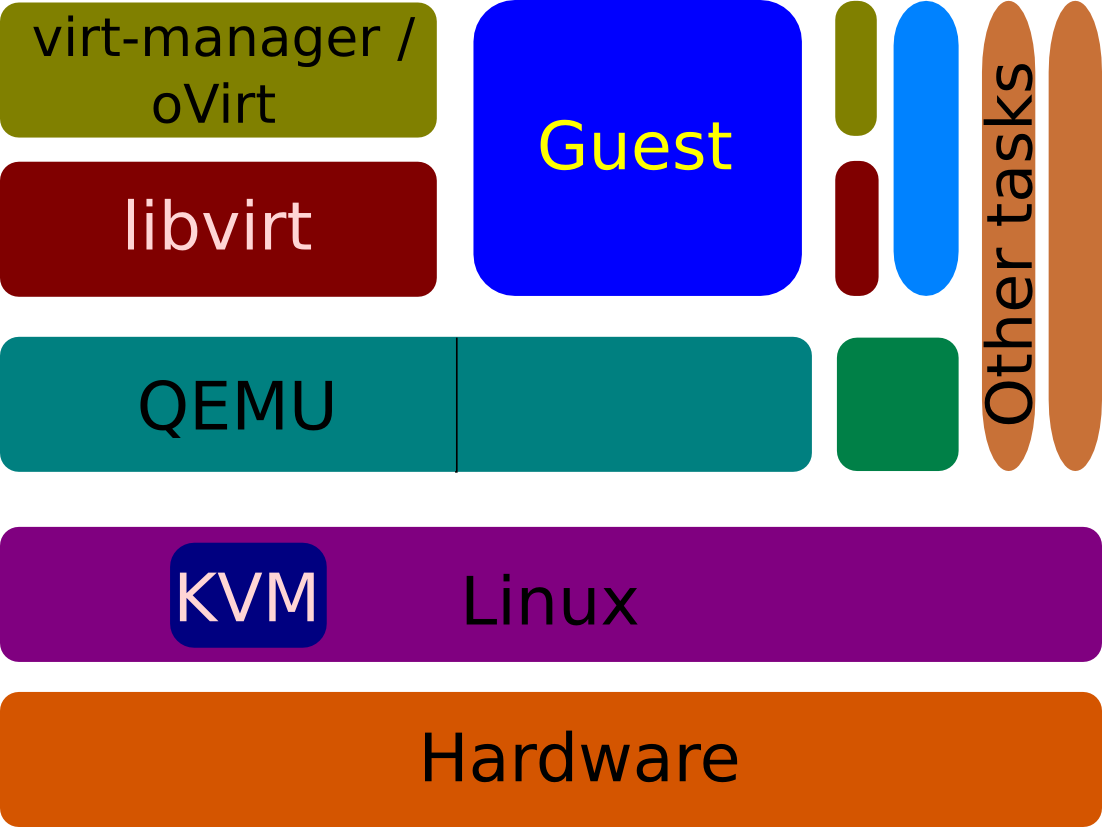 Let's start with an overview of the virtualization stack, starting from the top-left of the graphic. Users interact with virtual machines via one of the several available interfaces, like virt-manager, oVirt, OpenStack, or Boxes. These software in turn interact with libvirt, which provides a hypervisor-neutral API to manage virtual machines. libvirt also has APIs to interface with various block / storage and network configurations.
Let's start with an overview of the virtualization stack, starting from the top-left of the graphic. Users interact with virtual machines via one of the several available interfaces, like virt-manager, oVirt, OpenStack, or Boxes. These software in turn interact with libvirt, which provides a hypervisor-neutral API to manage virtual machines. libvirt also has APIs to interface with various block / storage and network configurations.
For QEMU/KVM virtual machines, libvirt talks with QEMU using QEMU-provided APIs. Each virtual machine created on a host has its own QEMU instance. The guest is run as part of the QEMU process. Each guest vCPU is seen as a separate thread in the host's top(1) and ps(1) output.
QEMU interfaces with Linux, especially the KVM module within Linux, to directly run virtual machines on the physical hardware (and are not emulated by QEMU).
QEMU
- Creates the machine
- Device emulation code
- some mimic real devices
- some are special: paravirtualized
- Uses several services from host kernel
- KVM for guest control
- networking
- disk IO
- etc.
QEMU is the software that actually creates the hardware which a guest operating system runs on top of. All of this virtual hardware is created by code, depending on the QEMU configuration. All the devices that the guest operating system sees, like a keyboard, a mouse, a network card, and so on, are instances of code within the QEMU project. Many of these devices are based on specifications released for physical hardware available, e.g. the e1000 family of network devices. Unmodified guest operating systems can recognize these devices thanks to the drivers they already ship with.
In addition to mimicking real hardware, QEMU also creates some devices written specifically for virtualization use-cases. For QEMU/KVM virtual machines, we use the virtio framework for creating these devices. We have a virtio-net networking device, virtio-blk block device, virtio-scsi SCSI device, virtio-rng RNG device, and so on. Paravirtualized devices have the benefit of being designed with virtualization in mind, so they are usually faster and easier to manage than the emulation of real devices.
QEMU also interacts with other projects, like SeaBIOS, that provides BIOS services for the guest.
For its operation, QEMU uses several services from the host Linux kernel, like using KVM APIs for guest control, using the host's networking and storage facilities, and so on.
KVM
- Do one thing, do it right
- Linux kernel module
- Exposes hardware features for virtualization to userspace
- Enables several features needed by QEMU
- like keeping track of pages guest changes
KVM is the small kernel module that enables hardware virtualization features for the Linux kernel. This code is responsible for converting the Linux kernel into a hypervisor. KVM was written in typical Linux- or UNIX-style: do one thing, and do it right. It leaves the memory management, process scheduling, etc., decisions to the Linux kernel. This means any improvements to the Linux memory manager immediately benefits the hypervisor as well.
KVM exposes its API to userspace via ioctls, and QEMU is one of the users of these services. One of the features that KVM exposes for userspace is keeping track of the pages in the guest memory area that the guest has modified since the previous time such data was requested. This feature is highlighted here since we use it during live migration, and we'll have more to say about this shortly.
Live Migration
- Pick guest state from one QEMU process and transfer it to another
- while the guest is running
- The guest shouldn't realize the world is changing beneath its feet
- in other words, the guest isn't involved in the process
- might notice degraded performance, though
- Useful for load balancing, hardware / software maintenance, power saving, checkpointing, ...
Live migration means moving a guest VM from one hypervisor / QEMU process, and making it run on top of another, while the guest is still running. The guest continues working normally and does not even realise the change in hypervisor taking effect. Live migration typically involves transferring the entire guest from one physical host to another one. This means a lot of variables are involved: network bandwidth, network latency, availability of storage, etc.
There is a small window when the guest has to be stopped for the new hypervisor to take over and start running the guest. This may result in degraded performance in guest applications, and this is the only exposure of the guest to the migration process.
Live migration is useful for a variety of reasons: balancing the load across several hosts in a server farm, or bringing down some hosts for hardware or software maintenance while keeping the guests running, or for saving power: if some hosts are lightly-loaded in a cluster, and can handle a few more VMs, without affecting the service, move VMs to the lightly-loaded servers and power down the unused ones. One can also checkpoint VMs to replay particular traffic or loads on the VMs to check for repeatability or software debugging within the VM. Though this use-case of checkpointing has nothing to do with live migration, the code used to make the checkpoints is shared with the live migration code internally within QEMU.
QEMU Layout
 Let's now take a look at what is going to be involved in the migration process. There's some state that we need to migrate as-is, that is without interpreting anything about the content of the memory area -- the entire guest. The guest is treated as a blob by the migration code, and we just send the contents to the destination. This is the area marked in gray in the diagram above.
Let's now take a look at what is going to be involved in the migration process. There's some state that we need to migrate as-is, that is without interpreting anything about the content of the memory area -- the entire guest. The guest is treated as a blob by the migration code, and we just send the contents to the destination. This is the area marked in gray in the diagram above.
The left-most part of the diagram, the guest-visible device state, is next. This is the state within QEMU which we send by our own protocol. This includes the device state for each device that has been exposed to the guest.
The right-most part of the diagram is QEMU state that is not involved during the migration process, but it is quite important to get this right before migration is started. The QEMU setup on the source and destination hosts have to be identical. This is achieved by using a similar QEMU command line on both the hosts. Since the QEMU command line can get very unwieldy due to the various options involved, we use libvirt to get this right for us. libvirt ensures both the QEMU processes are setup right for migration. For Red Hat Enterprise Linux, running QEMU directly is not recommended, and even not supported in newer versions. We always use QEMU via libvirt.
We will explore all of these three parts in more detail in the upcoming sections.
Getting Configuration Right
- Shared storage
- NFS settings
- Host time sync
- Can't stress enough how important this is!
- Network configuration
- Host CPU types
- Guest machine types
- esp. if migrating across QEMU versions
- ROM sizes
Let's start with the right-most part of the diagram, the setup. Getting an identical setup on both the source and the destination is essential for migration to succeed. It sounds easy to configure two VMs in an identical way, but there are some details that are not obvious.
The storage that the VM uses has to be shared and accessible to both the source and the destination hosts. Also, it matters a lot how the sharing is done, i.e. the file system in use must be configured to disable caching (otherwise in-flight data from the source may not have hit the storage before the destination starts running and accessing the storage, resulting in the guest seeing data corruption).
The wall-clock times on both the servers must match. NTP helps with this, but configuring the right time zones and ensuring the times are the same on both the hosts are essential. We have had several bug reports where migration initially succeeds, but later the guest becomes sluggish or stops running entirely; and it was quite difficult to zero down the problem to the time delta on the hosts. Windows guests are especially vulnerable to this source of misconfiguration.
Network configuration on both the hosts must match; if a guest was communicating with some servers earlier, its access to those servers must stay after the migration. Firewall configuration plays a part in this as well. Also, it's best to separate the storage network and the network over which migration happens: migration will be faster with more bandwidth being available, so storage IO is best left out of that network.
Host CPU types must match. The instruction set exposed to the guest on the source must be entirely available to the guest on the destination. This means migrating from a newer-generation processor to an older-generation processor may not work, unless care has been taken to start the VM with a restricted instruction set. Operating systems (and a few applications as well) query the CPU for the instructions supported by the CPU at the start. Afterwards, they use all the instructions that are available as necessary. Hence care has to be taken in choosing the CPU model to be exposed to the guest which is the least-common-denominator in the server farm.
QEMU maintains a list of machine types that are exposed to the guest. This is made up of a lot of compatibility code for the various devices that are exposed to guests. This is necessary to keep advancing QEMU with bug fixes and features, while maintaining bug-compatibility with previous QEMU versions to ensure migration continues working. Another aspect of this versioning is the various ROMs that are made available to the guest by QEMU, like the BIOS, iPXE ROMs, etc. These ROMs too have to be compatible across the source and destination hosts.
Stages in Live Migration
- Live migration happens in 3 stages
- Stage 1: Mark all RAM dirty
- Stage 2: Keep sending dirty RAM pages since last iteration
- stop when some low watermark or condition reached
- Stage 3: Stop guest, transfer remaining dirty RAM, device state
- Continue execution on destination qemu
Let's now discuss the actual migration process. This part references the middle portion and the left-most portion in the diagram above. The migration process happens in three stages. The first two stages deal with the gray area of the diagram, and the last stage works on the gray as well as the left-most area of the diagram.
We begin stage 1 by marking each page in that gray area "dirty" -- or "needs to be migrated". Then we send across all those pages marked dirty to the destination host. That's it for stage 1.
Remember the one thing we pointed out earlier on what services KVM provides to the userspace? The ability for userspace, like QEMU, to find out which pages were changed since the last time that data was requested. This is how we keep sending only the pages the guest changed since the last iteration. This is stage 2. We stay in this stage till some condition is reached. We will discuss what these various conditions are in a bit. It's easy to infer that this is the phase where most of the time is spent while live-migrating a guest.
Stage 3 is where we transition to non-live, or offline, migration: the guest is actually paused and doesn't make any further progress. We then transfer all the remaining dirty RAM, and the device state: the left-most area in the diagram.
The gray area is just opaque data for QEMU, and is transferred as-is. The device state is handled by special code within QEMU, and is discussed later.
Stages in Live Migration (continued)
- Live migration happens in 3 stages
- Stage 1: Mark all RAM dirty <ram_save_setup()>
- Stage 2: Keep sending dirty RAM pages since last iteration <ram_save_iterate()>
- stop when some low watermark or condition reached
- Stage 3: Stop guest, transfer remaining dirty RAM, device state <migration_thread()>
- Continue execution on destination qemu
The name of the function in the QEMU source code that handles each stage is mentioned in blue above. migration_thread() is the function that handles the entire migration process, and calls the other functions, so that's where one should look to start understanding migration code.
Ending Stage 2 (or Transitioning from Live to Offline State)
- Earlier
- 50 or fewer dirty pages left to migrate
- no progress for 2 iterations
- 30 iterations elapsed
- Now
- admin-configurable downtime (for guests)
- involves knowing # of pages left and bandwidth available
- host policies: like host has to go down in 5 mins, migrate all VMs away within that time
- admin-configurable downtime (for guests)
When to transition from stage 2 to stage 3 is an important decision to make: the guest is paused for the duration of stage 3, so it's desirable to have as few pages to migrate as possible in stage 3 to reduce the downtime.
The very first migration implementation in QEMU was rather simplistic: if there were 50 or fewer dirty pages left to migrate while in stage 2, we would move to stage 3. Or when a particular number of iterations had elapsed without making any progress towards having fewer than 50 dirty pages.
This worked well initially, but then several new constraints had to be added. Customers running their customers' workloads on KVM had to provide some SLAs, including the maximum acceptable downtime. So we added a few tunables to the code to make the conditions to transition from stage 2 to stage 3 configurable by guest as well as host admins.
The guest admins can specify the maximum acceptable downtime. In our stage 2 code, we check how many pages are being dirtied in each iteration by the guest, and how much time it takes to transfer the pages across, which gives us an estimate of the network bandwidth. Depending on this estimate of the bandwidth, and the number of dirty pages for the current iteration, we can calculate how much time it will take to transfer the remaining pages. If this is within the acceptable or configured downtime limit, we transition to stage 3. Else we continue in stage 2. Of course we still have other tunables which mention how long to keep trying to converge in stage 2.
There also are host-admin configurable tunables. An interesting use-case which illustrates the need for such tunables was presented by a Japanese customer at a panel discussion during the KVM Forum 2013. Japan data centres receive earthquake warnings; and in some cases, the data centres lose power at a scheduled time, say 30 minutes from the time of the warning. Service providers have this 30-minute window to migrate all of the VMs from one data centre to another, or all the VMs would be lost as a result of the power outage. In such cases, guest SLAs take lower precedence.
Other Migration Code in QEMU
- General code that transmits data
- tcp, unix, fd, exec, rdma
- Code that serializes data
- section start / stop
- Device state
There is some more code in QEMU related to migration: there is code specific to the transport used to send/receive migration data: TCP or UNIX sockets, local file descriptors, or RDMA. There is also an 'exec' functionality, by which data from QEMU can be piped to other processes on the host before being sent across to the destination. This is useful for compressing outgoing data, or encrypting outgoing data. At the destination, a reverse process of decompression or decryption has to be applied. For the UNIX sockets, fd, or exec-based protocols, a higher-level program is needed which manages the migration at both the ends. libvirt does this wonderfully, and we rely on libvirt's capabilities to handle migration.
There also is code related to serialization of data; code that indicates where sections or pages start and stop, and so on.
There also is device-related code, which we are going to talk about next.
VMState
- Descriptive device state
- Each device does not need boilerplate code
- Each device does not need identical save and load code
- Which is easy to get wrong
The device state, the left-most block in the diagram above, is highly specific to each device. The block device is going to have a list and count of in-flight data that still needs to be flushed out to disk. Also part of its state is the way the guest has configured or chosen to use the device. The network device is similarly going to have its own state. Almost all the devices exposed to guests have some state that needs to be migrated. The migration of device state happens in stage 3 after all the dirty RAM is sent across.
Till a while back, each device had to handle the sending and receiving part of its state itself. This meant there was a lot of duplication of code across all the devices in QEMU. VMstate is the new infrastructure added which makes the sending and receiving part device-independent. This is best illustrated by an example:
VMState Example
- e1000 device
- e482dc3ea e1000: port to vmstate
- 1 file changed,
- 81 insertions(+),
- 163 deletions(-)
Let's take a look at the commit that converted the e1000 device from the old way of handling state migration to VMstate. 81 lines inserted, and 163 lines deleted. That's a win.
VMState Example (before)
-static void
-nic_save(QEMUFile *f, void *opaque)
{
- E1000State *s = opaque;
- int i;
-
- pci_device_save(&s->dev, f);
- qemu_put_be32(f, 0);
- qemu_put_be32s(f, &s->rxbuf_size);
- qemu_put_be32s(f, &s->rxbuf_min_shift);
Here is a part of the commit referenced above that removes the older code. The function, nic_save(), used to "save" -- that is send on the wire -- all the state it needs for correct operation on the destination, sends each item from its state individually. Here we see two 32-bit signed integers being sent from a structure.
A corresponding nic_load() function would load the state in the same order.
It's easy to see how this could go wrong, and how this is unnecessary duplication for each device. Also, developers don't particularly enjoy writing things this way.
VMState Example (after)
+static const VMStateDescription vmstate_e1000 = {
+ .name = "e1000",
+ .version_id = 2,
+ .minimum_version_id = 1,
+ .minimum_version_id_old = 1,
+ .fields = (VMStateField []) {
+ VMSTATE_PCI_DEVICE(dev, E1000State),
+ VMSTATE_UNUSED_TEST(is_version_1, 4), /* was instance id */
+ VMSTATE_UNUSED(4), /* Was mmio_base. */
+ VMSTATE_UINT32(rxbuf_size, E1000State),
+ VMSTATE_UINT32(rxbuf_min_shift, E1000State),
Here we see a part of the commit that added the new VMstate way of saving and restoring device state. There's just one declarative structure describing what constitutes the device state. All the boilerplate code is handled elsewhere, transparently to each device.
Updating Devices
- Sometimes devices get migration-breaking changes
- One idea is to bump up version number
- Adds dependencies from higher versions to lower ones
- Difficult to cherry-pick fixes to stable / downstreams
- Another is to introduce new subsection
As part of the regular development process, bugs are discovered and fixed, as well as new features are added. When the new changes touch device state, a lot of care has to be taken to retain backward migration compatibility. That is, migration from an older QEMU version should continue to work to newer QEMU versions. Put differently, newer QEMU versions should continue to accept an incoming migration stream from an older QEMU version, state changes notwithstanding.
The classic way of handling such changes is by versioning the state per device that is put out on the wire. The source QEMU does not need to worry about what version the destination runs. It is purely up to the destination QEMU to interpret the various formats that get sent to it.
The destination QEMU's equivalent of the load functions check for what version of the device state is being sent. Depending on the version, the incoming data is stored into corresponding state variables in the destination's device structures. This means all the version-related complexities exist on the destination side of the migration process.
Of course, a destination QEMU that is at a lower version than source QEMU has no way of knowing what is being sent, and migration is failed in this case.
But this versioning scheme has a problem: imagine the e1000 device's state is at version 2. Now we add a new feature, which requires an addition to the state, bumping up the version to 3. Now if we detect a bug in the version 2 of the state, we will have to fix that, and update the version to 4. However, backporting such a fix to a stable release, or a downstream that does not want to introduce new features, but only wants to backport fixes, is in a bind. There is no way to backport the fix, and keep the version number consistent with upstream. Bumping up the version to 4 is not right, as the changes for version 3 haven't been backported.
A new scheme to address this situation was needed, and the answer is subsections. Let's see an example:
Subsection Example
- commit c2c0014 pic_common: migrate missing fields
VMSTATE_INT64(timer_expiry,
APICCommonState), /* open-coded timer state */
VMSTATE_END_OF_LIST()
+ },
+ .subsections = (VMStateSubsection[]) {
+ {
+ .vmsd = &vmstate_apic_common_sipi,
+ .needed = apic_common_sipi_needed,
+ },
+ VMSTATE_END_OF_LIST()
}
};
Here we see a new subsection added to the apic code's vmstate data. The 'needed' function is evaluated on the source. If the result is true (that is, the guest is in a state where that part is needed to be sent across to the destination), the vmstate information in the 'vmsd' section is sent to the destination.
This eliminates the need for versioning, and cherry-picking fixes is much easier and compatible between various QEMU versions.
Things Changed Recently
- Guests have grown bigger
- More RAM
- Means a lot of time spent transferring pages
- More vCPUs
- Means active guests keep dirtying pages
- More RAM
Now we move on to discuss some of the more recent work that QEMU has seen in its migration code. As KVM has matured, and as more customers use it for handling enterprise loads on their KVM hypervisors, we've seen bigger guests: more RAM being allocated, and many more vCPUs exposed to the guests. Big-RAM guests means there is much more data to be sent across in stage 2; which in turn means the downtime requirements become a lot more difficult to adhere to. More vCPUs means more work being done by the guest, and more RAM area being dirtied, resulting in longer stage 2 times.
A few features have gone in QEMU recently which help with such situations:
New Features
- autoconverge
- xbzrle
- migration thread
- migration bitmap
- rdma
- block migration
Autoconverge: this setting can pause some vCPUs so that guests don't make too much progress during stage 2 of migration by slowing it down. That gives an opportunity for the number of dirty pages to reduce to our low watermark conditions to transition to stage 3. Pausing guest vCPUs can be done in several ways: re-nicing the guest vCPU threads on the host (each vCPU is just a regular thread on the host), or by restricting the host CPU time the guest as a whole gets via cgroups, or by just not scheduling particular guest vCPUs at all from QEMU code.
xbzrle: this feature caches all the pages sent across to the destination in the previous iteration. For each page to be transmitted across, we compare the current page with the page in the cache. Only the difference in the bytes in such pages are then sent across. This greatly reduces the data that goes over the network in some workloads, and hence speeds up the migration process.
Migration thread: Initially, the QEMU code just had one thread for all QEMU activity, and separate threads for guest vCPUs. This meant any activity within QEMU would block all other activity. In the migration case, while sending and receiving data, no other activity could happen in QEMU. This also meant applications interacting with QEMU could not query how far ahead QEMU was in its migration progress. This lack of reporting was not a nice experience for admins, who had to wait for an iteration in stage 2 to finish before they got to know whether any progress was being made at all. Separating the migration code into its own thread lets QEMU run alongside the migration thread, and quite a few bottlenecks are reduced.
Migration bitmap: Previously, one byte was used to track each dirty page. For big-RAM guests, this meant the bitmap became too big, even bigger than the CPU caches, and the page-walk operation in each iteration in stage 2 became extremely slow. Another disadvantage was when the migration was triggered due to low-memory conditions on a particular host, we were just worsening the situation by allocating more RAM for the migration metadata. We now use one bit to represent each guest page, and that reduces the dirty page bitmap by a significant amount; such that it nicely fits within CPU caches, and the process isn't as slow.
RDMA transport: Using a faster interconnect, like Infiniband devices, between the source and destination hosts, ensures a much faster transfer of migration data, compared to Ethernet. The RDMA code is still quite new and not too well-tested, so this is an area where potential contributors can look for things to be improved.
Block migration: In addition to migrating the state, some customers need to use non-shared block storage. In such cases, even the storage needs to be migrated along with the guest state. This block data is huge, and takes a big toll on network bandwidth as well as the time needed for the migration process to finish.
Stuff that's lined up
- postcopy
- debuggability
There is a lot of work ongoing in the migration code, one of the features, postcopy, focuses on making the migration downtimes very small.
The migration process we've described earlier is the 'pre-copy' model: all the data is copied on to the destination host before switching to the destination for guest execution. In the postcopy model, we switch to the destination as soon as we can: this means we transfer the device state and one iteration of dirty RAM, and flip the switch to start executing on the destination. When the guest references some area in its RAM for which the corresponding page doesn't exist on the destination, a remote page fault fetches the page from the source host to the destination. It's easy to see why that this method is very fast at getting convergence. It however introduces extra points of failure: if one of the hosts goes down, or the network link between the two goes down, the entire guest is lost, as its state is spread across two hosts which can no longer be reconciled. In the pre-copy scheme, only the loss of the source host means the guest is lost forever.
Debuggability of the entire migration process has been a sore point: the wire format is not self-describing; a migration failure gives the message 'Device load failed; migration aborted', without any hint as to which section for which device failed to load, and why. Some work is now going on to make this better, and is an area where potential contributors can jump in. It's also a nice opportunity to learn the code while making it better.
Future work
- Finish vmstate conversion
- self-describing wire format
Some work, which no one has embarked on yet, is to finish the vmstate conversion. Unfortunately, not all devices are converted to vmstate, the biggest one being the virtio devices. It's essential to get this done, so that everything is uniform in the code. There also is a static checker program that checks for migration compatibility between various QEMU versions in an automated way, which only works on vmstate data, which virtio devices cannot currently take benefit of.
Also, as mentioned in the previous section, a self-describing wire format will help with debugging as well as peeking into the stream at various offsets, skipping sections, and so on. This is not currently possible.
This was a quick overview of the way live migration works for QEMU-KVM virtual machines. There are several details available in the email archives on the QEMU list, including performance numbers for the various optimizations mentioned here, and more discussions on the features themselves. Feel free to continue the conversation in the comments section below.
Last updated: February 22, 2024