The world of AI is rapidly evolving, and with it, the need for flexible, powerful, and easily deployable models. At Red Hat, we're always looking for ways to empower developers to build the next generation of intelligent applications. That's why we're thrilled to highlight RamaLama's new multimodal feature, bringing cutting-edge vision-language models (VLMs) directly to your fingertips, seamlessly integrated with the power of containers.
Beyond text: Embracing the multimodal revolution
While large language models (LLMs) have taken the world by storm with their text generation capabilities, the real power of AI lies in its ability to understand and interact with the world in a more holistic way. This is where multimodal models come in, bridging the gap between different data types–think images, audio, and text–to create a richer, more nuanced understanding.
Multimodal
Multimodal models bridge the gap between different data types, such as images, audio, and text, allowing AI to process and generate information across these diverse modalities. Unlike traditional LLMs that primarily focus on text-in and text-out, multimodal models can, for example, take an image as input and generate a descriptive text, or process spoken language to control a visual output. This capability enables a richer, more nuanced understanding and interaction with the world.
RamaLama now allows you to easily download and serve multimodal models, opening up a world of possibilities for applications that can see, understand, and respond to visual information alongside text.
Getting started: Serving your VLM with RamaLama
The process is incredibly straightforward. With RamaLama, you can get a multimodal model up and running with a single command:
ramalama serve smolvlmThis command handles everything from downloading the smolvlm model to setting up the necessary infrastructure to serve it. Behind the scenes, RamaLama leverages the power of containers to ensure a consistent and isolated environment for your model.
Connecting your web application: A camera demo
Once your smolvlm model is served, you can easily connect to it using an application. Imagine building an interactive application that can analyze images from a user's camera in real time and provide intelligent responses. RamaLama makes this a reality.
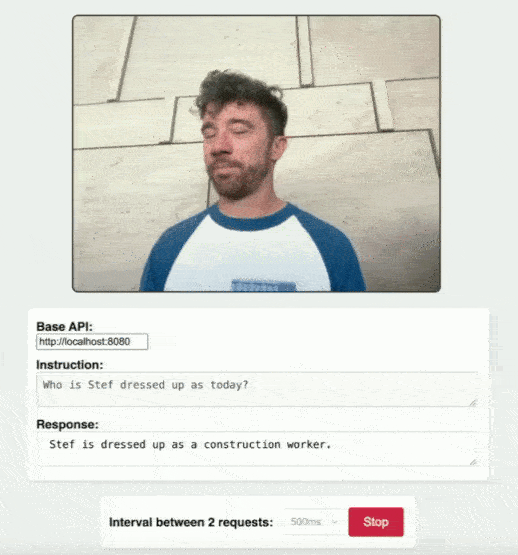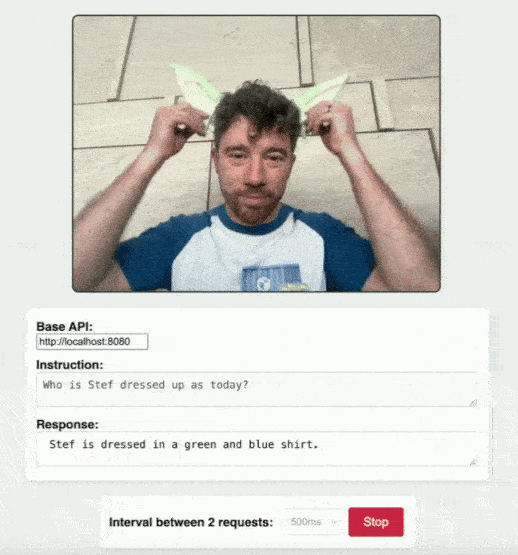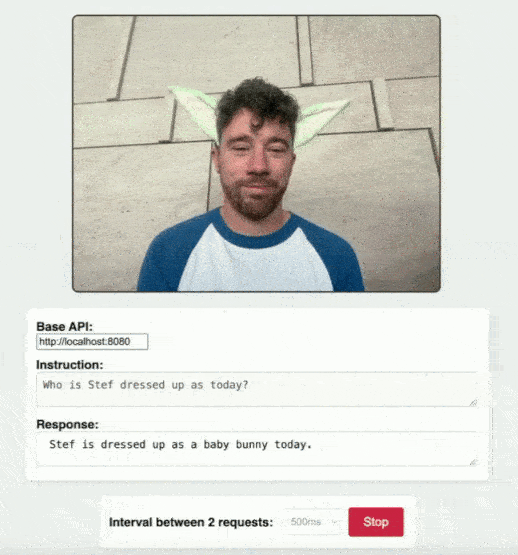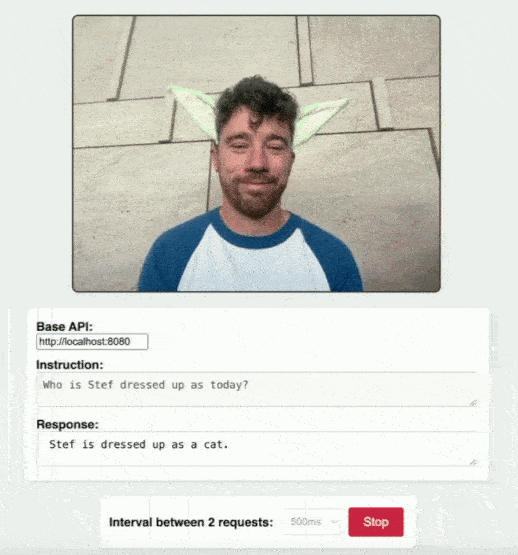
You can explore a practical example of this in action with the camera-demo.html in the RamaLama repository. This demo showcases how a simple web page can send image data to your running smolvlm instance and receive insights back, all thanks to the robust back end provided by RamaLama. See Figure 1.
The containerization magic: How RamaLama elevates llama-server
One of RamaLama’s core strengths lies in its intelligent containerization of llama-server. By default, RamaLama packages llama-server within a container, providing several key benefits:
- Portability: Your
llama-serverinstance, along with all its dependencies, is self-contained. This means you can run it consistently across different environments, from your local development machine to a production server, without worrying about dependency conflicts. - Isolation: The containerized environment ensures that
llama-serveroperates in its own isolated space, preventing interference with other applications on your system. - Scalability: With containerization, scaling your
llama-serverinstances becomes much simpler, allowing you to handle increased demand by spinning up more containers as needed. - Simplified deployment: RamaLama handles the intricacies of setting up and configuring
llama-serverwithin a container, significantly reducing the complexity of deployment for developers.
Acknowledging the foundations: llama.cpp
It's crucial to acknowledge the foundational work that makes such powerful multimodal capabilities possible. The underlying technology often relies on community efforts. In this case, much credit goes to the impressive llama.cpp project, which has been instrumental in bringing these models to a wider audience with its efficient and flexible implementation.
Furthermore, we extend our sincere gratitude to Xuan-Son Nguyen (Hugging Face) and the llama.cpp community for their invaluable contributions and dedicated efforts within the llama.cpp ecosystem. His work, and the work of many others in the open source community, are what truly drive innovation and empower developers to build incredible things.
Join the multimodal journey!
RamaLama's multimodal feature, powered by containerized llama-server and built upon the excellent work of projects like llama.cpp, represents a significant step forward for developers looking to integrate advanced AI capabilities into their applications. We encourage you to explore RamaLama, experiment with the smolvlm model, and start building the next generation of intelligent, multimodal experiences.
Head over to RamaLama to learn more and get started today! We can't wait to see what you'll create.