AMQ streams has recently promoted Cruise Control to the General Availability stage. It optimizes how Apache Kafka distributes the workload to improve performance and health. Often the Kafka clusters are deployed and grow over time, hosting multiple topics. Thanks to its robustness and elasticity reputation, the operations department tends to give it little care, monitoring the key health indicators. But they don’t know how to tune it to face the new workload.
Cruise Control can become a fundamental ally in managing your Kafka clusters and getting the most out of your hardware resources. Plus, with the AMQ streams operator, it’s just a matter of turning a key. This article explains the key principles and how to make practical use of this new exciting capability.
Unbalanced workloads
When a new topic is created in Kafka, the partitions and its replicas are distributed evenly among the available brokers in the cluster. This is a wise behavior if your cluster is empty and you have no idea of your actual workload for different partitions. Figure 1 shows an example of how eight topics with three partitions are distributed across a cluster of three brokers. Partitions belonging to the same topic have the same color.

Over time, layering multiple topics from different applications can result in partitions with different sizes and workloads. Simply increasing the size of the cluster does not solve the problem. In fact, the new cluster member will be used along with the existing ones to accommodate newly created topic partitions, but it won’t change the assignment of the existing topics.
In Figure 2, a cluster running out of resources expands with a new broker, then the user adds another topic with two partitions. New partitions are assigned in a round-robin fashion. So some will be assigned to the new broker, but the overloaded brokers are not relieved.
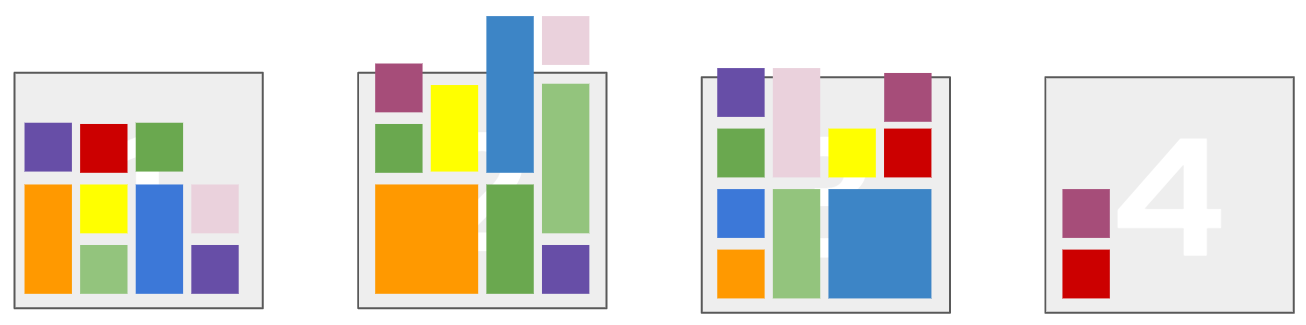
A Kafka cluster can be unbalanced from these different points of view:
- Network utilization
- RAM and CPU utilization
- Disk utilization
There are tools that allow the administrator to selectively reassign partitions across the cluster (kafka-reassign-partitions.sh), but this approach might work if there is a clear idea of the root cause of the unbalanced workload. Moreover, there are also other requirements that you need to address:
- Replicas of the same partition must be in different racks.
- All the physical resources cannot be exhausted (maximum capacity for disk, network, CPU).
Trying to improve the partition assignment manually is tedious and error prone. Moreover, when the number of options grows, the mathematical optimization theory tells us that it will also lead to poorly optimized solutions. In fact, those problems are well known as mathematical optimization problems. The theory explains that even with a limited number of variables, the search space can become so huge that even the most advanced computer would take centuries to find the optimal solution. In fact, they fall under the NP-Complete or NP-hard problems.
Fortunately, mathematicians and AI experts found methods (algorithms) to find at least a good enough solution to those problems (near optimal).
Cruise Control for Apache Kafka
LinkedIn, who originally created Apache Kafka and operates it on a large scale, developed Cruise Control to keep their clusters healthy. Then they made it open source.
Here is a summary of the key features of Kafka Cruise Control:
- Resource utilization tracking for brokers, topics, and partitions.
- Multi-goal rebalance proposal generation (subset)
- Rack-awareness
- Resource capacity violation checks (CPU, DISK, Network I/O)
- Per-broker replica count violation check
- Resource utilization balance (CPU, DISK, Network I/O)
- Leader traffic distribution
- Actualize the previous proposal:
- Rebalance the current partition topology
- Rebelance on newly added brokers
- Rebalance before removing brokers
AMQ streams makes Cruise Control truly accessible, especially within the Red Hat OpenShift Container Platform. In fact, the operator provides an easy way to deploy Cruise Control and introduces a declarative way to trigger the analysis and apply rebalance proposals.
Rebalance the cluster
Cruise Control is a sophisticated tool, with many options that allow the administrator to tailor it to his specific environment.
Before applying it to your production environment, it’s recommended to understand in detail all the features that are widely discussed in the official documentation. For this article, we’ll use the default configuration, which already provides an excellent experience with this new feature and a good understanding of the overall process.
Install Cruise Control
In the OpenShift Container Platform, enabling the Cruise Control is a matter of adding a line to your normal configuration:
oc patch kafka my-cluster --patch '{"spec":{"cruiseControl": {}}}' --type=merge
Behind the scenes, a new pod running Cruise Control is launched, and the Kafka cluster is instrumented to collect the required metrics, which are finally delivered through a set of new dedicated topics. It’s worth mentioning that to inject the metrics reporter, the Kafka pods go through a rolling update and in such a way that it preserves service continuity.
Simulate an unbalanced workload
One of the challenges with this feature is testing it in a reproducible manner, so you may be wondering how to achieve an unbalanced cluster in your test environment. A rather simple way, I found, is to develop a Kafka producer that intentionally generates loads against a subset of partitions whose leader is hosted on a particular broker. In fact, the broker that is the leader for a given partition is much more stressed than those that act as partition followers. Monitoring the CPU and network, you should get something that resembles Figure 3.
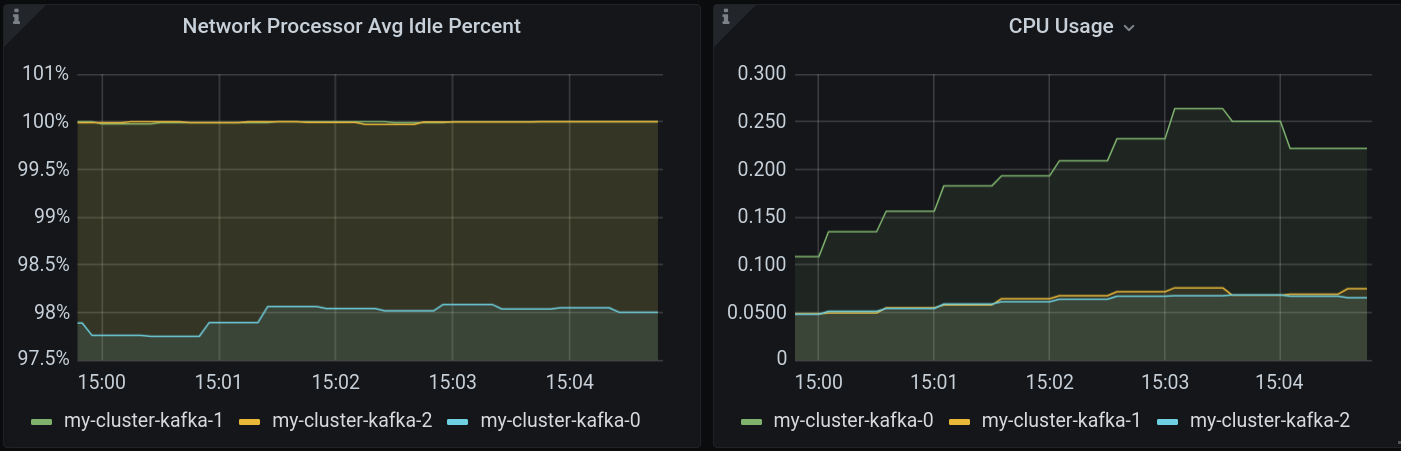
In Figure 3, the broker named my-cluster-kafka-0 differs from the others in both graphs. It scores less in the Network Idle graph, while it scores more in the CPU Usage graph.
Start rebalancing
The following is a simple procedure to engage the Cruise Control and rebalance the cluster:
Deploy a basic rebalance configuration:
echo " apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaRebalance metadata: name: full-rebalance labels: strimzi.io/cluster: my-cluster spec: {} " | oc apply -f -When
KafkaRebalanceis deployed, the Cruise Control immediately analyzes the Kafka metrics and prepares an optimization proposal. In fact, the following command showsTrueunder thePROPOSALREADYcolumn:oc get kafkarebalance NAME CLUSTER PENDINGPROPOSAL PROPOSALREADY REBALANCING READY NOTREADY full-rebalance my-cluster TrueTo finally kick off the optimization, you need to approve the proposal by annotating the
KafkaRebalanceresource:oc annotate kafkarebalance full-rebalance strimzi.io/rebalance=approveIf you want to trigger the rebalance directly without any further approval step, you can add the following annotation:
oc annotate kafkarebalance full-rebalance strimzi.io/rebalance-auto-approval=trueAfter a few minutes, to collect enough data and stabilize the workload, you should be able to evaluate the results as shown in Figure 4, where the lines of the different cluster members tend to equalize.
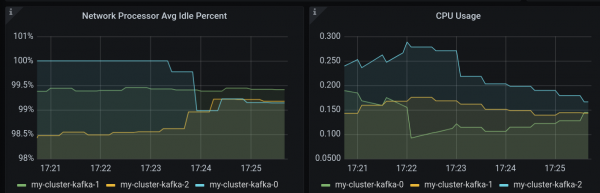
Figure 4: The CPU and network chart in Grafana after rebalance.
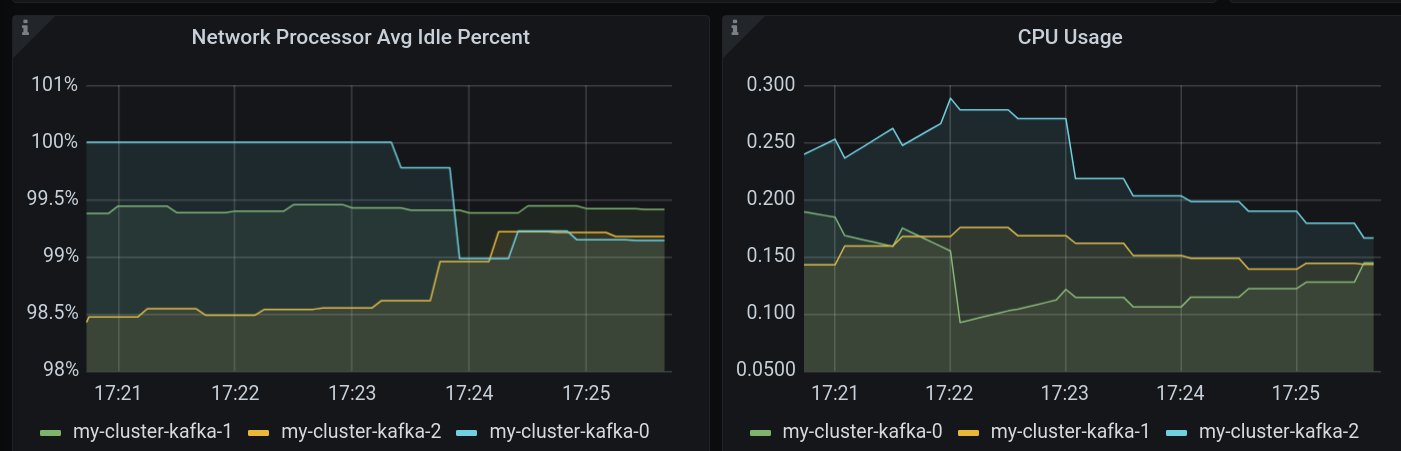
Scale up and rebalance
Let’s consider the situation where you need to scale out the current cluster and take immediate advantage of the newly added broker.
Scale out the Kafka cluster:
oc patch kafka my-cluster --patch '{"spec":{"kafka": {"replicas": 4}}}' --type=mergeThe following configuration will ask the Cruise Control to redistribute the workload by explicitly taking the new cluster member into account:
echo " apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaRebalance metadata: name: add-brokers-rebalance labels: strimzi.io/cluster: my-cluster spec: mode: add-brokers brokers: [3] " | oc apply -f -The previous
KafkaRebalanceintroduced two newspecproperties:mode: add-brokersandbrokers: [3]. Their purpose is to make Cruise Control aware of the existence of the newly added broker and instruct it to distribute the workload to the newcomer.Before approving the rebalance proposal, let’s understand some other details issuing
oc describe kafkarebalance add-brokers-rebalance:(...) Data To Move MB: 17 Excluded Brokers For Leadership: Excluded Brokers For Replica Move: Excluded Topics: Intra Broker Data To Move MB: 0 Monitored Partitions Percentage: 100 Num Intra Broker Replica Movements: 0 Num Leader Movements: 0 Num Replica Movements: 89 On Demand Balancedness Score After: 80.87946050436929 On Demand Balancedness Score Before: 76.41773549482696 (...)It indicates that is going to move 17MB of data and 89 partition replicas. This will lead to a scoring improvement of around four points.
You might wonder about the score value. The optimization algorithms translate the different goals into mathematical functions that measure how good a solution is with respect to the given goals. So the number alone doesn’t mean much, but you should expect that the scoring after optimization is increased. For the sake of accuracy, not all the Cruise Control actions contribute to the score. Therefore, the rebalancing activity may improve the health of the cluster, even if the score does not change.
Approve the optimization:
oc annotate kafkarebalance add-brokers-rebalance strimzi.io/rebalance=approve
Later on, if you want to repeat the analysis and then trigger a new optimization, all you have to do is add another annotation:
oc annotate kafkarebalance add-brokers-rebalance strimzi.io/rebalance=refresh
In a production environment, the rebalancing process might take some time, but the cluster remains operational. Your clients could experience a brief pause (a few seconds) as their partitions move elsewhere and they have to reestablish communication with a new broker. However, you may prefer to rebalance when the load is lighter. In these cases, if the rebalancing is taking too long and the peak time is approaching, you can stop the ongoing optimization. The rebalancing effort is broken down into a series of concatenated batches. So when a stop is needed, the following annotation informs the Cruise Control that the next batch must not start, whereas the running one is completed:
oc annotate kafkarebalance add-brokers-rebalance strimzi.io/rebalance=stop
If you want to test this feature in your demo environment, you can follow the detailed instructions of my AMQ streams demo project on GitHub. It will guide you through a Kafka cluster deployment using the Grafana dashboard to inspect the workload. Then you will run an application capable of generating an unbalanced load, and finally you will ponder the advantages of the rebalancing.
Explore Kafka Cruise Control benefits
Cruise Control is a valuable companion to Kafka, especially as your environment matures and evolves. AMQ streams makes it easy to take advantage of its many benefits, so it’s definitely worth adding it to your cluster. Clearly, before deploying it into a production environment, I recommend reading the official documentation, understand the available options (e.g., filtering out rebalancing goals), and monitor the reassignment closely.
Last updated: October 25, 2024