The Red Hat OpenStack Platform is an Infrastructure-as-a-Service (IaaS) offering from Red Hat. Version 17.0 of the platform includes dynamic routing for both the control and data planes. This lets you deploy a cluster in a pure layer-3 (L3) data center, overcoming the scaling issues of traditional layer-2 (L2) infrastructures such as large failure domains, large broadcast traffic, or long convergence times in the event of failures.
This article will illustrate this new feature by outlining a simple three-rack spine and leaf topology, where the layer-2 boundaries are within each rack on the Red Hat OpenStack Platform. The control plane spans the three racks, and each rack also hosts a compute node. Figure 1 illustrates our topology.

The main characteristics of this deployment are:
- Border Gateway Protocol (BGP) is running on every element in the network: controllers, computes, leaves, and spine. The Red Hat OpenStack Platform uses FRRouting (FRR) to enable BGP in the overcloud nodes, and it operates here as follows:
- Leaves are configured as route reflectors, re-advertising learned routes to the spine.
- The IPv6 link-local address of each interface uses BGP Unnumbered to establish BGP sessions. There is no need to assign and configure unique IP addresses on these interfaces, simplifying the deployment.
- FRR advertises all local IP addresses (that is, /32 on IPv4 or /128 on IPv6) as directly connected host routes.
- Each device has outgoing default equal-cost multi-path routing (ECMP) routes for load balancing and high availability (no L2 bonds).
- Bidirectional Forwarding Detection (BFD), which is configurable, is used for network failure detection for fast convergence times.
- OpenStack Neutron and Open Virtual Network (OVN) are agnostic and require no changes or configuration.
Constraints and limitations
Before we move on, it's worth noting the constraints and limitations of the implementation shown in this article:
- This feature will only work with the Neutron ML2/OVN mechanism driver.
- Workloads in provider networks and floating IP addresses are advertised. Routes to these workloads go directly to the compute node hosting the virtual machine (VM).
- Tenant networks can optionally be advertised, but:
- Overlapping CIDRs are not supported. Tenants need to ensure uniqueness (e.g., through the use of address scopes).
- Traffic to workloads in tenant networks traverses the gateway node.
- An agent is required to run on each overcloud node. This agent is responsible for steering the traffic to or from the OVN overlay, as well as triggering FRR to advertise the IPv4 or IPv6 addresses of the workloads.
- The provider bridge (typically
br-exorbr-provider) is not connected to a physical NIC or bond. Instead, egress traffic from the local VMs is processed by an extra routing layer in the Linux kernel. Similarly, ingress traffic is processed by this extra routing layer and forwarded to OVN through the provider bridge. - There is no support for datapath acceleration, because the agent relies on kernel networking to steer the traffic between the NICs and OVN. Acceleration mechanisms such as Open vSwitch with DPDK or OVS hardware offloading are not supported. Similarly, SR-IOV is not compatible with this configuration because it skips the hypervisor.
Control plane
With this configuration, the control plane no longer has to be in the same L3 network as the endpoints, because endpoints are advertised via BGP and traffic is routed to the nodes hosting the services.
High availability (HA) is provided fairly simply. Instead of announcing the VIP location upon failover by sending broadcast GARPs to the upstream switch, Pacemaker just configures the VIP addresses in the loopback interface, which triggers FRR to advertise a directly connected host route to it.
Sample traffic route
Let's take the example of the control plane's HAproxy endpoint and check its Pacemaker configuration:
[root@ctrl-1-0 ~]# pcs constraint colocation config
Colocation Constraints:
ip-172.31.0.1 with haproxy-bundle (score:INFINITY)
[root@ctrl-1-0 ~]# pcs resource config ip-172.31.0.1
Resource: ip-172.31.0.1 (class=ocf provider=heartbeat type=IPaddr2)
Attributes: cidr_netmask=32 ip=172.31.0.1 nic=lo
Meta Attrs: resource-stickiness=INFINITY
Operations: monitor interval=10s timeout=20s (ip-172.31.0.1-monitor-interval-10s)
start interval=0s timeout=20s (ip-172.31.0.1-start-interval-0s)
stop interval=0s timeout=20s (ip-172.31.0.1-stop-interval-0s)
[root@ctrl-1-0 ~]# ip addr show lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet 172.31.0.1/32 scope global lo
valid_lft forever preferred_lft forever
...
After Pacemaker configures the VIP in one of the nodes, it configures this IP address in the lo interface, triggering FRR to advertise a directly connected route on that node:
[root@ctrl-1-0 ~]# podman exec -it frr vtysh -c "show ip bgp" | grep 172.31.0.1
*> 172.31.0.1/32 0.0.0.0 0 0 32768 ?
Now we can explore the route to this IP address, which is hosted by ctrl-1-0, from the leaf-2-1 leaf node in rack-2:
# for i in leaf-2-1 spine-2 spine-1 leaf-1-1 leaf-1-2; do ssh $i ip route show 172.31.0.1; done
Warning: Permanently added 'leaf-2-1' (ECDSA) to the list of known hosts.
172.31.0.1 nhid 330 proto bgp metric 20
nexthop via inet6 fe80::5054:ff:fefe:158a dev eth2 weight 1
nexthop via inet6 fe80::5054:ff:fe55:bdf dev eth1 weight 1
Warning: Permanently added 'spine-2' (ECDSA) to the list of known hosts.
172.31.0.1 nhid 161 proto bgp metric 20
nexthop via inet6 fe80::5054:ff:feb4:d2d0 dev eth3 weight 1
nexthop via inet6 fe80::5054:ff:fec5:7bad dev eth2 weight 1
Warning: Permanently added 'spine-1' (ECDSA) to the list of known hosts.
172.31.0.1 nhid 439 proto bgp metric 20
nexthop via inet6 fe80::5054:ff:fe6f:466b dev eth3 weight 1
nexthop via inet6 fe80::5054:ff:fe8d:c63b dev eth2 weight 1
Warning: Permanently added 'leaf-1-1' (ECDSA) to the list of known hosts.
172.31.0.1 nhid 142 via 100.65.1.2 dev eth3 proto bgp metric 20
Warning: Permanently added 'leaf-1-2' (ECDSA) to the list of known hosts.
172.31.0.1 nhid 123 via 100.64.0.2 dev eth3 proto bgp metric 20
Traffic directed to the OpenStack control plane VIP (172.31.0.1) from leaf-2-1 goes through either the eth1 (on spine-1) or eth2 (on spine-2) ECMP routes. The traffic continues from spine-1 on ECMP routes again to leaf-1-1 , or from spine-2 to leaf1-2. Finally, the traffic goes through eth3 to the controller hosting the service, ctrl-1-0.
High availability through BFD
As mentioned earlier, BFD is running in the network to detect network failures. In order to illustrate its operation, following the example in the previous section, let's take down the NIC in leaf-1-1 that connects to the controller node, and see how the routes adjust on the spine-1 node to go through the other leaf in the same rack.
Initially, there is an ECMP route in the spine-1 node to the VIP that sends the traffic to both leaves in rack 1:
[root@spine-1 ~]# ip route show 172.31.0.1
172.31.0.1 nhid 179 proto bgp metric 20
nexthop via inet6 fe80::5054:ff:fe6f:466b dev eth3 weight 1
nexthop via inet6 fe80::5054:ff:fe8d:c63b dev eth2 weight 1
Now let's bring down the interface that connects leaf-1-1 to ctrl-1-0, which is hosting the VIP:
[root@leaf-1-1 ~]# ip link set eth3 down
The BFD state changes to down for this interface, and the route has been withdrawn in the spine, which now goes only through leaf-1-2:
[root@leaf-1-1 ~]# tail -f /var/log/frr/frr.log | grep state-change
2022/09/08 12:14:47 BFD: [SEY1D-NT8EQ] state-change: [mhop:no peer:100.65.1.2 local:100.65.1.1 vrf:default ifname:eth3] up -> down reason:control-expired
[root@spine-1 ~]# ip route show 172.31.0.1
172.31.0.1 nhid 67 via inet6 fe80::5054:ff:fe6f:466b dev eth3 proto bgp metric 20
Similarly, if we bring up the interface again, BFD will detect this condition and the ECMP route will be re-installed.
The newly introduced frr container runs in all controller, network, and compute nodes. Its configuration can be queried through the following command:
$ sudo podman exec -it frr vtysh -c 'show run'
Data plane
The data plane refers here to the workloads running in the OpenStack cluster. This section describes the main pieces introduced in this configuration to allow VMs to communicate in a Layer-3 only datacenter.
OVN BGP Agent
The OVN BGP Agent is a Python-based daemon that runs on every compute and network node. This agent connects to the OVN southbound database and keeps track of when a workload is spawned or shut down on a particular hypervisor. The agent then triggers FRR to advertise or withdraw its IP addresses, respectively. The agent is also responsible for configuring the extra routing layer between the provider bridge (br-ex or br-provider) and the physical NICs.
BGP advertisement
The same principle shown earlier for the control plane applies to the data plane. The difference is that for the control plane, Pacemaker configures the IP addresses to the loopback interface, whereas for the data plane, the OVN BGP Agent adds the addresses to a local VRF. The VRF is used for isolation, because we don't want these IP addresses to interfere with the host routing table. We just want to trigger FRR to advertise and withdraw the addresses as appropriate (Figure 2).
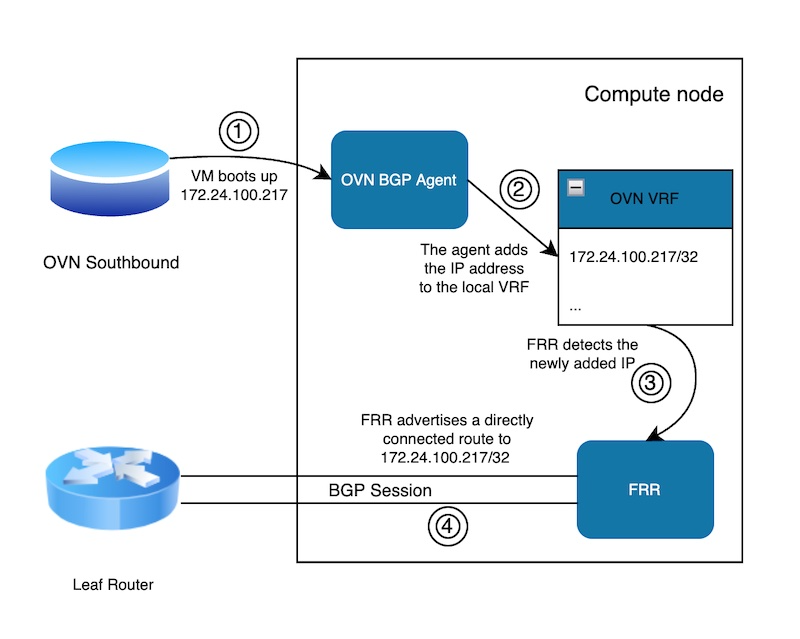
Traffic routing
As mentioned earlier, OVN has not been modified in any way to support this configuration. Thus, OVN believes that the L2 broadcast domain of the provider networks spans multiple hypervisors, but this is not true anymore. Both ingress and egress traffic require an extra layer of routing. The OVN BGP Agent is responsible for configuring this layer through the following actions:
-
Enable an ARP/NDP proxy in the provider bridge. Requests don't hit the destination because there's no L2 connectivity, so they're answered locally by the kernel:
$ sysctl net.ipv4.conf.br-ex.proxy_arp net.ipv4.conf.br-ex.proxy_arp = 1 $ sysctl net.ipv6.conf.br-ex.proxy_ndp net.ipv6.conf.br-ex.proxy_ndp = 1 -
For ingress traffic, add host routes in the node to forward the traffic to the provider bridge:
$ sudo ip rule show | grep br-ex 32000: from all to 172.24.100.217 lookup br-ex $ sudo ip route show table br-ex default dev br-ex scope link 172.24.100.217 dev br-ex scope link -
For egress traffic, add flows that change the destination MAC address to that of the provider bridge, so that the kernel will forward the traffic using the default outgoing ECMP routes:
$ ip link show br-ex 7: br-ex: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 3e:cc:28:d7:10:4e brd ff:ff:ff:ff:ff:ff $ sudo ovs-ofctl dump-flows br-ex cookie=0x3e7, duration=48.114s, table=0, n_packets=0, n_bytes=0, priority=900,ip,in_port="patch-provnet-b" actions=mod_dl_dst:3e:cc:28:d7:10:4e,NORMAL cookie=0x3e7, duration=48.091s, table=0, n_packets=0, n_bytes=0, priority=900,ipv6,in_port="patch-provnet-b" actions=mod_dl_dst:3e:cc:28:d7:10:4e,NORMAL cookie=0x0, duration=255892.138s, table=0, n_packets=6997, n_bytes=1368211, priority=0 actions=NORMAL $ ip route show default default nhid 34 proto bgp src 172.30.2.2 metric 20 nexthop via 100.64.0.5 dev eth1 weight 1 nexthop via 100.65.2.5 dev eth2 weight 1
This example is for a VM on a provider network and applies as well to Floating IP addresses. However, for workloads in tenant networks, host routes are advertised from network and compute nodes using the Neutron gateway IP address as the next hop. From the gateway node, the traffic reaches the destination compute node through the Geneve tunnel (L3) as usual.
References
More information can be found at: