It has not been that long since pip, the Python package installer, introduced a new resolver. A resolver is a critical piece of programming infrastructure, responsible for locating and selecting versions of packages to use when building an application. The new pip resolver uses a backtracking algorithm that works considerably better than the old one, according to community feedback.
This article introduces a new cloud-based Python dependency resolver created by Project Thoth. Running in the cloud, Thoth uses reinforcement learning techniques and your desired criteria to resolve Python library dependencies. Moreover, a pluggable interface lets you fix underpinning and overpinning issues (that is, where specified versions of packages are too strict or too lax) and make additional adjustments to the resolution process. The process takes into consideration the runtime environment, hardware, and other inputs to the cloud-based resolver.
Python dependency resolution
Every Python application programmer or data scientist who uses Python is familiar with pip, whose main goal is to resolve and install Python dependencies. It reads requirements and constraints, and resolves application dependencies using a backtracking algorithm.
This process downloads artifacts from Python package indexes, because pip needs to introspect package metadata and check dependency information. If the downloaded artifact does not satisfy version range requirements and does not lead to a valid resolution, the backtracking algorithm tries another resolution path that can involve downloading different versions of the same packages to look for a satisfiable path. The process can be repeated multiple times.
To streamline this iterative process and avoid the need to download libraries that can reach hundreds of megabytes in size, the Python Packaging Authority (PyPA), along with the Python community, is working on an endpoint to provide the dependency information.
Project Thoth also wants to avoid downloading large artifacts, but we take a different approach. We precompute the dependency information and store it in a form that can be queried for future resolutions. This idea led to our introducing thoth-solver, a tool that extracts dependency information from distributions (source as well as binary distributions) available on Python package indexes such as PyPI.
Note: Thoth's offline resolution also opens up the possibility of building services for testing resolved application stacks by switching different library versions that form valid dependency resolutions. See our article introducing Thoth Dependency Monkey for more information about this aspect of Project Thoth.
Thoth's resolution pipeline
Keeping the dependency information in a database, which is queried during the resolution process, allows us to choose dependencies using criteria specified by the developer instead of merely importing the latest possible versions, as pip's backtracking algorithm does. You can specify quality criteria depending on the application's traits and environment. For instance, applications deployed to production environments must be secure, so it is important that dependencies do not introduce vulnerabilities. When a data scientist trains a machine learning model in an isolated environment, however, it is acceptable to use dependency versions that are vulnerable but offer a performance gain, thus saving time and resources.
To keep the resolution process extensible, we designed it as a pipeline made of different types of pipeline units. The pipeline unit's type defines the phase when the given unit runs during the resolution process and a set of actions the unit can perform in the given resolution phase.
Recommendation types and labels
Pipeline units are grouped based on their applicability. So, for example, some pipeline units take actions that are more suitable for a vulnerability-free set of dependencies, whereas others are suitable for a highly performant set of dependencies. This is reflected in the recommendation type input option. This option selects pipeline units that are included in the resolution process dynamically on each request to the resolver, based on the semantics of the pipeline units.
Another option offers labeled requests to the resolver, which plugs in units that match requested labels.
Additional criteria
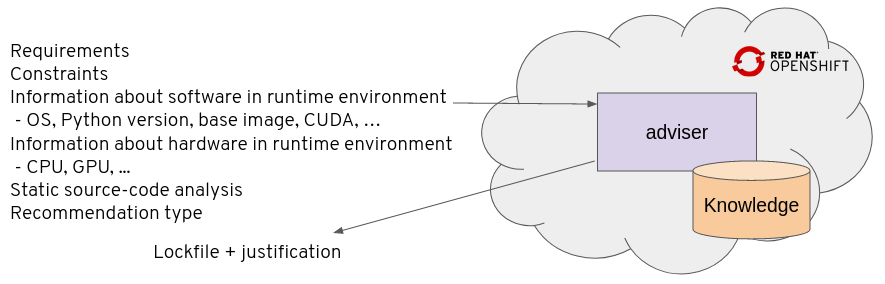
Recommendation types and labels do not provide the only criteria for incorporating pipeline units into the resolution process. Pipeline units can be specific to hardware and software available for the application. Hardware (such as the type of CPU or GPU) is a layer on top of which software environments are built, so the choice of hardware has an impact on the application. Pipeline units can specify dependencies on the software present as well. Options include:
- Python interpreter version
- Python libraries and symbols used from these libraries based on static source code analysis
- RPM packages that need to be present in the environment
- Native ABIs provided by shared objects present in the environment
- cuDNN and CUDA versions
- The base container image used to run the application (if the resolution is triggered for containerized applications)
Note: See the Project Thoth documentation for more ways to include pipeline units in the resolution process.
Figure 1 shows some of the inputs to the resolver, which are explained in the documentation for Thamos, Thoth's command-line interface (CLI).
Python interface and prescriptions
The Thoth resolver offers a programmable Python interface to developers. To create a high-level abstraction of the resolution process, we've also generalized all the pipeline-unit design patterns described in the previous section into prescriptions. Declared as YAML files, prescriptions allow the programmer to declaratively express pipeline units that should be included in the resolution process under specific conditions, as well as the actions to be taken once a unit is included.
The type of pipeline unit you use determines the actions that will be taken during the resolution process. Such actions include:
- Scoring a release of a package positively based on its positive aspects when included in a resolved software stack, such as a performance gain.
- Scoring a release of a package negatively, such as security considerations that should trigger the resolver to look for a better candidate.
- Removing certain package version combinations that introduce runtime errors.
- Fixing overpinning or underpinning issues.
- Adding Python packages that are optimized builds for a specific environment (as an example, AVX2-enabled builds of TensorFlow hosted on the AICoE Python package index).
Prescriptions can be compared to the manifest files that developers using Red Hat OpenShift or Kubernetes provide to specify the desired state of a cluster. Prescriptions offered by the cloud resolver might be seen as analogous to those manifests because prescriptions specify the desired outcome of dependency resolution. The reinforcement learning algorithm finds a solution in the form of a lockfile that respects the prescribed rules, requirements for the application, and other inputs to the recommendation engine.
The actual recommendation engine is implemented in a component called thoth-adviser that takes into account knowledge about dependencies computed by thoth-solver, as well as knowledge about the quality of software packages provided to the resolution process by pipeline units. Our prescriptions repository is an open database of prescriptions for Python projects using open source libraries.
Note: Although Thoth now provides prescriptions for most use cases, our Python interface can still be valuable for use cases that do not generalize for other packages, such as selecting a TensorFlow release based on the TensorFlow API used. See our previous article Thoth prescriptions for resolving Python dependencies for a more in-depth introduction to using prescriptions for dependency resolution.
Algorithms for dependency resolution
The resolution process described in the previous section could have reused the backtracking algorithm from pip with additional adjustments to let it work offline using pre-aggregated dependency information. In that case, the resolution pipeline could also have scored actions performed during the resolution process and adjusted the resolution based on the desired criteria. However, the design of the backtracking algorithm doesn't allow the resolver to learn from previous actions. To allow such learning, the resolution process would have to repeat resolution actions that might have been incorrect, and therefore would get no closer to resolving software packages with the desired quality.
Instead, Thoth's resolution is modeled as a Markov decision process, which we can do because it satisfies the Markov property: Any future state of the resolution process depends only upon the current state and the future actions taken, not on the sequence of preceding actions. The resolver can then learn resolution actions and their impacts when forming the final state, which is a fully pinned down set of packages that consider a dependency graph that corresponds to a lockfile. The resolver's production deployment uses temporal difference learning, respecting the Markov decision process just described.
Note: See our full video presentation from DevConf.US 2020 for more about machine learning algorithms for dependency resolution.
A reinforcement learning example
We can consider a subgraph and its impact on the resolved set of dependencies as an example that demonstrates the reinforcement learning feature.
If package A in version 1 introduces subgraph S, the resolver can learn the impact of subgraph S on the resolved stack. If we switch package A to version 2, it can introduce a subgraph S (or its parts) to the resolved stack as well. In such a case, the resolver can generalize aspects already seen in subgraph S's resolution when resolving package A in version 1 that might be applicable even for package A in version 2.
Figure 2 shows shared subgraphs across the same libraries in different versions observed during the exploration phase.
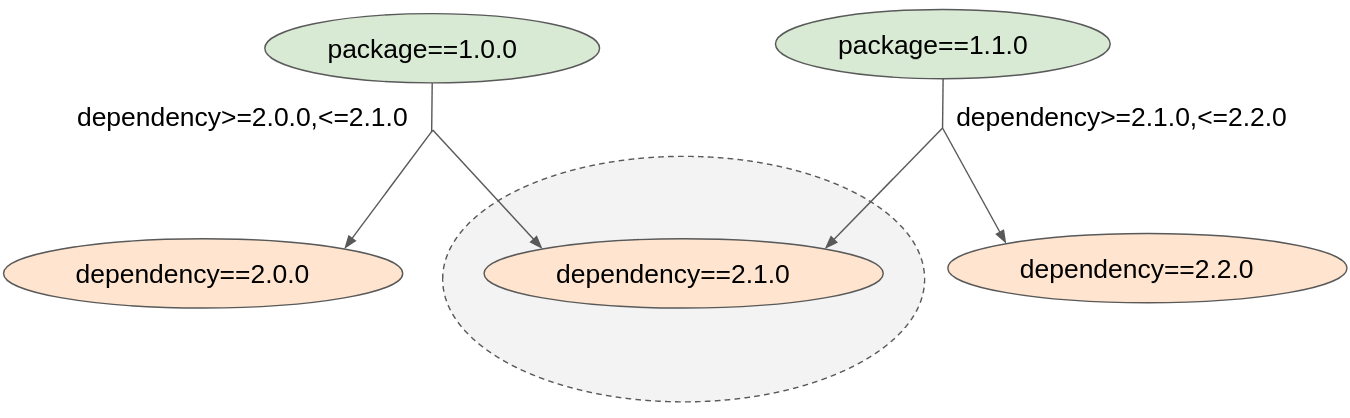
This process requires a split into exploration and exploitation phases. The exploration phase seeks out dependency resolution possibilities in the search space (the application dependency graph) and their impacts on the final resolved set of packages. The exploitation phase then uses the aspects observed during the exploration phase to come up with the set of packages that is most suitable for the application.
Keep in mind that well-known formulas balancing the exploration and exploitation phase known from game theory (such as the UCB1 formula) are not directly applicable here, because there is no opponent to play against. Instead, the resolver uses a temperature function concept adopted from adaptive simulated annealing.
The temperature starts at some high number that decreases over time. The temperature decrease takes into account the number of actions done during the resolution, the number of resolved software stacks, possibly other aspects that respect CPU time allocated, and the results computed so far. As the temperature decreases, exploration becomes less probable.
This approach has proven to help find the resolved lockfile that has desired quality in a reasonable time. (Also see this YouTube video.) When the temperature hits zero, the algorithm completely switches to the exploitation phase.
Our preparations help to keep the resolver's user experience manageable, because all the resolutions could not be computed and scored in real-time for any mid- to large-sized dependency graph. For an in-depth analysis of the resolution process, check the documentation.
How to use and extend Thoth's cloud-based resolver
If you find the technology described in this article interesting and valuable, give it a try in your applications by using Thoth.
Start by installing Thamos. This tool configures your environment and adds dependencies to your project. Then ask the resolver for recommendations. You can accomplish these tasks by entering the following in your terminal:
$ pip install thamos
$ thamos config
$ thamos add 'flask~=1.0'
$ thamos advise
About Project Thoth
As part of Project Thoth, we are accumulating knowledge to help Python developers create healthy applications. If you would like to follow updates, feel free to subscribe to our YouTube channel or follow us on the @ThothStation Twitter handle.
To send us feedback or get involved in improving the Python ecosystem, please contact us at our support repository. You can also directly reach out to us on the @ThothStation Twitter handle. You can report any issues you spotted in open source Python libraries to the support repository or directly write prescriptions for the resolver and send them to our prescriptions repository. By participating in these various ways, you can help the Python cloud-based resolver come up with better recommendations.
Last updated: September 20, 2023