One of the most difficult programming problems to diagnose and fix is when a library misbehaves because of incompatibilities with its dependencies. Fixing such issues can be time-consuming and might require developing domain knowledge about the libraries, which you should be able to treat as black boxes.
For Python programs, a solution is closer at hand thanks to Thoth, a project within the Artificial Intelligence Center of Excellence (AICOE). Thoth is a recommendation engine for building robust Python software stacks. To make sure applications are shipped in a healthy state, the Thoth team developed Dependency Monkey, which builds and runs Python applications in test environments to uncover issues involving dependencies. This article looks at the reasons for Dependency Monkey and how it operates.
Note: Also see Thoth prescriptions for resolving Python dependencies: A look at creating and using Thoth prescriptions for healthy Python applications.
About Thoth Dependency Monkey
Thoth Dependency Monkey was designed to test possible combinations of packages and libraries in Python applications. The system tries to spot issues in application stacks before application developers see them. That way, developers can focus on delivering their applications with a lower risk of being confronted with installation-time or runtime issues.
Transitive dependencies
Let’s assume, for simplicity, that we are developing a Python application that calls on two popular libraries: Pandas and TensorFlow. To install these two libraries we issue:
$ pip install pandas tensorflow
Instead of pip, we could have installed the libraries using pip-tools, Pipenv, or Poetry. All of these installers resolve packages to the latest versions, which can vary in time from one installation to the next. The code of Pandas and TensorFlow are not likely to clash, but each of these libraries relies on other libraries that bring desired functionality, such as NumPy, Protobuf, SciPy, and many others. Those packages get updated at unpredictable intervals. Because dependencies bring in other dependencies, we call the hidden ones transitive dependencies.
As of writing this article, the pip installation procedure just shown installs TensorFlow version 2.5.0 and Pandas version 1.3.1. When installing a package, you can declare a range of acceptable version ranges in library requirements (for instance, numpy>=1.17.3). It's up to the resolver algorithm to satisfy all the version ranges and bring all the required dependencies into the environment.
A new release of a library that's a transitive dependency can influence the whole dependency graph, and thus can bring in new libraries, remove libraries, or adjust the resolved library versions following requirements stated in the release.
Returning to our example, Pandas 1.3.1 requires numpy>=1.17.3, whereas Tensorflow 2.5.0 requires numpy~=1.19.2. Luckily, these requirements overlap. The resolver algorithm makes sure a version compatible with both Pandas and Tensorflow is installed.
Managing Python dependencies
Any issue involving direct or transitive dependencies can expand into numerous runtime or installation problems, especially considering the bugs in new releases and the overpinning (specifying an overly broad range of versions) that often occur in the Python ecosystem. An example of overpinning is a request for numpy>=1.20.0, which promises that the package will be compatible with any future release of NumPy. Any statements about the future create untested and unreliable obligations for third-party library maintainers who might not even know whether or how their libraries are used in other libraries, applications, or systems.
We recommend that developers pin down the whole dependency stack during application development using appropriate tools that manage a lock file. This way, the application maintainers will know how the resolved dependencies looked during the installation when they come back to the application a few weeks, months, or even years later. A lock file allows reproducible installations, or at least the ability to narrow a search for a library to compatible releases if a module goes missing from public sources such as PyPI.
One tool that helps you manage a dependency lock file is the Thoth JupyterLab extension, jupyterlab-requirements. It can manage dependencies in Jupyter notebooks. Other tools such as pip-tools, Pipenv, Poetry, and micropipenv manage dependencies from the command line. (See the article micropipenv: Installing Python dependencies in containerized applications for the advantages and disadvantages of various dependency management solutions.)
Note: To bypass the complexity of managing dependencies, we intentionally did not consider other aspects of the resolution process that can influence the resolved software stack. These aspects can include environment markers or wheel platform tags that introduce additional requirements based on the Python interpreter version, operating system, or platform used. In some cases, the resolution process might not come up with any solution if the requirements in the dependency graph are not satisfiable.
Thoth Dependency Monkey
Dependency Monkey relies on pre-computed information, stored in a database, about dependencies in Python libraries. This precomputed dependency data is obtained using thoth-solver and helps to resolve Python software stacks by considering the version range requirements that library maintainers stated when releasing their Python libraries. Unlike Python resolvers implemented in pip, Pipenv, or Poetry, thoth-adviser resolves Python software stacks offline, using the pre-aggregated dependency database. This helps to evaluate a considerably larger amount of resolved software stacks in a short period of time, in comparison to online resolvers that often have to download actual libraries to obtain dependency information during the resolution process.
The primary interface to Dependency Monkey is an endpoint that accepts inputs and creates the Dependency Monkey workflow. The input accepted on the endpoint consists of requirements on direct dependencies and a Python script that tests the resolved application. Dependency Monkey computes all the possible resolutions that can occur when resolving direct dependencies, following version range requirements declared in the whole dependency graph. The computation considers the version range requirements of both direct and transitive dependencies. Dependency information is obtained from the database and is used in the offline resolution process described earlier.
Once a valid dependency resolution is computed that satisfies the whole dependency graph, the resolved dependency stack (a lock file) is submitted to a service called Amun, which triggers “inspection” of the application stack. As part of the inspection, the application is built and run in the cluster in conformance to any software and hardware requirements (for instance, if the application must run on a specific CPU). Any installation or runtime errors that turn up are aggregated and provided to the recommender system as knowledge about Python dependencies so that users of Thoth do not encounter these issues. The Dependency Monkey process is shown in Figure 1.
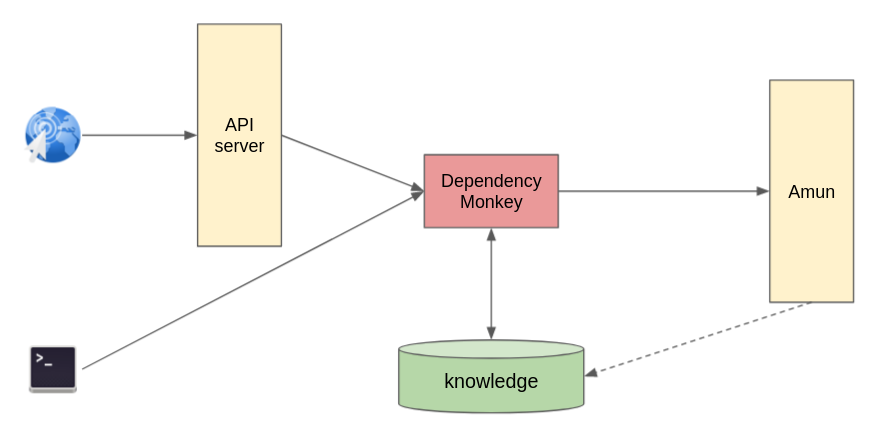
See AI software stack inspection with Thoth and TensorFlow for an example of knowledge derived from Dependency Monkey runs. The recommendation engine avoids installing versions of libraries that cause issues uncovered in that article.
Tweaking the resolution pipeline
The Thoth team designed the offline resolver to allow users to adjust the resolution process using pipeline units. The whole resolution process can be made out of pipeline units that form atomic pieces. Arguments to the resolver API can provide parameters to change the resolution process. Because the interface is pluggable, any desired changes to the resolution process can be made by implementing new pipeline units and including them in the resolution pipeline.
Sometimes, the number of all the possible combinations of resolved software stacks is too large to run experiments or too expensive to evaluate for all the stacks. In such cases, the software stack space (a state space of all the possible software stacks) can be explored through a random sampling of the state space. A subsequent pipeline configuration adjustment or changes in requirements can narrow down the resolution tests to software stacks that cause issues spotted during the sampling phase.
Another example of an adjustment consists of tests with libraries outside of the version range specification. These tests allow users of Dependency Monkey to test prereleases or nightly builds without actually patching source code and retriggering resource-expensive and possibly slow builds of the binary distributions (wheels) to be tested. Similarly, users can inject dependencies that provide the same functionality but are built with different compiler options (for example, installing AICoE optimized builds of TensorFlow with AVX2 instruction set optimizations enabled, instead of intel-tensorflow or upstream generic TensorFlow builds from PyPI).
Watch a video introduction to Dependency Monkey
To learn more about Thoth Dependency Monkey and its core mechanics, check out the following video, which also guides you through the process of generating and inspecting a software stack.
Help the Python community create healthy applications
As part of Project Thoth, we are conducting experiments with Dependency Monkey and application stacks. If you would like to get involved, please contact us, and use Dependency Monkey to test applications. We release datasets suitable for experiments on Kaggle and GitHub in thoth-station/datasets organization.
To follow updates in Project Thoth, feel free to subscribe to the Thoth Station YouTube channel or follow us on the @ThothStation Twitter handle.
Last updated: September 12, 2022