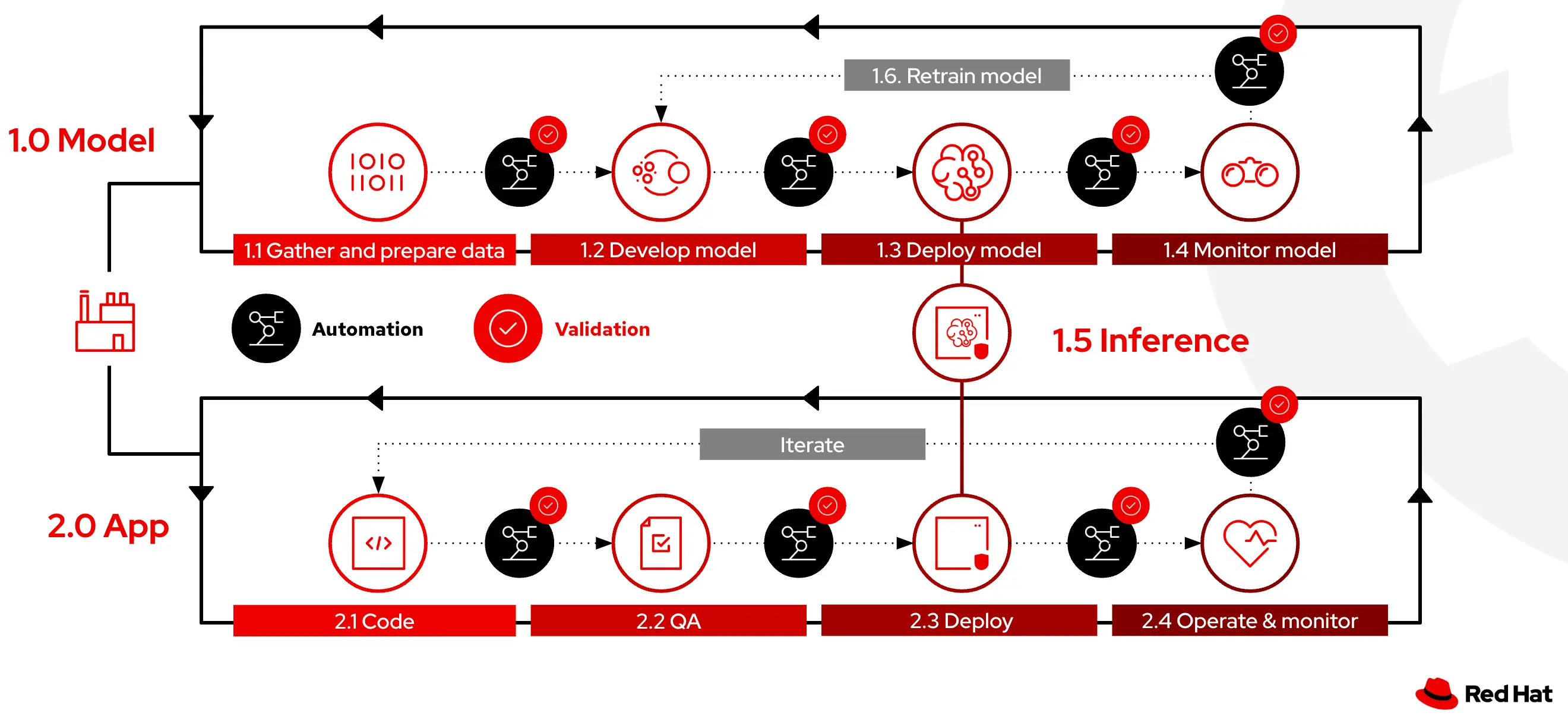
Red Hat OpenShift AI is a flexible, scalable MLOps platform built on open source technologies with tools to build, deploy, and manage AI-enabled applications. This MLOps platform provides trusted and operationally consistent capabilities for teams to experiment, serve models, and deliver innovative apps. How this platform enables the MLOps Lifecycle is explained below.

1.1 Gathering and preparing training data
In this step, data scientists import data into a specialized environment known as a workbench. This environment is designed for data science tasks and is hosted on OpenShift, offering a containerized, cloud-based workspace. Equipped with tools such as JupyterLab and libraries like TensorFlow, it also includes GPU support for data-intensive and generative AI computations. Data can be uploaded directly to the workbench, retrieved from S3 storage, sourced from databases, or streamed.
RHOAI provides:
- Pre-configured workbench images that come with libraries including Pandas for data loading from various formats (CSV, JSON, SQL), and other libraries like Matplotlib and NumPy for data visualization and preprocessing tasks.
- Extendability of its core data ingestion capabilities through the integration of specialized data processing applications such as Starburst.
- Robust data management, storage, security and compliance in combination with OpenShift, which are vital for adhering to stringent data protection standards.

1.2 Developing, augmenting, and fine tuning the model using ML frameworks
In this step, the model is trained using data that has already been cleaned and prepared. To assess how well the model performs, it is tested against specific subsets of the data designated for validation and testing. These subsets are selected from the overall dataset to check the model's effectiveness in dealing with data it has not previously encountered, ensuring it can accurately make predictions on new samples. Iteration is necessary to achieve the desired result. Data scientists typically go through several iterations of this process, refining the model by repeating the steps of data preparation, model training, and evaluation. Data scientists continue this iterative process until the model's performance metrics meet their expectations.
To support these activities, RHOAI offers:
- Specialized workbench images that come equipped with popular machine learning libraries such as TensorFlow, PyTorch, and Scikit-learn, facilitating the model development process.
- Additionally, some of these images provide access to underlying GPUs, enabling more efficient model training by significantly reducing training time.

1.3 Deploying the model to production
After the model is trained and evaluated, the model files are uploaded to a model storage location (AWS S3 bucket) using the configuration values of the data connection to the storage location. This step involves the conversion of the model into a suitable format for serving, such as ONNX. Deploying the model for serving inferences involves creating model servers that fetch the exported model from a storage location (AWS S3) using data connections, and exposing the model through a REST or a gRPC interface. To automatically run the previous series of steps, when new data is available, engineers implement data science pipelines which are workflows that execute scripts or Jupyter notebooks in an automated fashion.
RHOAI provides:
- Data science pipelines as a combination of Tekton, Kubeflow Pipelines, and Elyra.
- A choice to engineers whether they want to work at a high, visual level, by creating the pipelines with Elyra, or at a lower level, by using deeper Tekton and Kubeflow knowledge.

1.4 Monitoring model effectiveness in production
In dynamic production environments, deployed models face the challenge of model drift due to evolving data patterns. This drift can diminish the model's predictive power, making continuous monitoring essential. With RHOAI, machine learning engineers and data scientists can monitor the performance of a model in production by using the metrics gathered with Prometheus.

1.5 Delivering Inference to the application
After a model is deployed in the production environment, real world data is provided as input and through a process known as Inference, where the model calculates or generates the output. In this stage, it is of prime importance to ensure minimal latency for optimal user experience.
RHOAI delivers:
- Model inference through secure API endpoints. These APIs offer automatic scaling based on fluctuating workloads, ensuring consistent responsiveness.
- Additionally, RHOAI's integrated API gateways provide robust security for these endpoints and any sensitive data they manage, effectively preventing unauthorized access.

1.6 Retraining the model for new data
Model retraining is done based on performance metrics that are monitored in production. Since it is quite common to have dynamically changing data, it is important to standardize and automate model retraining via retraining pipelines using the Pipelines capabilities of RHOAI mentioned previously.