Let’s move on to learning how to test the accuracy of a LLM and subsequently improve it.
In order to get full benefit from taking this lesson, you need:
- A basic understanding of AI/ML, generative AI, and large language models.
In this lesson, you will:
- Test the accuracy of the LLM downloaded in the previous lesson.
- Use InstructLab to prepare new data and train the LLM to improve its accuracy.
Query the model
We’re now ready to query the model. Let’s ask a question about InstructLab and see if the model responds correctly:
>>> What is the Instructlab project?
╭──────────────────models/granite-7b-lab-Q4_K_M.gguf──────────────╮
│ Instructlab is a web-based educational software that enables instructors to create interactive online courses. It offers features such as content authoring, quizzing, grading, │
│ student management, and reporting.
╰──────────────────────────────────────── elapsed 0.641 seconds ─╯
>>> Although the model does provide a response, it is totally incorrect. This is because information about InstructLab is relatively new and the model was not trained on it. Let’s see how we can improve the Granite model to recognize InstructLab and answer questions related to it.
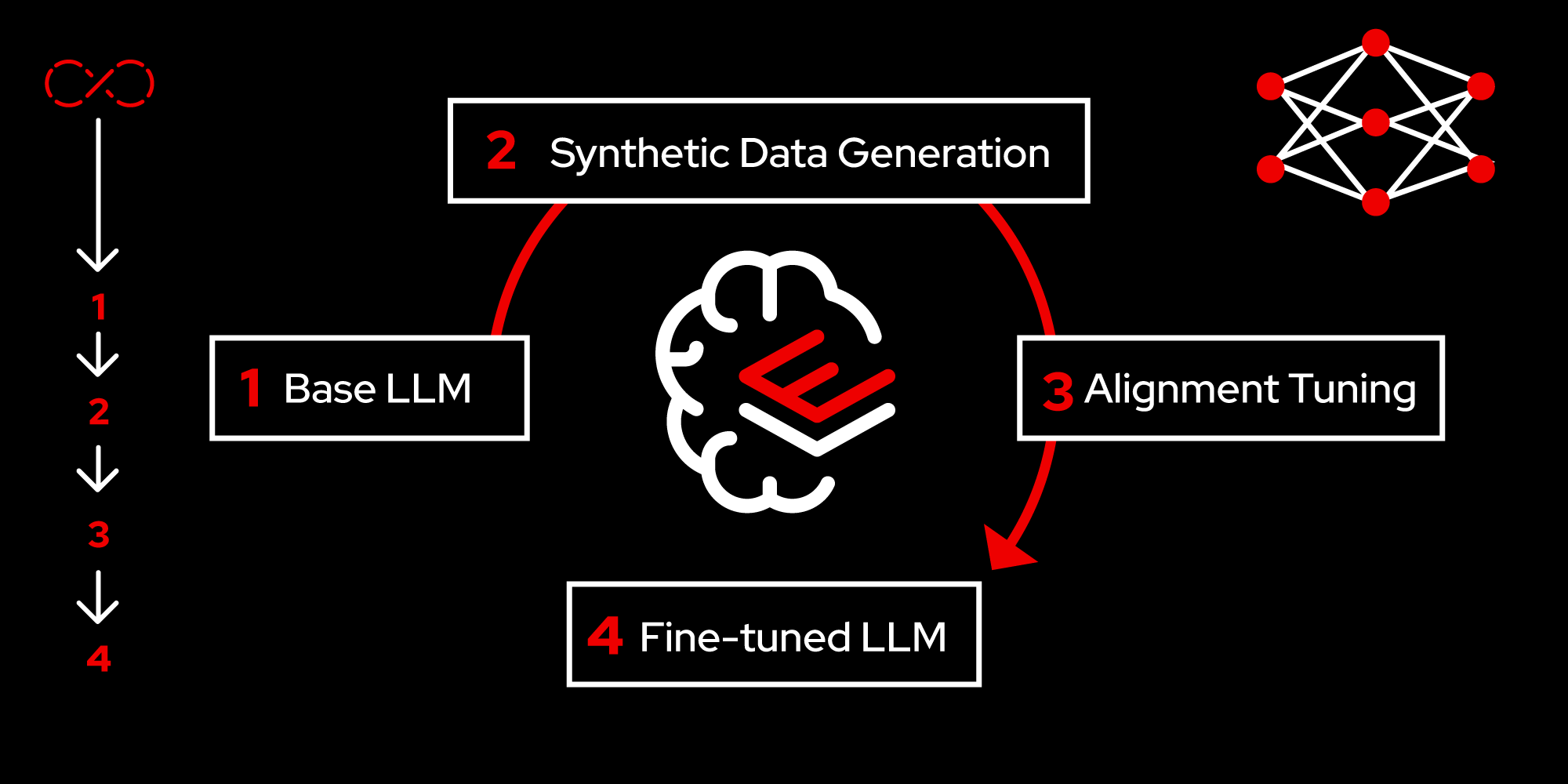
The following steps are involved in improving a LLM:
- Prepare new knowledge.
- Validate the new knowledge.
- Generate synthetic data.
- Train the model.
- Serve the new model.
- Interact with the model.
Step 1: Prepare new knowledge
Enhancing a model starts with providing enough high quality data sets to retrain the model on. Relying entirely on human provided data is not scalable. Hence, we use the approach of having users provide a minimal set of data in the form of question and answers, and then we use a teacher model (LLM) to generate synthetic data from the given data set. In simple terms, the teacher model uses the given set of questions and extrapolates it to a much larger data set.
First, we add sample knowledge on InstructLab in the form of simple questions and answers stored in a YAML format. Create the qna.yaml (if it does not already exist in the repo) with the content as shown below:
(venv) [instruct@instructlab instructlab]$ mkdir -p ~/instructlab/taxonomy/knowledge/instructlab/overview
(venv) [instruct@instructlab instructlab]$ cp -av ~/files/qna.yaml ~/instructlab/taxonomy/knowledge/instructlab/overview
'/home/instruct/files/qna.yaml' -> '/home/instruct/instructlab/taxonomy/knowledge/instructlab/overview/qna.yaml'
(venv) [instruct@instructlab instructlab]$
(venv) [instruct@instructlab instructlab]$ cat ~/instructlab/taxonomy/knowledge/instructlab/overview/qna.yaml
created_by: instructlab-team
domain: instructlab
seed_examples:
- answer: InstructLab is a model-agnostic open source AI project that facilitates contributions to Large Language Models (LLMs). We are on a mission to let anyone shape generative AI by enabling contributed updates to existing LLMs in an accessible way. Ourcommunity welcomes all those who would like to help us enable everyone to shape the future of generative AI.
question: What is InstructLab?
- answer: Check out the Instructlab Community README to get started with using and contributing to the project. If you want to jump right in, head to the InstructLab CLI documentation to get InstructLab set up and running. Learn more about the skills and knowledge you can add to models. You may wish to read through the project's FAQ to get more familiar with all aspects of InstructLab. You can find all the ways to collaborate with project maintainers and your fellow users of InstructLab beyond GitHub by visiting our project collaboration page.
question: How to get started with InstructLab
- answer: There are many projects rapidly embracing and extending permissively licensed AI models, but they are faced with three main challenges like Contribution to LLMs is not possible directly. They show up as forks, which forces consumers to choose a “best-fit” model that is not easily extensible. Also, the forks are expensive for model creators to maintain. The ability to contribute ideas is limited by a lack of AI/ML expertise. One has to learn how to fork, train, and refine models to see their idea move forward. This is a high barrier to entry. There is no direct community governance or best practice around review, curation, and distribution of forked models.
question: What problems is Instructlab aiming to solve?
- answer: InstructLab was created by Red Hat and IBM Research.
question: Who created Instructlab?
- answer: The project enables community contributors to add additional "skills" or "knowledge" to a particular model. InstructLab's model-agnostic technology gives model upstreams with sufficient infrastructure resources the ability to create regular builds of their open source licensed models not by rebuilding and retraining the entire model but by composing new skills into it. The community welcomes all those who would like to help enable everyone to shape the future of generative AI.
question: How does Instructlab enable community collaboration?
- answer: Yes, InstructLab is a model-agnostic open source AI project that facilitates contributions to Large Language Models (LLMs).
question: Is Instructlab an open source project?
- answer: InstructLab uses a novel synthetic data-based alignment tuning method for Large Language Models (LLMs.) The "lab" in InstructLab stands for Large-Scale Alignment for ChatBots
question: What is the tuning method for Instructlab?
- answer: The mission of instructlab is to let everyone shape generative AI by enabling contributed updates to existing LLMs in an accessible way. The community welcomes all those who would like to help enable everyone to shape the future of generative AI.
question: What is the mission of Instructlab?
task_description: 'Details on instructlab community project'
document:
repo: https://github.com/instructlab/.github
commit: 83d9852ad97c6b27d4b24508f7cfe7ff5dd04d0d
patterns:
- README.mdStep 2: Validate the new knowledge.
The sample knowledge or the YAML file needs to be validated so that it can be leveraged for synthetic data generation in the next step:
(venv) [instruct@instructlab instructlab]$ ilab diff
knowledge/instructlab/overview/qna.yaml
Taxonomy in /taxonomy/ is valid :)Step 3: Synthetic data generation
Before we generate additional data so that we have enough sample size to retrain the model, we need to use a teacher model to provide feedback for the preference tuning phase of alignment tuning.
a) Using the teacher model
The teacher model serves multiple roles: it generates questions, produces responses, and evaluates the quality of both, thereby guiding the synthetic data generation process. In this example, we are using Merlinite as the teacher model. Users can use any LLM as a teacher model. See the commands below:
(venv) [instruct@instructlab instructlab]$ ilab serve --model-path models/merlinite-7b-lab-Q4_K_M.gguf
INFO 2024-07-02 20:19:26,989 lab.py:340 Using model 'models/merlinite-7b-lab-Q4_K_M.gguf' with -1 gpu-layers and 4096 max context size.b) Generate new data
In the example below, we are generating only 5 new data points. But in practice, users need to generate a lot more depending on the accuracy required. Typically, this would be in the order of hundreds. See below:
(venv) [instruct@instructlab instructlab]$ ilab generate --num-instructions 5
Generating synthetic data using 'models/merlinite-7b-lab-Q4_K_M.gguf' model, taxonomy:'taxonomy' against http://127.0.0.1:8000/v1 server
Cannot find prompt.txt. Using default prompt depending on model-family.
0%| | 0/5 [00:00<?, ?it/s]Synthesizing new instructions. If you aren't satisfied with the generated instructions, interrupt training (Ctrl-C) and try adjusting your YAML files. Adding more examples may help.
INFO 2024-07-02 20:21:30,734 generate_data.py:506 Selected taxonomy path knowledge->instructlab->overview
Q> How can I contribute to InstructLab?
I>
A> You can contribute to InstructLab by visiting our GitHub organization page at https://github.com/instructlab, forking our repository, and submitting your contributions as pull requests. We have a set of guidelines for contributors that you should follow to make the process smoother and easier for everyone involved.
20%|██████████████ | 1/5 [00:07<00:30, 7.56s/it]INFO 2024-07-02 20:21:38,296 generate_data.py:506 Selected taxonomy path knowledge->instructlab->overview
Q> What can I do with InstructLab?
I>
A> InstructLab is a platform that allows you to make updates to existing LLMs. This means that if there's an AI model out there that you think could use some improvements, or if you have an idea for a completely new LLM, InstructLab gives you the tools and resources to bring your vision to life. By contributing your updates to InstructLab, you can help shape the future of generative AI and make a real impact on the world around you.
40%|████████████████████████████ | 2/5 [00:14<00:21, 7.04s/it]INFO 2024-07-02 20:21:44,968 generate_data.py:506 Selected taxonomy path knowledge->instructlab->overview
Q> How can I contribute to the development of LLMs in Instructlab?
I>
A> To contribute to the development of LLMs in InstructLab, you'll first need to create an account and log in. Once you're logged in, you can view and edit existing LLMs or submit your own new models for review. The InstructLab community is a great place to share ideas and collaborate with other developers who are also passionate about generative AI. So if you have a new model or update that you think could benefit the broader community, feel free to contribute it!
60%|██████████████████████████████████████████ | 3/5 [00:21<00:13, 6.99s/it]INFO 2024-07-02 20:21:51,889 generate_data.py:506 Selected taxonomy path knowledge->instructlab->overview
INFO 2024-07-02 20:22:12,824 generate_data.py:506 Selected taxonomy path knowledge->instructlab->overview
INFO 2024-07-02 20:22:15,330 generate_data.py:506 Selected taxonomy path knowledge->instructlab->overview
Q> How does InstructLab help me create new knowledge?
I>
A> InstructLab encourages users to contribute ideas and expertise to expand the capabilities of models. By doing so, you can help build more accurate and robust models that better understand your data and the world around us.
80%|████████████████████████████████████████████████████████ | 4/5 [00:56<00:18, 18.00s/it]INFO 2024-07-02 20:22:26,784 generate_data.py:506 Selected taxonomy path knowledge->instructlab->overview
INFO 2024-07-02 20:22:33,161 generate_data.py:506 Selected taxonomy path knowledge->instructlab->overview
INFO 2024-07-02 20:22:34,224 generate_data.py:506 Selected taxonomy path knowledge->instructlab->overview
Q> What is the difference between a LLM and an LLM in the InstructLab?
I>
A> The InstructLab supports two types of LLMs: General-purpose LLMs, which can be used for a variety of tasks such as chatbots, language translation, sentiment analysis, etc., and Task-specific LLMs, which are designed to perform specific tasks with high accuracy. General-purpose LLMs are trained on a diverse set of data and can handle various kinds of inputs and outputs. On the other hand, Task-specific LLMs are trained on a specialized dataset tailored to the task at hand. This results in better performance for that particular task compared to general models.
Q> What is the goal of InstructLab?
I>
A> InstructLab aims to empower developers with cutting-edge AI technologies, making it possible for them to create innovative applications and services that cater to diverse user needs. It helps in building intelligent agents that can understand complex human tasks, making interactions smoother and more engaging.
6it [01:24, 14.06s/it]
INFO 2024-07-02 20:22:55,081 generate_data.py:608 6 instructions generated, 18 discarded due to format (see generated/discarded_merlinite-7b-lab-Q4_K_M_2024-07-02T20_21_30.log), 1 discarded due to rouge score
INFO 2024-07-02 20:22:55,081 generate_data.py:612 Generation took 84.67s
(venv) [instruct@instructlab instructlab]$ Step 4: Train the model
Next, we retrain the model. This uses the newly generated data from the previous step:
(venv) [instruct@instructlab instructlab]$ ilab train
Found multiple files from `ilab generate`. Using the most recent generation.
LINUX_TRAIN.PY: NUM EPOCHS IS: 1
LINUX_TRAIN.PY: TRAIN FILE IS: generated/train_merlinite-7b-lab-Q4_K_M_2024-07-02T20_21_30.jsonl
LINUX_TRAIN.PY: TEST FILE IS: generated/test_merlinite-7b-lab-Q4_K_M_2024-07-02T20_21_30.jsonl
LINUX_TRAIN.PY: Using device 'cpu'
LINUX_TRAIN.PY: LOADING DATASETS
Generating train split: 6 examples [00:00, 183.37 examples/s]
Generating train split: 8 examples [00:00, 4561.51 examples/s]
/home/instruct/instructlab/venv/lib64/python3.11/site-packages/huggingface_hub/file_download.py:1132: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.
warnings.warn(
tokenizer_config.json: 100%|████████████████████████████████████████| 2.33k/2.33k [00:00<00:00, 28.9MB/s]
tokenizer.model: 100%|████████████████████████████████████████████████| 493k/493k [00:00<00:00, 43.8MB/s]
tokenizer.json: 100%|███████████████████████████████████████████████| 1.80M/1.80M [00:00<00:00, 26.7MB/s]
added_tokens.json: 100%|████████████████████████████████████████████████| 119/119 [00:00<00:00, 1.47MB/s]
special_tokens_map.json: 100%|██████████████████████████████████████████| 655/655 [00:00<00:00, 3.74MB/s]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
LINUX_TRAIN.PY: NOT USING 4-bit quantization
LINUX_TRAIN.PY: LOADING THE BASE MODEL
config.json: 100%|██████████████████████████████████████████████████████| 644/644 [00:00<00:00, 7.85MB/s]
model.safetensors.index.json: 100%|██████████████████████████████████| 23.9k/23.9k [00:00<00:00, 133MB/s]
model-00001-of-00003.safetensors: 100%|██████████████████████████████| 4.94G/4.94G [00:11<00:00, 414MB/s]
model-00002-of-00003.safetensors: 100%|██████████████████████████████| 5.00G/5.00G [00:18<00:00, 265MB/s]
model-00003-of-00003.safetensors: 100%|██████████████████████████████| 4.54G/4.54G [00:16<00:00, 268MB/s]
Downloading shards: 100%|██████████████████████████████████████████████████| 3/3 [00:48<00:00, 16.01s/it]
Loading checkpoint shards: 100%|███████████████████████████████████████████| 3/3 [00:01<00:00, 2.71it/s]
generation_config.json: 100%|███████████████████████████████████████████| 136/136 [00:00<00:00, 1.89MB/s]
LINUX_TRAIN.PY: Model device cpu
LINUX_TRAIN.PY: SANITY CHECKING THE BASE MODEL
..
….Step 5: Serve the new model
Serve the retrained model as follows:
(venv) [instruct@instructlab instructlab]$ ilab serve --model-path models/ggml-ilab-pretrained-Q4_K_M.gguf
INFO 2024-07-02 20:27:47,000 lab.py:340 Using model 'models/ggml-ilab-pretrained-Q4_K_M.gguf' with -1 gpu-layers and 4096 max context size.Step 6: Interact with the model
Let's ask the same question again and see if the model gets it correct:
(venv) [instruct@instructlab instructlab]$ ilab chat -m models/ggml-ilab-pretrained-Q4_K_M.gguf
╭─────────────────── system ─────────────────────────────────╮
│ Welcome to InstructLab Chat w/ MODELS/GGML-ILAB-PRETRAINED-Q4_K_M.GGUF (type /h for help) │
╰─────────────────────────────────────────────────────────╯
>>>
>>> what is the instructlab project?
╭──── models/ggml-ilab-pretrained-Q4_K_M.gguf ─────────────────────────╮
The Instructlab project is a cutting-edge research initiative driven by the community of developers who collaborate on the project. The primary goal of Instructlab is to create a robust, versatile, and accessible foundation for various generative AI applications, including text-to-text, text-to-image, and other generative tasks. This open-source platform fosters collaboration, innovation, and development across different generative AI technologies, making it easier for developers to contribute, learn, and grow together. Instructlab's collaborative spirit encourages its community members to share ideas, discuss challenges, and work towards solving them together, ultimately advancing the field of generative AI as a whole. By working together, we can create a future where generative AI technology is accessible, powerful, and
beneficial to everyone. The Instructlab community's dedication to collaboration, transparency, and open-source development has already made significant strides in the generative AI landscape, and its impact on the future of technology will continue to grow. To stay updated on the latest developments, join the community, contribute, or simply explore the platform, and help shape the future of generative AI with us!
╰─────────────────────────────────────── elapsed 4.020 seconds ─╯Congratulations, you’ve successfully improved the LLM! Now the model is more accurate in answering the questions.
We can see that RHEL AI makes it easy to interact with LLMs and enhance them with custom data while maintaining the privacy and security of user data.
Where to learn more
Check out Red Hat Enterprise Linux AI, a foundation model platform to develop, test, and run Granite family large language models for enterprise applications. Additional resources include:
If you’re interested in contributing to the InstructLab community projects, check out the InstructLab community page to get started now.
Further reading:
