Before we dive into using large language models (LLMs), let's touch upon the different stages involved in creating these models. We’ll also discuss the capabilities Red Hat Enterprise Linux AI (RHEL AI) provides when it comes to working with LLMs.
In order to get full benefit from taking this lesson, you need:
- A basic understanding of AI/ML, generative AI, and large language models.
In this lesson, you will:
- Learn about the different stages involved in LLM development.
- Understand what RHEL AI provides for LLMs.
LLM workflow stages
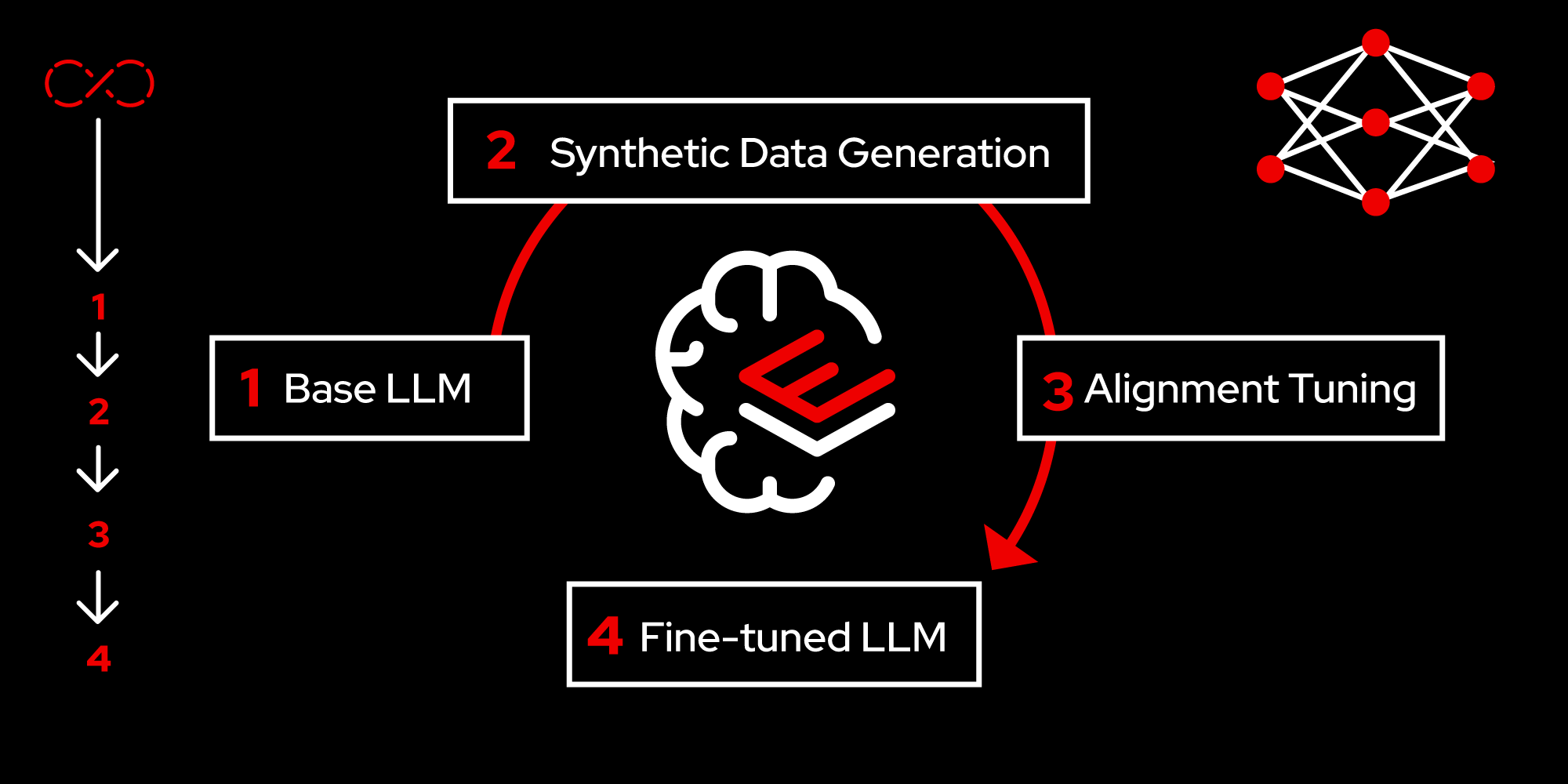
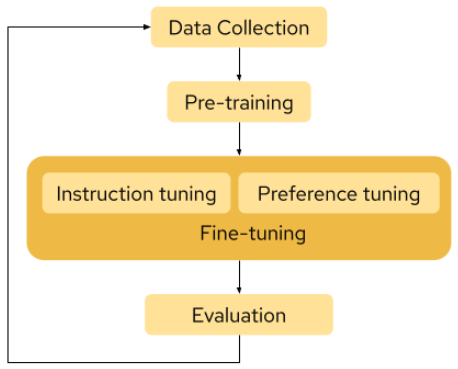
There are four main stages involved in the creation of LLMs, as shown in Figure 1.
Data collection
Large language models get their name from the vast amount of data required to train a model. This data is collected from various sources such as websites, blogs, scientific publications, books, etc. The collected data will need to be cleaned up to ensure that it is appropriate for use in training the model.
Pre-training
Pre-training refers to training a model to get a more generalized understanding of the data set and its underlying language. For example, given a word, the pre-trained model will be able to predict the next word in a sequence. This is a computationally intensive phase because the size of the data is very large and it requires a large number of accelerators to support the training.
Fine-tuning
Fine-tuning takes the model toward the next step in understanding a specific task, such as translating a sentence from one language to another, classifying the sentiment in the given text, answering questions, etc. Alignment tuning, consisting of instruction tuning and reference tuning, can also be considered phases of fine-tuning. Instruction tuning trains the model specific to a given task description or instruction. Preference tuning then aligns the model based on human feedback on the quality of the model’s responses.
RHEL AI enables users to seamlessly perform alignment tuning at scale through the InstructLab project. Because alignment tuning requires a smaller footprint of data and computational resources, RHEL AI allows users to effectively tune an LLM in a single server development environment. While InstructLab is a community project, any new knowledge or data used in the process of developing the large language model is not shared with the community. This lets users maintain data privacy and the resulting model within their secure environment.
Evaluation
Once a model is fine-tuned and ready for use, the next step is to continuously evaluate the model for accuracy and performance. If the model does not perform satisfactorily, then it is likely that the data may have changed (i.e., new data has come into the picture). At this stage, we need to retrain the model. Through InstructLab, RHEL AI enables users to automatically generate synthetic data based on samples and use it in the retraining process.
What capabilities does RHEL AI provide for LLMs?
RHEL AI provides the following capabilities:
- Access to open source-licensed LLMs fully supported and indemnified by Red Hat.
- Users can download the Granite family of large language models and experiment with them.
- Tool sets and techniques to enhance LLMs.
- Users can add new knowledge or data in the form of user-friendly YAML.
- Automatically generate synthetic data with the help of an existing foundational model and user-provided examples.
- Retrain the model using alignment tuning on the synthetic data.
- Low-cost footprint with an optimized software stack for popular hardware accelerators from vendors like AMD, Intel, and NVIDIA.
- Bootable RHEL images portable across:
- Red Hat Certified Ecosystem, including public clouds (IBM Cloud validated at developer preview).
- AI-optimized servers.
- Bootable RHEL images portable across:
- Enterprise support for the complete product lifecycle.
Now that you understand the stages involved in LLM creation, let’s move on to testing these workflows.
