A new and improved version of the Visual Studio Code XML Extension by Red Hat has been released under version 0.8.0. This new release brings new features to provide even more support for XSD-related features (the blueprint file of an XML document) along with various performance improvements.
New Features
Jump to opposite tag:
Sometimes in large documents, the opposite start/end tag can be located off the screen somewhere else, making it difficult to find. Now tags are treated as hyperlinks and, through Ctrl+click, you can now jump around from either the start or end tag to the opposite end.
CDATA and comment completion:
You can now easily complete the confusing CDATA block, along with comments.

XSD-related updates
Accurate XSD-based completion:
Prior to this release when creating an element in either an XML or XSD document the auto-completion suggestions based on XSDs were not always correct. Depending on many constraints such as minOccurs/maxOccurs, if the elements were in a sequence … the provided completion item could be invalid. In version 0.8.0, we now provide only valid elements.
See below where a sequence with 2 elements is declared but only the first one is provided for completion:
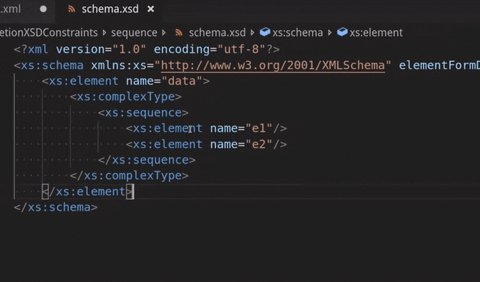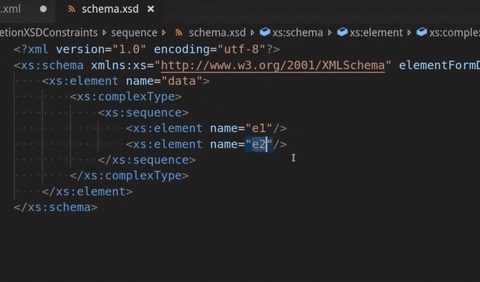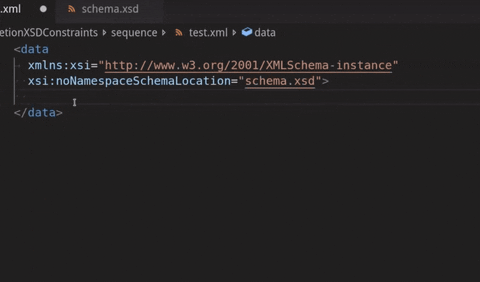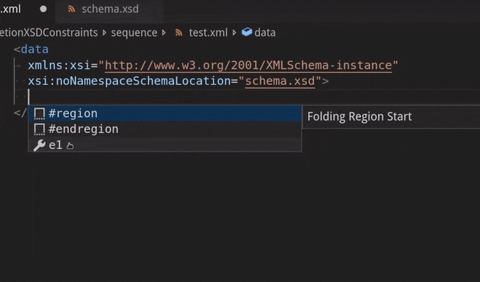
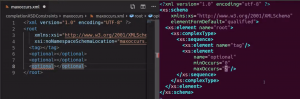
XML file validation on external XSD changes:
Originally for XML validation relative to the XSD, validation would only be triggered on an XSD change if it was open/changed internally within the VS Code application. As of this release, the server will track that XSD file externally, detect all changes, and perform the appropriate actions.
The image below shows a validation error on an XML file in VS Code after the XSD it is linked to was changed externally in vim.
Highlight a specific type in an XSD file:
In XSD files, you can reference a type, a type defines a specific XML structure that the XML document must follow. This type can be reused and applied to multiple areas in the document, which can lead to type occurrences being used all over the place. With the ability to highlight all references, users can scroll through the document and see all of these references without having to manually search for each use.

Auto-complete types in an XSD file:
After defining a type, you can start applying it to elements in the XSD file. Normally, you would have to know which types have already been defined and then type it making sure to write it correctly. This auto-complete feature now gathers all existing types and provides them through completion.
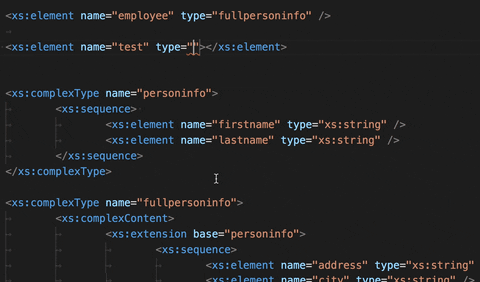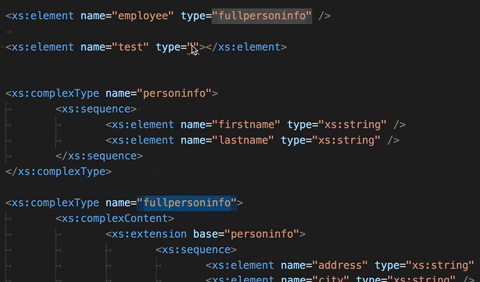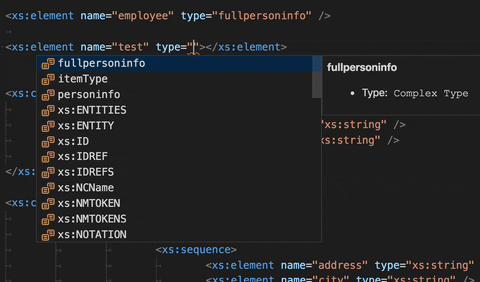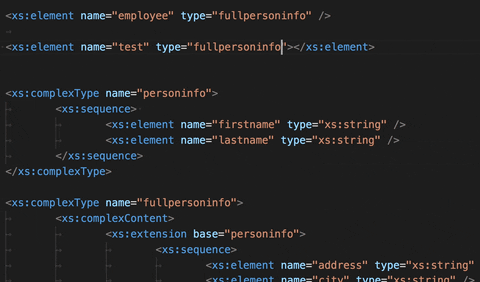
Jump to the definition of a type:
If you are in an XSD working with an element that uses a type, you might want to go to the actual definition of it to be able to see its structure. You can now Ctrl+click and go directly to the definition without having to manually search for the definition through all the other implementations.

Search the references of a type:
By selecting Find All References, you can now find all uses of the schema type. Doing so in VS Code will open up a mid-sized window that groups together all references to that type, making it easy to find and read through every use of the type.

See the number of references of a type as a CodeLens:
Similar to the Find All References, we also provide a CodeLens that is also clickable. This will bring up the same pop-up window from Find All References as well as show how many there are.

Jump to the definition of a type from the XML document:
Similar to the previous ability to go to the type definition from an XSD file, you can also right-click and select Go to Type Definition to find the type that the XML implementation references. Before you would have to figure out which element is being referenced in the XSD and then find the type definition of that element definition.

Documentation improvements
Documentation from hover and completion is provided as Markdown:
In an XSD element, documentation can be written to provide some information on that element. XML allows for the use of Markdown or HTML, and when rendering HTML it did not display well with the LSP:

With this release, the following documentation will now be properly displayed in Markdown, resulting in:

Additionally, at the bottom of the description hyperlinks to the connected XSD file are provided:

Performance improvements
This release had a focus on performance improvements, and we did just that by both decreasing memory usage and improving server speed.
Speed improvements:
To get a bit more technical, one improvement to speed was replacing the use of some regular expressions (regex) with hand-crafted java code. In this case, the regex checked for attribute names, but as you can imagine multiple attribute name regex calls during parsing could become a bit taxing. After this change, we noticed a 2-3x speed improvement on large files!
Document symbols preferences:
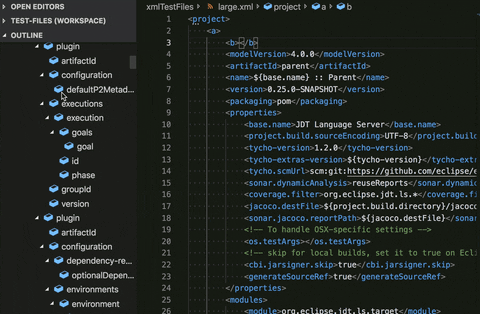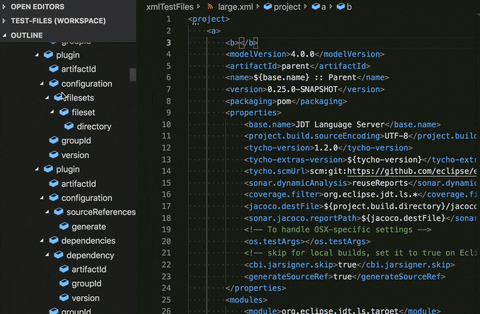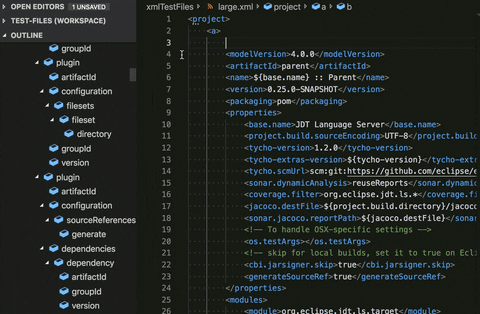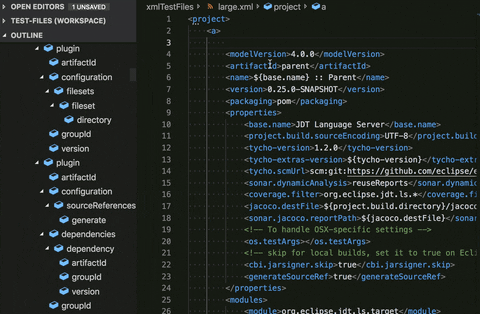
The Language Server Protocol provides a feature known as Document Symbols/Outline. On the left side of the above gif, is the Outline, which has a symbol for each significant piece in the XML document. In a large document, you will have a huge list of these symbols that will most likely be unhelpful because of the sheer amount of them. Whenever something changes in the document, these symbols have to be recalculated, which, as you can imagine for a large document, would be very penalizing.
To account for this, we’ve provided the ability to either selectively disable the Outline for files matched by a pattern or to just disable it completely. Doing so took a huge load off of the CPU and allowed for improved performance with large files.
Memory improvements:
Under the hood of the language server, we found some inefficiencies that were causing large hits to the memory; here was one of them.
Normally when a user types, a new copy of the entire document is sent to the server to be processed. As the file grows in size it is easy to see the problem with this method as a user ends up typing multiple characters continuously. Incremental Syncing is a method provided by the LSP that allows only the changed characters to be sent to the server to provide the same result with much less data being transferred. So, that’s what we did. In doing so, a large amount of memory was saved since the buffer to hold this data would only have to be enough to hold a few characters at most instead of the entire document.
Last updated: November 8, 2023