Fuse Integration Services (FIS) is a great product bringing routing (Apache Camel), SOAP and Rest services (CXF) and messaging (JMS) to the modern age of containers and PaaS and all its goodies: encapsulation, immutability, scalability and self healing. OpenShift provides the PaaS infrastructure to FIS.
A developer may implement a module in isolation on his own machine, but it often makes sense, especially when we talk about integration services, to have the code being validated in a complex integrated environment --- something that OpenShift is great at providing.
It is so easy to spawn an environment including frontend, backend and peer services that you may not want to wait for the integration test phase to see how your code performs and to identify where issues may happen. You want to see it right away, during your dev! This blog entry details a couple of workflows with their pros and cons for just doing that.
Project start
FIS provides several maven archetypes so that generating a complete working project, including a selection of modules (CXF, Camel for instance) and an already configured maven pom for generating a Docker-formatted image and pushing it into a registry is as simple as selecting a few items in dropdown lists of your favorite IDE or running a single command:
# mvn archetype:generate \
-DarchetypeCatalog=https://repo.fusesource.com/nexus/content/
groups/public/archetype-catalog.xml \
-DarchetypeGroupId=io.fabric8.archetypes \
-DarchetypeVersion=2.2.0.redhat-079 \
-DarchetypeArtifactId=java-camel-spring-archetype
When that’s done you already have a project able to build your source code, to create a container and to run it on OpenShift! You can focus on your code.
Fabric8 maven workflow
Let start with the default workflow in FIS. It consists in having maven building the Java artefacts and the container-image locally and then pushing the generated image into the OpenShift registry. This works great and it is as easy as using the "mvn -Pf8-deploy" and the "mvn fabric8:json faric8:apply" commands.
This is well explained in the documentation [1].
The advantage of this worflow is that the developer can use the same configuration to build and run the application in a pre-containers world and to have it deployed on OpenShift. That said it has a couple of requirements that may not make it suitable for every developer:
- The developer will need to have the
docker CLIavailable where the build happens (on his machine or on a server, root access is currently required) - The developer will need to have the rights to push into the OpenShift registry (or to an external registry)
These are things that may be restricted in some companies. In the future the maven forkflow may support something called binary build to work around these limitations. We will see what it is and how you can use it today in the following chapters.
Source to Image (S2I) worflow
S2I is a framework provided by OpenShift that makes it easy to create container-images from source code. The build happens directly in OpenShift so that you don’t need to have the docker CLI available locally and to remotely push to the registry.
Per default the S2I process extracts the code from your source repository, spawns a container that builds your source code, generates a container-image for your application and push it into the OpenShift registry. This is a great process, perfect for continuous integration, where you want to have a reproducible way of creating your application images.
Now looking at it from a developer point of view you may want to save a couple of steps in your development workflow and not want to commit into a git repository every change you are trying out. That’s where binary build can help you. We will look at it in the next chapter. Here is first an overview of the S2I workflow and where the time may get spent between the point where you trigger it and the point where your application is running in OpenShift. At first it may be quite disappointing as it takes a long long time but we will look at how this can be addressed.
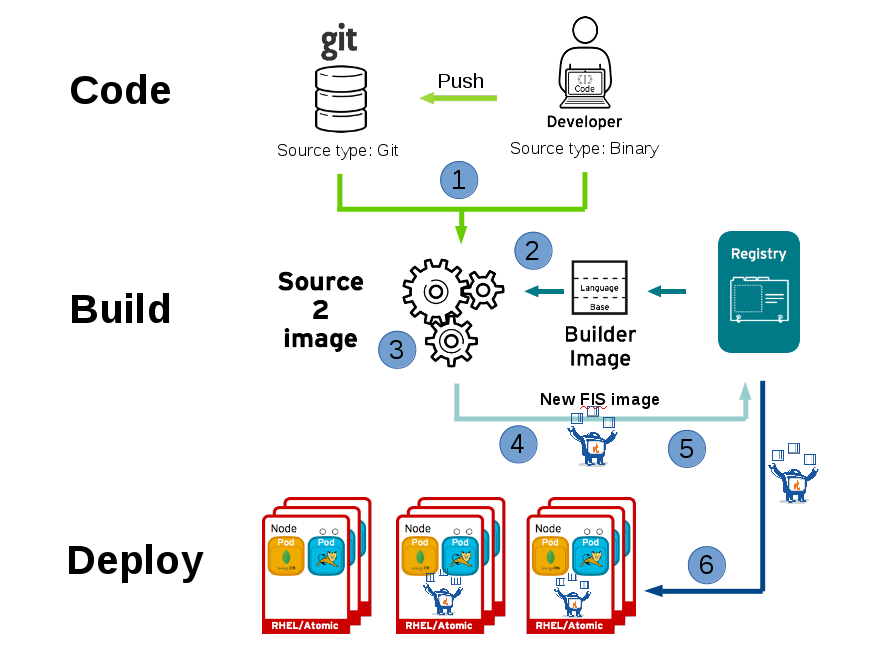
- The code is pulled from a git repository or from the developer machine after having been compressed and copied onto the S2I builder image
- The S2I builder image is pulled from the registry into the node, where the build will take place
- The maven build takes place, pulling the required dependencies and generating the application artefacts.
- A new image is created, based on the FIS S2I image and containing the application artefacts.
- The image is pushed into the OpenShift registry
- The container gets started on an OpenShift node
On my laptop running everything including OpenShift I get the following figures for the Camel Spring quickstart. You may have different values with dedicated servers but the order should still be similar.
- Copying the source code: between 1 and 16 seconds. I will explain the two values later on.
- Pulling the S2I image: 15 seconds
- Maven build: 25 minutes!
- Image build: 16 seconds
- Image push: 35 seconds
- Container start 7 seconds
Binary build
So we want to use binary build to avoid pushing our change into a git repository. Binary build consists in streaming your source code directly from your computer to the builder container. Nothing complicated and you can use the same build configuration that you use for your CI build.
Let assume that you have already created your application using the template: quickstart-template.json, provided by the maven archetype. You could have done that with the following command:
# oc new-app -f quickstart-template.json \
-p GIT_REPO=https://github.com/yourrepo/osev3-example.git
You will need to point the URL of the git repo to your own repository.
Triggering a binary build is then just a single command:
# oc start-build BUILDCONFIG --follow --from-repo=.
BUILDCONFIG needs to be replaced by the name of your build configuration.
An interesting point is that you don’t need to modify your build configuration for that. The command overwrite the source type "Git" to "Binary" behind the hood, which means that you can still use the same build configuration as in your CI process. In one case the sources are transferred from your local file system in the other case from your git server. Neat!
There are three flavour of binary builds:
- --from-dir: the files in the specified directory are streamed to the builder image. It is to note that binaries in target directory may increase time to copy the sources if the application has first been built locally
- --from-repo: the files in the local git repository are streamed to the builder image. It requires a git commit (not a push). The target directory is usually excluded through .gitignore.
- --from-file: a zip archive is streamed to the builder image
You can display the build logs with the following command:
# oc logs bc/BUILDCONFIG
In the logs you can see for instance:
I0906 10:43:10.557946 1 sti.go:581] [INFO] -------------------------------------- I0906 10:43:10.557968 1 sti.go:581] [INFO] BUILD SUCCESS I0906 10:43:10.557972 1 sti.go:581] [INFO] -------------------------------------- I0906 10:43:10.557975 1 sti.go:581] [INFO] Total time: 25:56 min
And that’s preceded by a long list of dependencies that get downloaded.
Using a maven mirror
Well, a usual way of addressing this kind of issue in the old world is to use a maven mirror, like Nexus or Artifactory, to cache the dependencies. It is not too different with OpenShift but dependency caching is critical here as the builder container does not have a pre-populated local .m2 repository (this may change in the future) and is like a new born baby every time a new build happen. You can set an environment variable so that your build uses a mirror. Therefore the build configuration can be edited and the maven mirror added under the source strategy:
"sourceStrategy": {
"from": {
"kind": "ImageStreamTag",
"namespace": "openshift",
"name": "fis-java-openshift:1.0"
},
"forcePull": true,
"env": [
{
"name": "BUILD_LOGLEVEL",
"value": "5"
},
{
"name": "MAVEN_MIRROR_URL",
"value": "nexus.ci-infra:8081/content/groups/public/"
}
If your company does not already have a maven mirror available, there is a Docker-formatted image with Nexus, which makes it possible to deploy a maven mirror in OpenShift in minutes. See this page for the details:
https://github.com/openshift/openshift-docs/blob/master/dev_guide/app_tutorials/maven_tutorial.adoc
Incremental builds
Another option to limit the amount of time required to download dependencies is using incremental builds. With incremental builds the dependencies contained in the .m2 directory get persisted at the end of the build and copied again to the builder image by the next build. You then have them locally.
A drawback of this approach compared to a maven mirror is that the artefacts are not shared between different applications, which means that your first build will still take very, very long.
To turn on incremental build, which will be activated per default with the next FIS release [2], you just need to amend the source strategy in the build configuration accordingly:
"sourceStrategy": {
"from": {
"kind": "ImageStreamTag",
"namespace": "openshift",
"name": "fis-java-openshift:1.0"
},
"forcePull": true,
"env": [
{
"name": "BUILD_LOGLEVEL",
"value": "5"
}
],
"incremental": true
Further considerations
Using a maven mirror or incremental builds we have now reduced the build time to a couple of minutes. That is totally acceptable as part of a CI process… but still not that good for a developer wanting to quickly test changes.
A few other considerations allow to further reduce the build time. The first one is nothing new. You may want to review your pom file and make sure that you need all the listed dependencies and plugins. Depending on your worflow you may for instance not need the Jolokia/docker plugin. Even if these plugins are not called during the artefact generation they have to be downloaded or copied into the builder image.
Another point to consider is that you don’t want your local target directory (and possibly others) getting streamed to the builder image. It may well be over 60 MB. If you use the --from-repo option make sure that you have .gitignore configured properly. Your git server will also thank you for that. If you use --from-dir make sure that your target directory has been cleansed before.
One step that costs around 15 seconds is that the docker-daemon running your build first downloads the latest S2I image before starting the build. You can save a bit of time by deactivating this mechanism called "force pull" in the build configuration:
"sourceStrategy": {
"from": {
"kind": "ImageStreamTag",
"namespace": "openshift",
"name": "fis-java-openshift:1.0"
},
"forcePull": false
I would however strongly recommend to have the force pull option activated as part of your integration build, which will generate your reference image. If you deactivate it in the build configuration that you use during development you will have to support two different versions of the build configuration.
Hot deployment
Independent on whether you use the maven plugin or the S2I workflow you now have a process for building and deploying a change taking a few minutes. This is similar to what you may have had in the past when developing locally and not using a PaaS. A usual solution was then to hot deploy to shorten the time to something acceptable, probably under 30 seconds. How can you achieve this with FIS running on OpenShift?
Container technologies follow the principle that an image should be immutable. It should be possible to promote an image from one environment to the next, from QA to production for instance, and be sure to have the same behaviour in both environments. Image immutability provides consistency and reproducibility. This speaks against hot deployment and that surely one reason why it has been deactivated in the Karaf base image and it is not available with Hawtapp.
This sounds reasonable to you but does not help with having short cycles for applying changes?
We have two FIS flavors, one based on the OSGi container Karaf, the other one plain java. Let look at them one after the other.
Hot deployment with Apache Karaf
Hot deployment in Karaf is simply done by dropping a file in the deploy directory. Karaf will detect it and deploy it. As mentioned earlier this mechanism is deactivated in the Karaf assemble generated by the default pom. This can easily be activated by adding a couple of lines under the configuration of the karaf-maven-plugin:
<!-- deployer and aries-blueprint are required for hot deployment during the dev phase --> <feature>deployer</feature> <feature>aries-blueprint</feature> <!-- shell and ssh are required to log in with the client during the dev phase --> <feature>shell</feature> <feature>ssh</feature>
Remember you should not have hot deployment in your reference image (the one being promoted from integration to production passing by QA and staging). Therefore it is best to create a dev profile in your pom, which is only activated on the developer machine. Again for reproducibility purpose the reference image should be created by your CI tool not manually by a developer.
So, we have now a hot deployment capable image but it has no access to your local file system. How does it work?
OpenShift has a nice feature for that: "oc rsync". It allows to copy file to or from a container. In our case:
# oc rsync ./deployment/ POD:/deployments/karaf/deploy
This will transfer the files from the local deployment directory to the container. You just need to replace POD with the real name of your pod. Have a look at "oc rsync --help" for further options.
Last point: You can simply use "oc rsh POD" to get a shell inside your container. Karaf configuration is under /deployments/karaf/etc so that you can quickly test changes. Remember once the container is restarted all changes are lost.
That’s great to try out but you can always revert to the baseline (your image) by restarting the container. To change the baseline… just use the maven plugin or the S2I worfllow.
Hot deployment with Hawtapp
Hawtapp does not support hot deployment. This means that you may need to look at hot swapping for a solution, which is outside of the scope of this blog entry. Note that OpenShift allows to open a tunnel between your local machine and the remote container thanks to the command: "oc port-forward". Use the "--help" option for the details of the command.
So yes we are not quite there with Hawtapp but the engineering team is looking at using Spring Boot for FIS 2.0 [4] and this comes with nice hot deployment and troubleshooting capabilities !
In the meantime a hybrid workflow with quick changes being tested locally and broader development tests being done in OpenShift may be the solution.
Java Console
Another nice feature of OpenShift is that it integrates a Java console for all the containers exposing a port named "jolokia", what both the Karaf and Hawtapp images do per default. This gives you access to a nice web console similar to what you have with standalone Fuse instances. From the console you can follow the messages going through the camel routes, trace them, debug your camel routes or even modify them. This is great for troubleshooting!
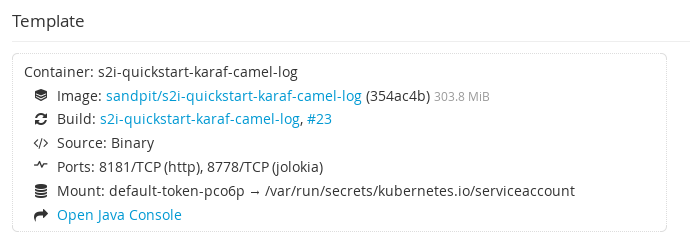
To open the Java console, follow the link "Open Java Console" in the details page of the pod in your OpenShift web console:
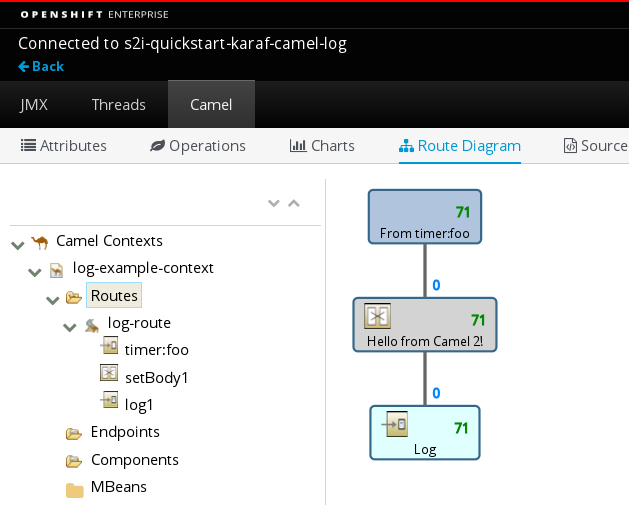
You can then display your route:
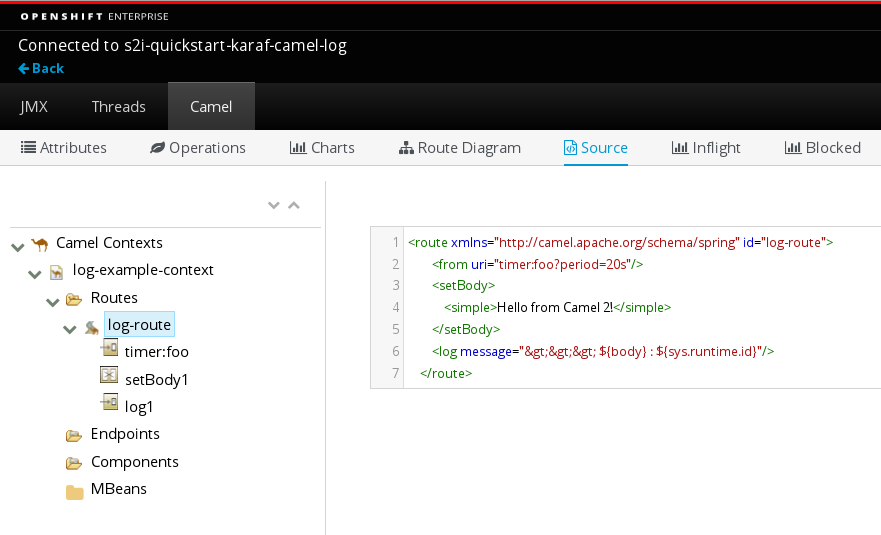
And modify the source:
I hope you enjoyed reading this blog entry and congratulations if you made it till this last sentence!
You can find the documentation for Fuse Integration Services at: https://access.redhat.com/front
Additional reading:
- Continuous integration and continuous delivery with OpenShift: https://cloud.redhat.com/blog/cicd-with-openshift
- Various options in regard of image promotion: https://github.com/openshift/origin/blob/master/docs/proposals/image-promotion.md
- Documentation of the Jenkins plugin for OpenShift: https://github.com/openshift/jenkins-plugin