As I've been using Git, SVN (with git-svn) and Hg for quite a long time now, I've adapted my way to handle the local repositories created with those tools. Especially, I quickly found out that it is quite crucial to separate those repositories from your IDE workspaces. Some explanation of why and how are in this entry.

Eclipse workspaces
To understand why I wished to write about this, one has to know that many developers - especially Java developers, are 'Eclipse folks'. This means that they use Eclipse not only to code Java but also as a SVN/CVS client, and almost anything software development related.
I used to be a bit like that, and then when I started using DVCS tools such as Git, I did the same. I used Git integration within Eclipse to checkout a project history. However, I quickly understood - like anybody who used Eclipse for more than 5s - that using one workspace was simply a mess. To help you understand the differences between centralized version control systems and DVCS, this blog post at Atlassian is pretty great.
As my job as consultant often leads me to jump from project to project, a new method needed to be found. So, I set up a convenient bunch of 'workspaces' such as 'examples' - where I stored code for some "HelloWorld" project, 'jboss' - to store projects checked out from the JBoss community, and a 'contrib' workspace - with my works on several Open Source projects, and of course, one workspace by project and/or customer.
In the meantime, I also started to use DVCS, both Mercurial (aka hg) and Git, and then also Git as a SVN client. At first, I simply added the resulting clones to those workspaces, as it seemed pretty logical. In the long run, it turns out to be rather messy. For instance, I could not have in the same workspace an Open Source project code base, from the 'contrib' workspaces, and the code base of the current customer-related project.
It is then that I realized that a cloned repository could have quite a distinct life cycle as an Eclipse 'workspace', and that I therefore needed to decouple one from the other.
Cleaning the mess
Separating repositories from workspaces
With this idea, I set up a ${HOME}/Repositories on my laptop, where I start moving all local copies of code repositories. Of course, I reused here again the same organization of before with 'contrib', 'perso', 'redhat', and so on... The only difference is that my customer's code base is living under another directory layout, where all my customer-related files go.
After this reorganization, I started systematically using Eclipse's feature that allows you to specify a folder outside the workspace:
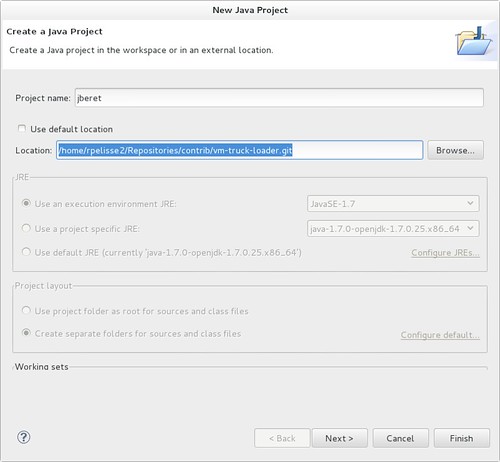
With this setup, I can easily import the required project and into several workspaces if I need to. If I end up modifying the same code base, for two different projects, I can just use the regular branch feature of my DVCS du jour, and I don't need to duplicate the code history.
Why not just locally clone the repository ?
One could definitely argue that point. Why not just clone the code base into a new repository? It's pretty easy to do and quite fast. And given how large hard drives are nowadays, who cares? Even if you do care about disk space, Git is smart enough to use hard links for the repository files, which means that each new clone is not going to duplicate the history, but only the working directory and maybe some branch data.
But the fact remains that you don't want any duplicate code bases on your laptop. You'll get in trouble and confuse yourself for sure. You will look for some code changes in the wrong repository or you'll just wonder which one is the "right one", end up being "lost in time and space."
An old lesson...
Another positive side effect of this strategy is that I can get rid of my workspaces very easily. There is nothing, but the IDE stuff in it! So if a new version of Eclipse breaks one of my workspaces, or if the version of Eclipse my customer is using is not compatible with it, no big deal! I just delete it, and re-import the project from my repositories folder.
Here, we have actually learned again the value of a very old best practice in software engineering: It's always good to separate data and configuration from code. And even with your IDE and local development environment, it's a valuable practice!
Suffixes for repositories
I've also adopted a convention something like five years ago (and to be honest, that I borrowed from my friend and former coworker Goneri Le Bouder): add a suffix to any repository with an extension matching the tool used to create it (e.g. my-proj.git)
Nowadays, where git appears to be winning the DVCS competition, one could argue it would make no sense to have such a convention, as the default would simply be git. Here again, the fact is that many, many companies still use SVN, and some even CVS, and there are a few products running on alternative tools such as Mercurial and Bazaar.
$ ls -1
pmd.git # this is a git clone of pmd
hgbook-fr.hg # a clone of the hgbook
arjuna.svn # a svn checkout of the JBoss arjuna project
arjuna.git+svn # a full copy of the project using git
This convention is rather simple to implement, and allows you to quickly see where you stand. The suffixes are also handy for scripting in general - for instance to not back those repositories up.
And if you don't like to see the .git extension in your IDE, you can always use a symlink to the file :).
Final words
What I have briefly described here is not going to change your life, but it did make mine easier :) . While I'm pretty sure there are many developers out there who would just do all this right away, I'm pretty sure some, like me at the beginning, will appreciate the "heads up". And that's why I took the time to share it here.
Last updated: February 23, 2024