Custom server tasks can be deployed to the Red Hat Data Grid server for remote execution from the command line interface (CLI) and Hot Rod or REST clients. Tasks can be implemented as custom Java classes or as scripts in languages such as JavaScript.
In this article, we will deploy a Java class that will evict and reload the cache in order to pick up modified entries in the original database table from which we loaded the cache. Data Grid will automatically load new entries added to the database table, however modified rows will require reloading using a server task, as shown in the following example.
How to deploy PostgreSQL with a custom image
SQL cache stores let you load Red Hat Data Grid caches from existing database tables. Data Grid offers two types of SQL cache stores: table and query. In the following example, Data Grid will load entries from a single database table. It is also possible to use SQL queries to load entries from single or multiple database tables.
For more details, refer to SQL cache stores. All source code for this tutorial can be found on GitHub.
We will use PostgreSQL to contain the table that will be loaded by Data Grid. To deploy PostgreSQL in Red Hat OpenShift, we will use a modified image that initializes the database with a table and a Data Grid user with granted privileges to read from the table.
FROM registry.redhat.io/rhel8/postgresql-12 LABEL description="This is a custom PostgreSQL container image which loads the database schema definitions and the data into the model and inventory tables " COPY db/load_db.sh /opt/app-root/src/postgresql-start/ COPY db/rpi-store-ddl.sql /opt/app-root/src/postgresql-start/ COPY db/rpi-store-dml.sql /opt/app-root/src/postgresql-start/ COPY db/rpi-store-role.sql /opt/app-root/src/postgresql-start/ USER root RUN chmod 774 /opt/app-root/src/postgresql-start/*.sh USER 26
The load_db.sh script populates the table used to load the Data Grid cache and creates the user infinispan with privileges to SELECT from the model table:
#!/bin/bash
START_DIR="$APP_DATA/src/postgresql-start"
run_sql_script () {
SQL_FILE=$1
psql -U postgres \
--echo-all \
-f $SQL_FILE \
-d $POSTGRESQL_DATABASE
}
run_sql_script $START_DIR/rpi-store-ddl.sql
run_sql_script $START_DIR/rpi-store-dml.sql
run_sql_script $START_DIR/rpi-store-role.sql
Note that the user needs to be postgres to create a new user.
The rpi-store-ddl.sql script will run the following SQL commands to create the model table which will be used to load keys and values into the Data Grid cache:
drop table if exists model; create table model ( id integer primary key, name varchar(20), model varchar(20), soc varchar(20), memory_mb integer, ethernet boolean, release_year integer );
The rpi-store-dml.sqlscript will create three rows in the model table:
insert into model (id, name, model, soc, memory_mb, ethernet, release_year) values (1, 'Raspberry Pi', 'B', 'BCM2835', 256, TRUE, 2012); insert into model (id, name, model, soc, memory_mb, ethernet, release_year) values (2, 'Raspberry Pi Zero', 'Zero', 'BCM2835', 512, FALSE, 2015); insert into model (id, name, model, soc, memory_mb, ethernet, release_year) values (3, 'Raspberry Pi Zero', '2W', 'BCM2835', 512, FALSE, 2021);
Finally, the rpi-store-role.sql script will create the user infinispan and grant SELECT privileges on the model table. This user will be provided to the JDBC connector used by Data Grid.
CREATE USER infinispan WITH PASSWORD 'secret'; GRANT SELECT ON model TO infinispan;
We can now deploy PostgreSQL in OpenShift using the modified image:
$ oc new-project infinispan-demo $ oc new-build \ > https://github.com/torbjorndahlen/infinispan-evict-cache \ > --strategy=docker \ > --name='postgresql-12-custom' $ oc new-app \ > -e POSTGRESQL_USER=db \ > -e POSTGRESQL_PASSWORD=secret \ > -e POSTGRESQL_DATABASE=rpi-store \ > postgresql-12-custom
After deployment is complete, we can verify that the user infinispan, the DB rpi-store, and the model table were created as expected:
$ oc get pods NAME READY STATUS RESTARTS AGE postgresql-12-custom-1-build 0/1 Completed 0 2m40s postgresql-12-custom-0 1/1 Running 0 38s $ oc exec postgresql-12-custom-0 -- psql -U infinispan -d rpi-store -c "select * from model;" id | name | model | soc | memory_mb | ethernet | release_year ----+-------------------+-------+---------+-----------+----------+-------------- 1 | Raspberry Pi | B | BCM2835 | 256 | t | 2012 2 | Raspberry Pi Zero | Zero | BCM2835 | 512 | f | 2015 3 | Raspberry Pi Zero | 2W | BCM2835 | 512 | f | 2021 (3 rows)
Server task implementation
The EvictReloadTask class implements the org.infinispan.tasks.ServerTask interface where the call() method is invoked by Data Grid when called from the Hot Rod client:
@MetaInfServices(ServerTask.class)
public class EvictReloadTask implements ServerTask, java.io.Serializable {
private static final ThreadLocal taskContext = new ThreadLocal<>();
@Override
public String call() throws Exception {
TaskContext ctx = taskContext.get();
AdvancedCache<?, ?> cache = ctx.getCacheManager().getCache("rpi-store").getAdvancedCache();
cache.withFlags(Flag.SKIP_CACHE_STORE).clear();
cache.getComponentRegistry().getComponent(PreloadManager.class).start();
return null;
}
}
Before deploying Data Grid, the server task is packaged in a JAR file containing the server task classes and a file in the META-INF/services directory. This file is named org.infinispan.tasks.ServerTask and contains the fully qualified name of the server task.
example.EvictReloadTask
You also need to add your server task classes to a deserialization allow list, since Data Grid does not allow deserialization of arbitrary Java classes for security reasons. To do this, we create a ConfigMap containing an allow-list for serializing of the server task class:
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-config
namespace: infinispan-demo
data:
infinispan-config.xml: >
<infinispan>
<cache-container>
<serialization
marshaller="org.infinispan.commons.marshall.JavaSerializationMarshaller">
<allow-list>
<class>example.EvictReloadTask</class>
</allow-list>
</serialization>
</cache-container>
</infinispan>
Then, we deploy the ConfigMap:
$ oc apply -f cluster-config.yaml
Deploy Data Grid
To deploy the Data Grid cluster in OpenShift we use the Data Grid operator.
Install the operator:
$ oc apply -f infinispan-operator.yaml $ oc apply -f subscription.yaml
In this example, we will use the following custom resource to let the operator create a Data Grid cluster:
apiVersion: infinispan.org/v1
kind: Infinispan
metadata:
name: infinispan
namespace: infinispan-demo
spec:
security:
endpointEncryption:
type: None
clientCert: None
expose:
type: LoadBalancer
dependencies:
artifacts:
- maven: 'org.postgresql:postgresql:42.3.1'
- url: >-
https://github.com/torbjorndahlen/infinispan-evict-cache/raw/main/ServerTask/server/target/ServerTask.jar
service:
type: DataGrid
replicas: 1
configMapName: cluster-config
The Maven artifact refers to the JDBC driver for PostgreSQL. The URL artifact refers to the Git repository where the server task JAR file can be downloaded.
The Data Grid cluster is created with oc create:
$ oc create -f infinispan-cr.yaml
Use oc get svc to find the URL to the Data Grid console:
$ oc get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE example-infinispan-external LoadBalancer 172.30.5.74 my_host.example.com 11222:31797/TCP 6m39s
In this example, we exposed Data Grid through a loadbalancer. The URL to the Data Grid contains the loadbalancer hostname and port. The Data Grid console can be accessed at http://my_host.example.com:11222. The console username and password is stored in the infinispan-generated-secret.
$ oc get secret infinispan-generated-secret -o jsonpath="{.data.identities\.yaml}" | base64 --decode
credentials:
- username: developer
password: my_password
roles:
- admin
Create the cache
You can use SQL stores with database tables that contain composite primary keys or composite values.
To use composite keys or values, you must provide Data Grid with protobuf schema that describe the data types. You must also add schema configuration to your SQL store and specify the message names for keys and values.
You can find more information on cache encoding and marshaling.
Using the Data Grid console, create a cache using a protobuf schema and SQL cache store configuration, as shown in Figure 1:
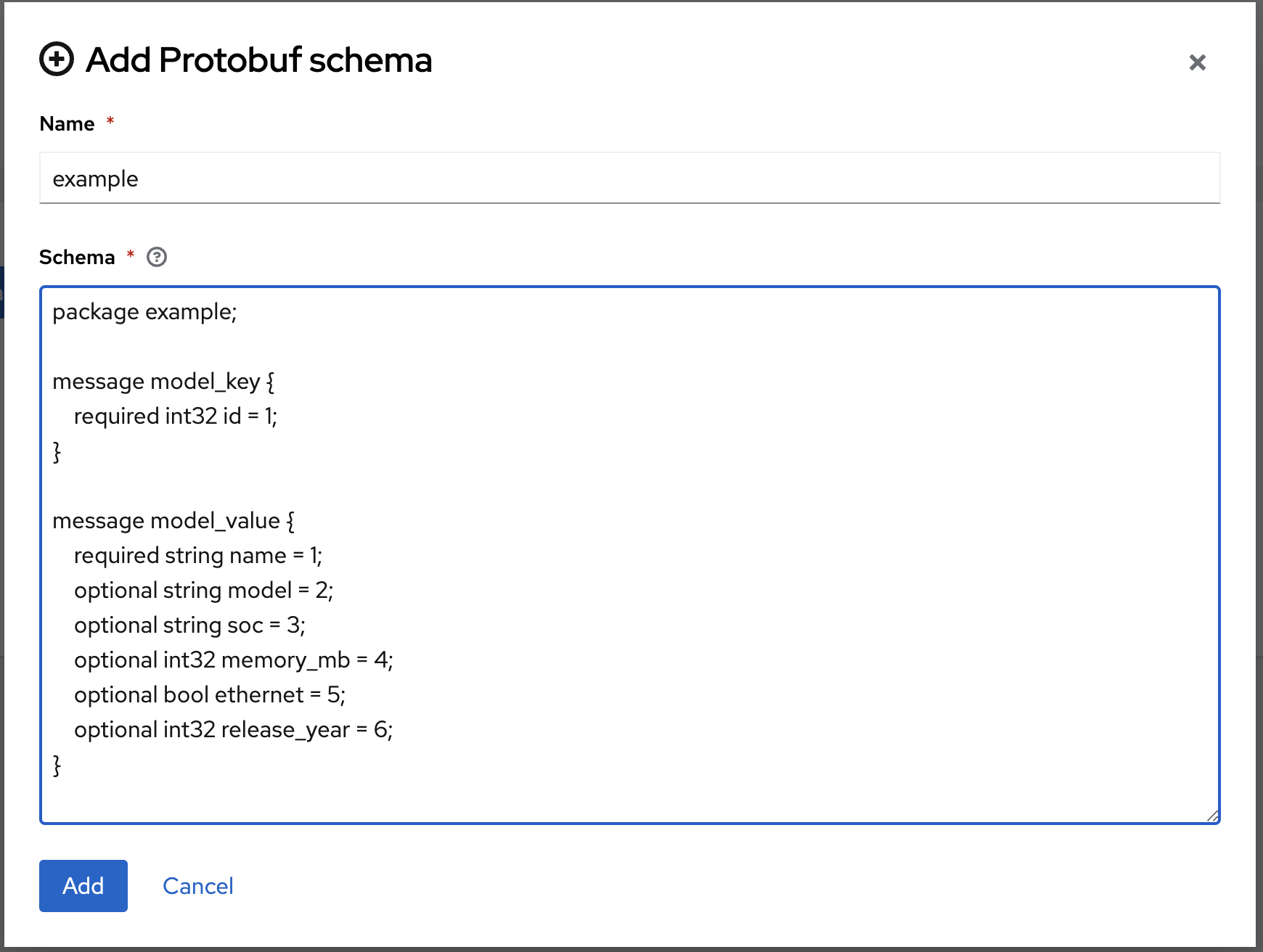
Use the following configuration for the cache. In the configuration, table-name refers to the model table created when PostgreSQL was deployed. The message-name and package refers to the protobuf schema. Notice the user infinispan that was previously created is used by the JDBC driver.
{
"distributed-cache": {
"mode": "SYNC",
"encoding": {
"key": {
"media-type": "application/x-protostream"
},
"value": {
"media-type": "application/x-protostream"
}
},
"persistence": {
"table-jdbc-store": {
"shared": true,
"segmented": false,
"dialect": "POSTGRES",
"table-name": "model",
"schema": {
"message-name": "model_value",
"package": "example"
},
"connection-pool": {
"connection-url": "jdbc:postgresql://postgresql-12-custom:5432/rpi-store",
"driver": "org.postgresql.Driver",
"username": "infinispan",
"password": "secret"
}
}
}
}
}
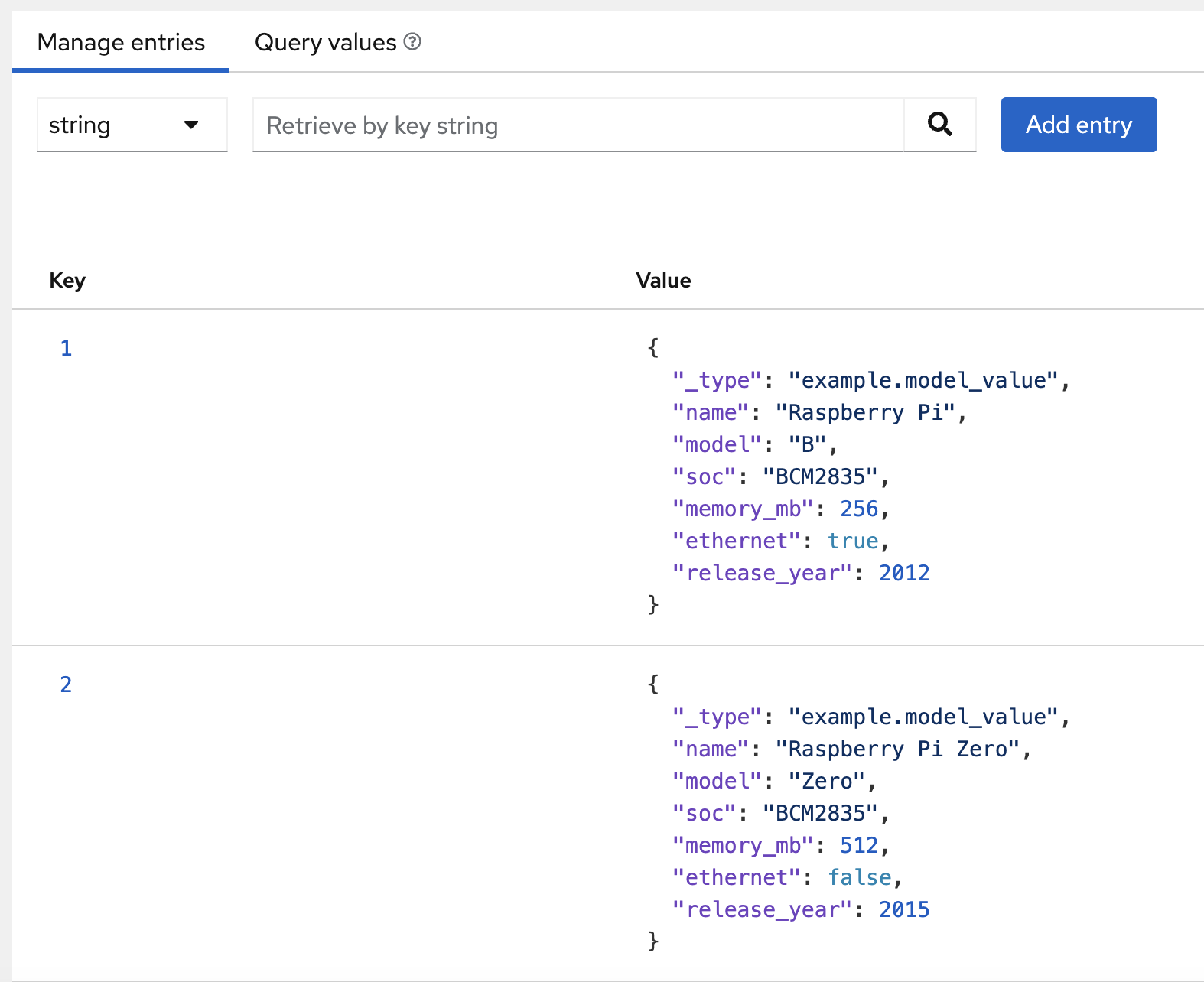
When created, the cache will automatically load the model table, as shown in Figure 2:
Run the server task
In our example, the table from which Data Grid loaded the entries to the cache will be modified without notifying Data Grid. To update the cache with the modified entry, the server task will be called from a Hot Rod client.
First, we update a row in the model table:
$ oc exec postgresql-12-custom-0 -- psql -U postgres -d rpi-store -c "update model set name = 'Raspberry Pi UPDATED' where id = 1;" $ oc exec postgresql-12-custom-0 -- psql -U infinispan -d rpi-store -c "select * from model;" id | name | model | soc | memory_mb | ethernet | release_year ----+-----------------------+-------+---------+-----------+----------+-------------- 2 | Raspberry Pi Zero | Zero | BCM2835 | 512 | f | 2015 3 | Raspberry Pi Zero | 2W | BCM2835 | 512 | f | 2021 1 | Raspberry Pi UPDATED | B | BCM2835 | 256 | t | 2012 (3 rows)
Verify that the cache doesn't contain the updated entry by using the Infinispan CLI to lookup the key 1 in the cache:
$ oc get pods
NAME READY STATUS RESTARTS AGE
infinispan-0 1/1 Running 0 86s
$ oc rsh infinispan-0
sh-4.4$./bin/cli.sh
[disconnected]> connect
Username: developer
Password: my_password
[infinispan-0-28040@infinispan//containers/default]> cd caches
[infinispan-0-28040@infinispan//containers/default/caches]> cd rpi-store
[infinispan-0-28040@infinispan//containers/default/caches/rpi-store]> get 1
{
"_type" : "example.model_value",
"name" : "Raspberry Pi",
"model" : "B",
"soc" : "BCM2835",
"memory_mb" : 256,
"ethernet" : true,
"release_year" : 2012
}
The cache hasn't been notified about the modified row and still contains the name, Raspberry Pi.
To load the modified entry into the cache, we run the client. The username and password are located under Secrets in infinispan-generated-secret. The Data Grid server can be accessed from the infinispan loadbalancer hostname and port.
$ git clone https://github.com/torbjorndahlen/infinispan-evict-cache.git $ cd infinispan-evict-cache/ServerTask/client $ mvn clean package $ mvn assembly:assembly -DdescriptorId=jar-with-dependencies $ java -cp target/ServerTaskClient-jar-with-dependencies.jar \ > example.CacheServerTaskInvocation \ > my_host.example.com 11222 \ > developer my_password rpi-store
Verify that the cache now contains the modified entries by using the Infinispan CLI to lookup the key 1 in the cache:
$ oc rsh infinispan-0
sh-4.4$./bin/cli.sh
[disconnected]> connect
Username: developer
Password: my_password
[infinispan-0-28040@infinispan//containers/default]> cd caches
[infinispan-0-28040@infinispan//containers/default/caches]> cd rpi-store
[infinispan-0-28040@infinispan//containers/default/caches/rpi-store]> get 1
{
"_type" : "example.model_value",
"name" : "Raspberry Pi UPDATED",
"model" : "B",
"soc" : "BCM2835",
"memory_mb" : 256,
"ethernet" : true,
"release_year" : 2012
}
The updated value for key 1 has been loaded into the cache.
Summary
In this article, we demonstrated how a cache using a PostgreSQL database as a cache store can be refreshed by using a server task invoked from a Hot Rod client when a table is being updated by other means than passing through Data Grid.
Thanks to Tristan Tarrant at Red Hat for providing advice and suggestions on the implementation of this tutorial.
Last updated: September 19, 2023