The problem of detecting fraudulent transactions is intriguing for a data scientist. However, the overhead from setting up the technologies around it can be cumbersome. This is where Red Hat OpenShift Data Science, along with Starburst and Intel OpenVino, come to the rescue. Now data scientists can focus on what they do best, model training and crafting; and OpenShift Data Science will do what we do best, providing the tools with the least overhead.
This article will cover detecting fraudulent transactions in a financial institution on Red Hat OpenShift Data Science.
Workflow for credit card fraud detection
Credit card fraud is a significant problem in the finance industry. Fraudsters can steal credit card information and use it to make unauthorized purchases. Fraud detection systems can monitor credit card transactions and identify suspicious activities, such as large transactions or transactions in unusual locations, and flag them for further investigation.
Building an effective fraud detection system using machine learning requires careful data collection, feature engineering, model selection, training and validation, deployment, monitoring, and updating to ensure that the system remains effective over time.
The diagram in Figure 1 shows the typical workflow for building and deploying machine learning models for detecting credit card payment fraud.

Overview of the fraud detection solution
Figure 2 shows how to use the OpenShift Data Science platform to deploy an agile solution for detecting fraudulent credit card payment.
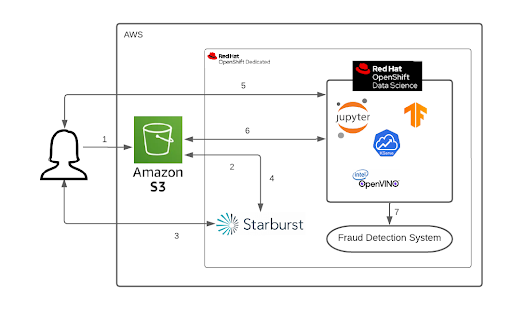
The steps in the diagram are as follows:
- The data scientist uploads data to Amazon S3.
- Starburst Enterprise is connected to Amazon S3.
- The data scientist uses the query editor in Starburst to preprocess the data and visualize the dataset.
- The cleaned data is uploaded back to Amazon S3 via Starburst.
- Next, the data scientist creates a data science project within OpenShift Data Science which enables them to launch JupyterLab along with specific dependencies.
- Retrieves the cleaned data from Amazon S3. Using the data, they train machine learning models and upload them back to Amazon S3.
- The trained models are then served by the OpenVINO Model Server.
- Finally, the models are deployed for fraud detection.
What is Red Hat OpenShift Data Science?
Red Hat OpenShift Data Science is a platform for developing, deploying, and managing machine learning workflows and models in a containerized environment. It is built on top of the Red Hat OpenShift Container Platform and provides a suite of tools and services for ML workflows, including data preparation, model training, and model deployment. Read more about OpenShift Data Science in the article, 4 reasons you’ll love using OpenShift Data Science.
OpenShift Data Science is fully integrated with AI/ML tools, including JupyterLab with predefined notebook images for launching notebooks with access to core AI/ML libraries and frameworks like TensorFlow. It provides a single interface for managing and implementing all ML steps, including model deployment and training, and is backed by local storage for saving tasks for later use.
In our workflow, we created a data connection to Amazon S3 for adding data to the project. OpenShift Data Science is also integrated with Kserve ModelMesh Serving, which provides out-of-the-box integration with model servers and allows selecting the model server and data connection. The user can view the current status of deployed models and their inference endpoints.
We configured the OpenVINO Model Server, which allows for easy deployment and management of pre-trained deep learning models in production environments. It provides a flexible and scalable platform for deploying deep learning models with RESTful APIs, making it easy to integrate the models with applications.
Why we use Starburst and Amazon S3
Starburst Enterprise provides a powerful, user-friendly interface for managing Trino clusters, monitoring query performance, and identifying bottlenecks. It is a popular tool for organizations that use Trino for distributed SQL query processing and require a comprehensive interface for managing their Trino clusters. It unlocks access to data where it lives, no data movement required, giving your teams fast and accurate access to more data for analysis using query editor.
We use Amazon S3 for storing the datasets and trained models. The user can make use of the Amazon S3 in data collection, preprocessing data, and model training phase.
Prerequisites
- OpenShift Data Science sandbox
- Starburst Enterprise license
- Starburst Operator installed
- Read and write access to Amazon S3 bucket
- Access to the original dataset
The environment setup
You can find guidance for setting up the environment by following these links:
- Set up your Red Hat OpenShift Data Science environment.
- If you haven’t already, you can find information about getting an instance of Red Hat OpenShift Data Science on the developer page. You can spin up your own account on the free OpenShift Data Science Sandbox or learn about installing on your OpenShift cluster.
- Set up Starburst operator on OpenShift Data Science.
- Connect Starburst to Amazon S3 and launch Starburst Query Editor.
- Try out the fraud detection use case on OpenShift Data Science.
Watch the demo video presented by Suvro Ghosh (creator):
OpenShift Data Science simplifies fraud detection
Red Hat OpenShift Data Science provides a fully supported environment in which to rapidly develop, train, and test AI/ML models in the public cloud before deploying in production. This use case can be extended by bringing your algorithm for fraud detection and model framework using the OpenShift Data Science ecosystem. Feel free to comment below if you have questions. We welcome your feedback!
Last updated: September 19, 2023