This is the first article in a three-part regarding existing solutions to manipulate Kafka stream data with SQL, the well-known query language widely used to manipulate relational databases.
Apache Kafka
Apache Kafka is an open-source distributed streaming system used for stream processing, real-time data pipelines, and data integration at scale. Originally created to handle real-time data feeds at LinkedIn in 2011, Kafka quickly evolved from messaging queue to a full-fledged event streaming platform capable of handling over 1 million messages per second, or trillions of messages per day.
OpenShift offers many options to install an Apache Kafka cluster, including various operators, but in this article, we'll focus on the creation of managed Apache Kafka services using Red Hat OpenShift Streams for Apache Kafka, which also provides an option to try out a free instance that we will use for the purposes of our exercise.
ksqlDB
ksqlDB is a real-time event-streaming database built on top of Apache Kafka. It combines powerful stream processing with a relational database model using SQL syntax. It can connect multiple Apache Kafka instances at the same time, providing an alternative to manipulate the data streams with almost no code.
ksqlDB Standalone is an open source project that's licensed under the Confluent Community License.
The main use cases for adopting ksqlDB are the following:
- Materialized caches
- Streaming ETL pipelines
- Event-driven microservices
ksqlDB also provides commands to manage connectors based on the Kafka Connect technology to easily integrate the messaging system with external sources or sinks, like relational or NoSQL databases, key-value stores, search indexes, and file systems among others.
In terms of management interface, ksqlDB provides both a command-line interface (CLI) to run SQL-like commands and a REST API to run the same operations from an HTTP client.
Introducing the sample application
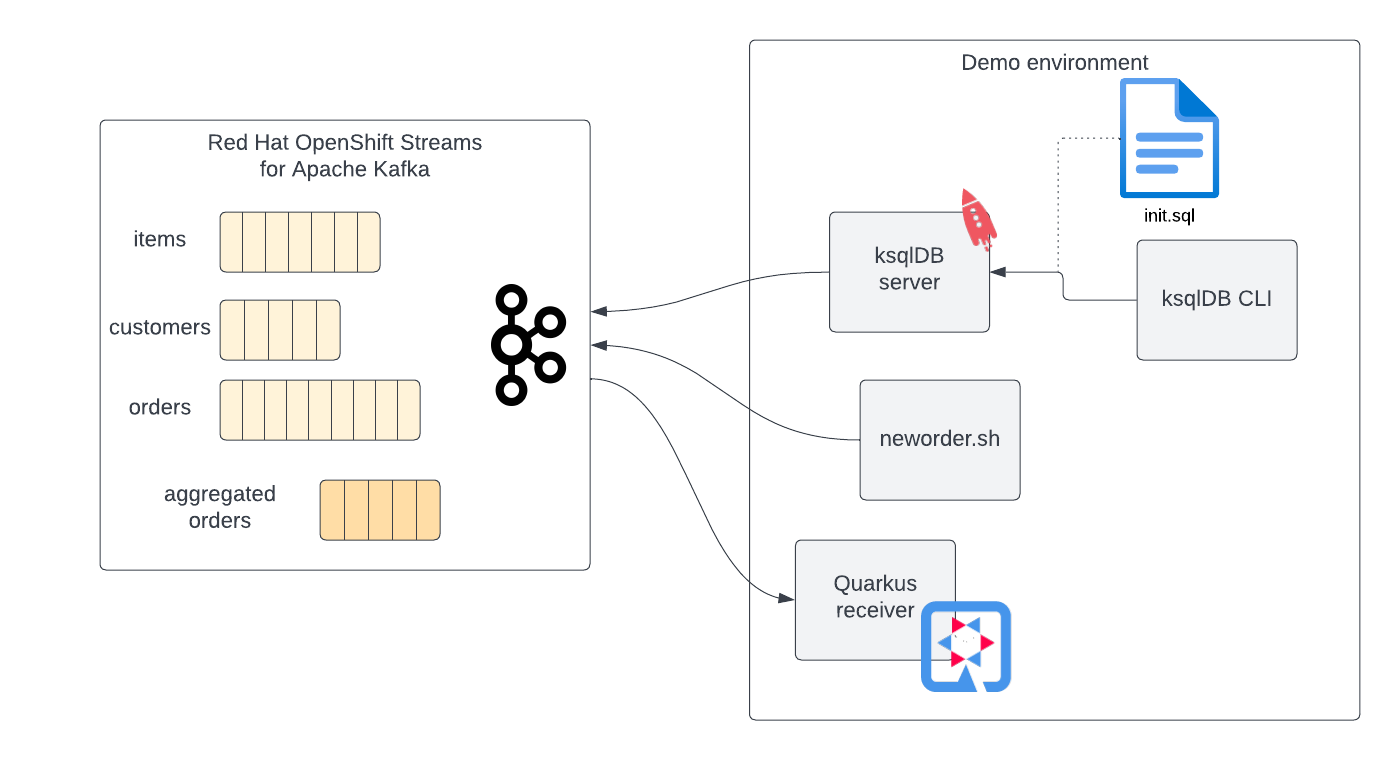
This article shows how to install, configure, and operate an application made of the following components:
- An instance of the Red Hat OpenShift Streams for Apache Kafka managed service called
kafka-orders - Three topics to model:
customers,itemsandorders - A ksqlDB server connected to the to
kafka-ordersinstance and its CLI console - A SQL script to populate topics with sample SQL
INSERTs - An aggregated stream
aggregated-ordersdefined with a push query sending messages to the external subscribers - A Quarkus
receiverapplication subscribed to receive and print the messages from the new stream neworders.sh, a bash script to inject new orders
Figure 1 shows the architecture of the sample demo application.
Install and run the demo
To run the demo in this article, you need the following tools:
- rhoas CLI
- Maven 3.x
- Java SDK 11+
- bash terminal session
You also need accounts on the following systems:
- Red Hat OpenShift Application and Data Services like https://sandbox.redhat.com
To run the exercise, clone the repository of the source code and define an environment variable to easily reference the root folder:
git clone git@github.com:dmartinol/ksqldb-on-rhoas.git
cd ksqldb-on-rhoas
export DEMO_HOME=$PWDCreate the Kafka instance
You need to request a login token by visiting the OpenShift Cluster Manager API Token, then replace the TOKEN parameter with the given token and login to the rhoas CLI:
rhoas login --api-gateway https://api.openshift.com -t "<TOKEN>"
The first step is to create a managed Kafka instance called kafka-orders, along with the required topics items, customers and orders, then set up the access rules to grant access to a service account called kafka-orders-quarkus for topics whose name starts by ksql-topic:
./createKafka.shOnce the creation completes (it might take up to five minutes), you can check the configuration by looking at the content of the following files:
kafka-orders.json: the configuration of the Kafka hostkafka-orders-quarkus.json: the configuration of the service account
Alternatively, you can review the same details in the Kafka Instances management console, together with other useful information displayed in the Topics and Access tabs, as shown in Figure 2.

The checkKafkaStatus.sh script also provides an option to print the same details on the terminal console.
cd $DEMO_HOME
./checkKafkaStatus.shInstall ksqlDB
We will run the ksqlDB tool from the source code, so we need to clone the GitHub repository and build one of the stable branches, like v7.2.2:
git clone https://github.com/confluentinc/ksql.git
cd ksql
export KSQL_HOME=${PWD}
git checkout v7.2.2
mvn clean installOther installation options are described in the ksqlDB documentation page.
Configure the ksqlDB service account
ksqlDB must be allowed to connect and manage the Kafka resources, so we create a specific service account, ksqldb-sa, and configure the access rules to let ksqlDB access and manage the required resources:
cd $DEMO_HOME/ksqldb
./createSaForKsql.shA complete description of the required access rules is provided in the Required ACLs section of the ksqlDB documentation.
Run ksqlDB server and CLI
The next step is to launch the ksqlDB server on the default port 8088 and connect it to the Kafka instance created before:
cd $DEMO_HOME/ksqldb
./startKsql.shOn a different terminal, we can start the ksqlDB CLI and populate the topics with sample data contained in the file init.sql:
> cd $DEMO_HOME/ksqldb
> ./startKsqlCli.sh
...
===========================================
= _ _ ____ ____ =
= | | _____ __ _| | _ \| __ ) =
= | |/ / __|/ _` | | | | | _ \ =
= | <\__ \ (_| | | |_| | |_) | =
= |_|\_\___/\__, |_|____/|____/ =
= |_| =
= The Database purpose-built =
= for stream processing apps =
===========================================
Copyright 2017-2022 Confluent Inc.
CLI v7.2.2, Server v7.2.2 located at http://localhost:8088
Server Status: RUNNING
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql> RUN SCRIPT init.sql;
From the ksqlDB CLI, we can use some SQL commands to validate the content of the ksqDB, like SHOW TOPICS, SHOW STREAMS, SELECT * FROM ORDERS, DESCRIBE ORDERS.
ksql> SHOW TOPICS;
Kafka Topic | Partitions | Partition Replicas
--------------------------------------------------------------------
customers | 1 | 1
items | 1 | 1
ksql-service-ksql_processing_log | 1 | 1
orders | 1 | 1
--------------------------------------------------------------------
ksql> SHOW STREAMS;
Stream Name | Kafka Topic | Key Format | Value Format | Windowed
-----------------------------------------------------------------------------------------------
KSQL_PROCESSING_LOG | ksql-service-ksql_processing_log | KAFKA | JSON | false
ORDERS | orders | KAFKA | JSON | false
-----------------------------------------------------------------------------------------------
ksql> DESCRIBE ORDERS;
Name : ORDERS
Field | Type
------------------------------
ITEMID | VARCHAR(STRING)
CUSTOMERID | VARCHAR(STRING)
PRICE | DOUBLE
------------------------------
For runtime statistics and query details run: DESCRIBE <Stream,Table> EXTENDED;
ksql> SELECT * FROM ORDERS;
+----------------------------------------------------------------------+----------------------------------------------------------------------+----------------------------------------------------------------------+
|ITEMID |CUSTOMERID |PRICE |
+----------------------------------------------------------------------+----------------------------------------------------------------------+----------------------------------------------------------------------+
|A1 |C1 |5.8 |
|A1 |C2 |6.0 |
|A1 |C3 |5.0 |
|A2 |C1 |123.3 |
|A2 |C1 |120.3 |
Query Completed
Query terminated
For a list of available SQL commands, you can read the SQL quick reference page.
Creating a merged stream and an aggregated table
Using the ksqlDB CLI, we create an aggregated stream called FULL_ORDERS that contains one message for each of the stored orders and the aggregated table AGGREGATED_ORDERS built on the FULL_ORDERS stream to calculate the total cost of all the orders for each customer:
ksql> CREATE STREAM FULL_ORDERS AS
SELECT customers.customerId, customers.name, items.itemId, items.item, orders.price
FROM orders
JOIN customers ON orders.customerId = customers.customerId
JOIN items ON items.itemId = orders.itemId
EMIT CHANGES;
ksql> CREATE TABLE AGGREGATED_ORDERS AS
SELECT CUSTOMERS_CUSTOMERID, count(*) as noOfItems, sum(price) as totalPrice
FROM FULL_ORDERS
GROUP BY CUSTOMERS_CUSTOMERID
EMIT CHANGES;The ksqlDB documentation describes the difference between streams and tables: the first are immutable collections that represent a series of historical facts, while the latter are mutable collections that change over time, defining the current status of any entity identified by its key.
The execution of the SHOW TOPICS and SHOW QUERIES commands describe the effects of the above commands on the ksqlDB database.
ksql> SHOW TOPICS;
Kafka Topic | Partitions | Partition Replicas
--------------------------------------------------------------------
customers | 1 | 1
items | 1 | 1
ksql-service-ksql_processing_log | 1 | 1
ksql-topic-AGGREGATED_ORDERS | 1 | 1
ksql-topic-FULL_ORDERS | 1 | 1
orders | 1 | 1
--------------------------------------------------------------------
ksql> SHOW QUERIES;
Query ID | ...
-------------------------------
CSAS_FULL_ORDERS_7 | ...
CTAS_AGGREGATED_ORDERS_9 | ...
-------------------------------
For detailed information on a Query run: EXPLAIN <Query ID>;
Note that all the newly created topics are prefixed by ksql-topic-, which is the configuration that we provided in the startKsql.sh script.
The Quarkus receiver application
In the receiver folder of the demo source code, we developed a Quarkus application that receives messages from the newly created stream AGGREGATED_ORDERS and prints the content to the console. Using the @Incoming annotation, we can specify the Kafka topic as the data source:
@ApplicationScoped
public class AggregatedOrderReceiver {
private Logger log = Logger.getLogger(AggregatedOrderReceiver.class);
@Incoming("get-aggregated-order")
@Acknowledgment(Acknowledgment.Strategy.POST_PROCESSING)
public void process(ConsumerRecord<String, AggregatedOrder> record) {
record.value().customerId = record.key();
log.infof("AggregatedOrderReceiver received %s", record.value());
}
}
The topic configuration is specified in the application.properties file:
# Configure the Kafka source (we read from it)
mp.messaging.incoming.get-aggregated-order.topic=ksql-topic-AGGREGATED_ORDERS
mp.messaging.incoming.get-aggregated-order.group.id=${KAFKA_CONSUMER_GROUP}
mp.messaging.incoming.get-aggregated-order.value.deserializer=org.acme.kafka.AggregatedOrderDeserializer
Launch the Quarkus receiver application to connect to the Kafka cluster and receive updates on the ksql-topic-AGGREGATED-ORDERS topic:
cd $DEMO_HOME/receiver
./startReceiver.shTesting the integration
To validate the integration, we will run a push query to receive updates from the AGGREGATED-ORDERS table:
ksql> SELECT * FROM AGGREGATED_ORDERS EMIT CHANGES;
+-----------------------+-----------------+----------------+
|CUSTOMERS_CUSTOMERID |NOOFITEMS |TOTALPRICE |
+-----------------------+-----------------+----------------+
Press CTRL-C to interrupt
The query includes the option EMIT CHANGES to make it a push query that produces a continuously updating stream of the latest messages, a never-ending query that must be explicitly terminated using the TERMINATE command in a new ksqlDB CLI session:
ksql> SHOW QUERIES;
ksql> TERMINATE <QUERY ID>;
You can read more about the difference between push and pull queries on the ksqlDB documentation page.
At the same time, we use the neworder.sh script available in the ksqldb folder to push some new random messages in the orders topic.
cd $DEMO_HOME/ksqldb
./neworder.sh -o 10The animation in Figure 3 shows how the messages created in the neworders tab of the screen are displayed in the ksqlDB CLI running the SELECT statement (left screen of receivers tab) and on the Quarkus receiver application on the right screen of the receivers tab:
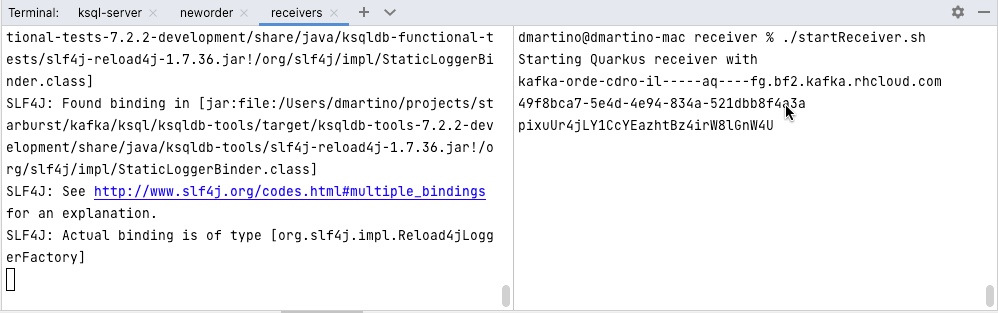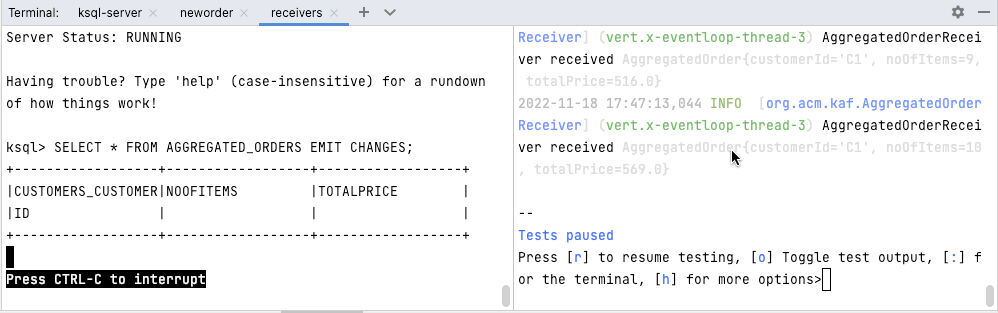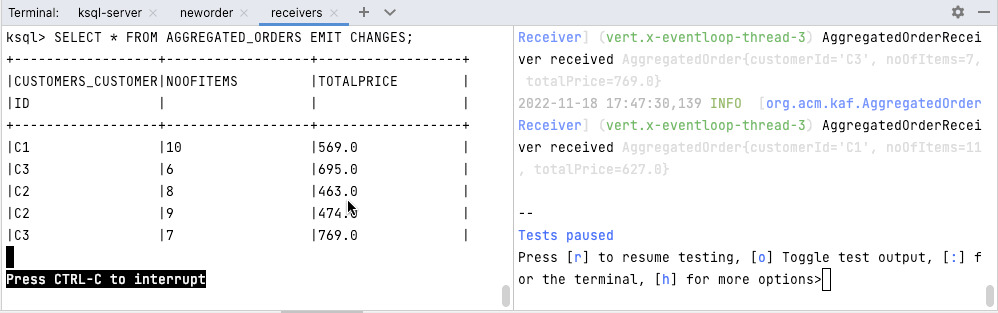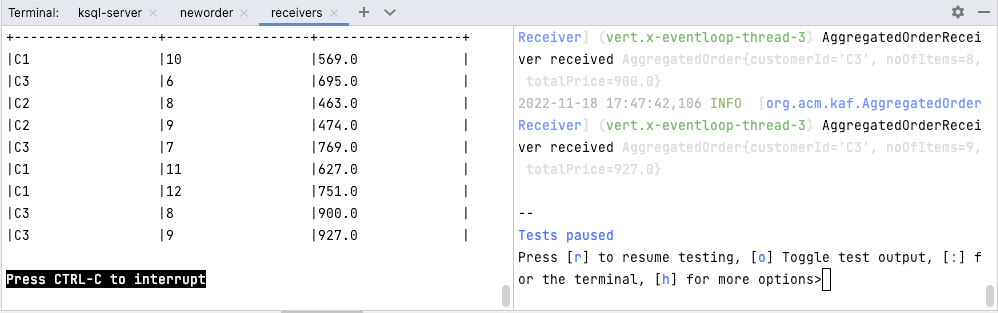
Tear down the managed resources
To clear the setup, we can delete all the resources created for the purpose of the demo:
cd $DEMO_HOME/ksqldb
./deleteAll.sh
cd ..
./deleteAll.shksqlDB to process streams of Kafka messages
By using ksqlDB and the familiar SQL command syntax, we processed the messages in an Apache Kafka cluster and generated new aggregated messages using standard SQL aggregation functions. We injected new messages on the topics and watched the live streams of events coming in real time from a push query in the ksqlDB CLI and from a message stream in a Quarkus application.
No code was needed to process the streams, apart from a few SQL commands. The procedures presented in the demo are available in GitHub.
The rhoas CLI was used to interact with the Red Hat OpenShift Application and Data Services and hide the complexity of creating the Kafka instance and defining the access rules for both the Quarkus application and the ksqlDB server.