Capture groups, lookaheads, and lookbehinds provide a powerful way to filter and retrieve data according to advanced regular expression matching logic. This article explains capture groups, lookaheads, and lookbehinds, along with the fundamental syntax you need to know in order to write them.
This is the fourth article in a series about regular expressions:
- Part 1: A beginner’s guide to regular expressions with grep
- Part 2: Regex how-to: Quantifiers, pattern collections, and word boundaries
- Part 3: Filter content in HTML using regular expressions in grep
In those articles, you learned about regular characters, metacharacters, quantifiers, pattern collections, and word groups. This article builds on those concepts. As in the previous articles in the series, the sample commands here execute regular expressions by piping string output from an echo command to the grep utility. The grep utility uses a regular expression to filter content. The benefit of demonstrating regular expressions using grep is that you don't need to set up any special programming environment. You can execute an example immediately by copying and pasting the code directly into your computer's terminal window running under Linux.
Capture groups
A capture group, as the name implies, is a regular expression that matches and returns groups of characters according to a pattern. The regular expression logic for a capture group is written between opening and closing parentheses. For example:
(...)
This capture group represents the following logic: Match any of the characters in a string and return the matches in groups of three characters. (Remember, the metacharacter . means any character.) Consider the following command set, which is an echo command that pipes a string to a grep command that executes the regular expression:
$ echo "abcdef" | grep -Po '(...)'
The commands shown above return the following result:
abc
def
The following regular expression returns capture groups in which each group is made up of three numeric characters. The regular expression uses the \d metacharacters, which indicate any numeric digit:
(\d\d\d)
Again, we feed a string to grep that executes the regular expression like so:
$ echo "My telephone number is 212 271 0897" | grep -Po '(\d\d\d)'
The command returns the following output:
212
271
089
The following capture group matches and groups together any 12 characters in a string of text. In this case, the text is a snippet of HTML echoed like so:
$ echo "<p><div>John Lennon</div> and <div>Mick Jagger</div></p>" |grep -Po '(...........)'
The regular expression returns the following output:
<p><div>Joh
n Lennon</d
iv> and <di
v>Mick Jagg
er</div></p
The following example matches and groups any 11 regular characters that occur between a set of HTML <div></div> tags in the echoed string.
$ echo "<p><div>John Lennon</div> and <div>Mick Jagger</div></p>" |grep -Po '(<div>...........</div>)'
The output is:
<div>John Lennon</div>
<div>Mick Jagger</div>
The following example uses the quantifier metacharacters {} to declare a regular expression that has the following logic: Match occurrences of any 11 characters that appear between a set of HTML <div></div> tags.
$ echo "<p><div>John Lennon</div> and <div>Mick Jagger</div></p>" |grep -Po '(<div>.{11}</div>)'
Result:
<div>John Lennon</div>
<div>Mick Jagger</div>
The following regular expression uses the \w metacharacters to capture a group starting with the character J and followed by zero or more word characters. (A word character is an uppercase or lowercase letter, a numeric character, or the underscore character. Other punctuation and white space characters are not word characters. Thus, matching stops when it encounters a space character or the < in </div>.)
Remember, the * metacharacter means: Find zero or more of the preceding character. In this case, the expression \w* means: Find zero or more word characters.
$ echo "<p><div>John Lennon</div> and <div>Mick Jagger</div></p>" |grep -Po '(J\w*)'
The output is:
John
Jagger
The following regular expression uses the \w metacharacters to capture occurrences of the character J followed by zero or more word characters, which are then followed by a space character. Finally, the regular expression captures a set of characters that match text in which the uppercase L character is followed by zero or more word characters. A set of characters that match the logic is returned as a capture group.
$ echo "<p><div>John Lennon</div> and <div>Mick Jagger</div></p>" |grep -Po '(J\w*\sL\w*)'
The output is:
John Lennon
The following regular expression is similar to the previous one. The difference in this example is that the pattern declaration captures the groups with words that begin with uppercase M, followed by a space character, and then words that begin with uppercase J:
$ echo "<p><div>John Lennon</div> and <div>Mick Jagger</div></p>" |grep -Po '(M\w*\sJ\w*)'
The output is:
Mick Jagger
The following regular expression declares a capture group that executes the following logic: Process the text from the file named regex-content-01.html. Find a group of characters that start with the regular characters bgcolor=" followed by any character one or more times, but stop after encountering the first " character. The extra ? after the * character makes sure that the capture group stops the first time it encounters the terminating " character, and doesn't look for more such characters in the line.
$ cat regex-content-01.html | grep -Po '(bgcolor=".*?")'
The result is:
bgcolor="#ffffff"
The following regular expression builds on the previous one. But it adds "or" logic as follows: Process the text from the file named regex-content-01.html. Find a group of characters that either start with the regular characters bgcolor=" followed by any character zero or more times and end with a " character, or start with the regular characters text=" followed by any character zero or more times and end with a " character:
$ cat regex-content-01.html | grep -Po '(bgcolor=".*?")|(text=".*?")'
The result of executing the regular expression is:
bgcolor="#ffffff"
text="#000000"
Working with lookaheads and lookbehinds
Lookaheads and lookbehinds are types of capture groups that traverse text until a certain pattern occurs. A lookahead traverses the string from the beginning of the line. A lookbehind traverses a line from its end.
The metacharacters that indicate a lookahead are: ?= . The metacharacters that indicate a lookbehind are: ?<= .
Lookaheads and lookbehinds don't include the matching pattern that defines their boundary.
Figure 1 below shows a visual analysis of lookaheads and lookbehinds that are applied to the string: <p><div>Cat</div></p>.
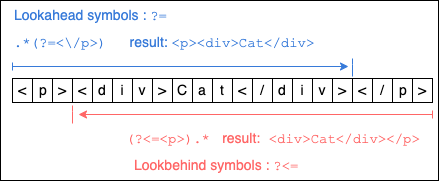
An important thing to understand about the boundary pattern in lookaheads and lookbehinds is that the boundary is determined according to the entirety of the declared pattern not by the order of the characters in the pattern. This is particularly important when considering a lookbehind.
For example, in the lookbehind regular expression (?<=<p>), the regex engine is looking backward for a complete occurrence of the pattern <p> as read from left to right. It is not looking backward, reading from right to left, processing each character in the pattern as > followed by p followed by <. This is a subtle distinction to keep in mind when thinking about the mechanics of how the regex engine processes lookaheads and lookbehinds.
Now, let's move ahead and examine the details of lookaheads and lookbehinds as illustrated in Figure 1.
Lookahead
As mentioned above, a lookahead is one in which a capture group is created by traversing text starting from the beginning of a text until a matching pattern that indicates a capture boundary is encountered.
Consider this regular expression:
.*(?=<\/p>
This expression declares the following logic: Starting at the beginning of text, match any characters one or many times until you encounter the characters <\/p>. (The regular character / is escaped by putting the regular expression escape system \ before it. This is the equivalent of saying search for the HTML tag </p>. But, since the / character is a reserved character under regular expression syntax, the \ escape character must precede the / regular character in order to not have it treated as a reserve character.)
The following is an example of executing a lookahead against the string <p><div>Cat</div></p> using the echo command and piping the result to grep like so:
$ echo "<p><div>Cat</div></p>" | grep -Po '.*(?=<\/p>)'
The regular expression produces the following result:
<p><div>Cat</div>
Notice that the result is a capture group that includes all characters except </p>. The </p> HTML tag is the lookahead boundary.
Next, let's look at using a lookbehind.
Lookbehind
As mentioned above, a lookbehind is one in which a capture group is created by traversing text starting from the end of the content, moving backward until a boundary pattern is encountered.
The metacharacters that indicate a lookbehind are: ?<=. These characters are used within the open and close parentheses as is typical for defining a capture group.
The following lookbehind regular expression: (?<=<p>).* describes the following logic: Starting at the end of content being processed by the regular expression, traverse the text backward until the regular characters <p> are encountered. Return the matching text, but do not return the lookbehind boundary.
The following example executes a lookbehind using the echo command and then piping the result to grep. The grep command is configured to filter according to a regular expression.
$ echo "<p><div>Cat</div></p>" | grep -Po '(?<=<p>).*'
The result is:
<div>Cat</div></p>
Notice that the characters <p> are excluded from the capture group returned by the lookbehind. This is to be expected.
Putting it all together
Capture groups, lookaheads, and lookbehinds add a new dimension to using regular expressions to filter data. However, they can be tricky to learn. It can take a while to get comfortable with the regular expression syntax for capture groups, lookaheads and lookbehinds. Understanding the nuances of the processing logic can take time too. But the time investment is worth it. You'll be able to use regular expressions in a more concise, more elegant, and much more powerful manner.
Hopefully the examples shown in the article and the others in this series provide a solid foundation from which you can continue in your mastery of regular expressions.
Last updated: August 14, 2023