Do your clients complain about interruptions during software upgrades? Do you observe connection failures or timeouts during those upgrades? In this article, you'll learn how you can minimize the impacts on your client visiting your services hosted on the Red Hat OpenShift Container Platform during software updates.
A rolling update creates new pods running the new software and terminates old ones. The deployment controller performs this rollout incrementally, ensuring that a certain number of new pods are ready before the controller deletes the old pods that the new pods are replacing. For details, see Rolling strategy in the Red Hat OpenShift Container Platform documentation.
Figure 1 shows a typical sequence of events during an update. The important point, for the purposes of this article, is that pods go through a transitional period where they are present but not functional. Achieving a zero-downtime rollout requires some care to drain traffic from the old pods and allow the OpenShift router time to update its configuration before the deployment controller removes the old pods.
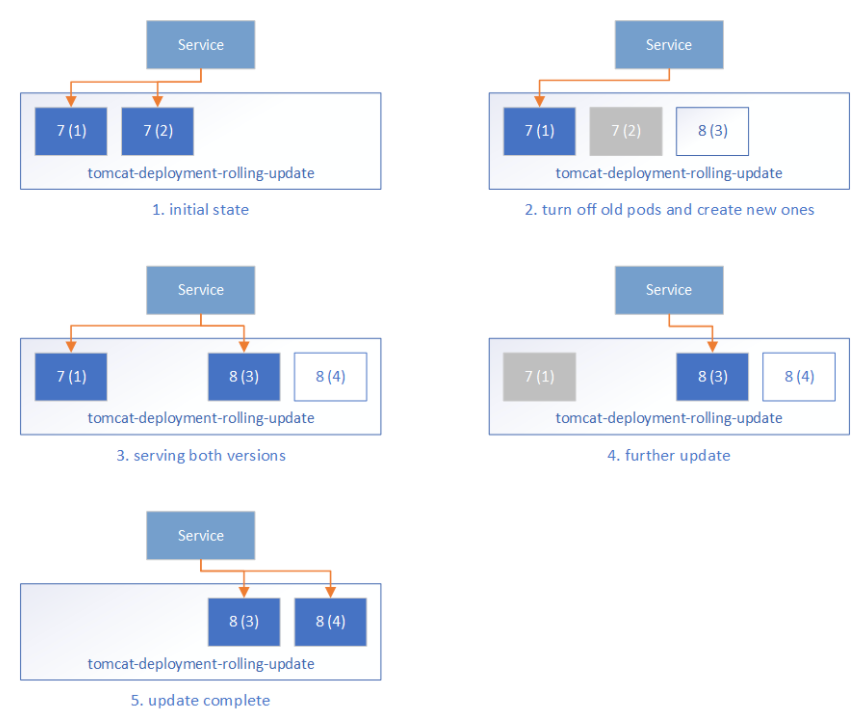
Pod termination starts with setting its deletionTimestamp field to a non-null value to indicate that it has been marked for deletion. An oc get or kubectl get command shows such a pod in a Terminating state. A pod may exist in this state for some period of time (several seconds or minutes, possibly even hours or days) before the pod is actually removed. See Termination of Pods in the Kubernetes documentation for details.
When a pod enters the Terminating state, different parts of the system react to resolve the transitional status:
-
The kubelet updates the pod's status to
Ready=False. -
The endpoint slice controller observes the update to the pod's status and removes the pod's IP address from any
EndpointSliceobject that has it. -
The OpenShift router observes this update to the
EndpointSlice. The router removes the pod's IP address from the HAProxy configuration to stop HAProxy from forwarding requests to the pod. Finally, the router reloads HAProxy so that the configuration changes take effect.
Thus, there can be a delay between when the pod is marked for deletion and when the OpenShift router reloads HAProxy with the updated configuration.
How does this affect the risk of downtime? Suppose you have a route with some backend pod, and a client sends a request for that route. Any of the following can happen with that request:
-
HAProxy forwards the request to the backend pod, and it remains responsive for the duration of the transaction. In this case, the pod sends a response, and HAProxy forwards the response to the client. Everything is fine.
-
HAProxy forwards the request to the backend pod, and the pod is terminated during the transaction. In this case, HAProxy returns an error response to the client. This makes the service appear to be down, even though many other pods are running.
-
HAProxy forwards the request to a backend pod that has already been terminated. In this case, the connection to the pod fails. Then:
-
If there is no other backend pod, HAProxy returns an error response to the client.
-
If there is another backend pod, HAProxy retries the request with that pod. In this case, the client gets a successful response, although it might be delayed while HAProxy's connection to the first backend pod fails and HAProxy retries the request with the other pod.
-
Solution: A PreStop container hook
The risk of downtime can be almost completely eliminated through a simple solution: the introduction of an arbitrary delay during the Terminating state so that a pod continues to accept and handle requests until HAProxy stops forwarding requests to that pod. This grace period can be added by adding a PreStop hook to the deployment.
The PreStop hook simply delays pod termination in order to allow HAProxy to stop forwarding requests to it. In addition, if the application handles long-lived connections, the PreStop hook must delay the pod's removal long enough for these connections to finish.
Note: The application process itself may have a built-in termination grace period. In this case, adding a PreStop hook would be superfluous.
If the application doesn't have long-lived connections, 15 to 30 seconds should be plenty of time for the PreStop hook. The administrator should test the PreStop hook with different values and set a value that suits their environment. It is crucial that the pod continues to respond to requests while it is in the Terminating state.
Note: The administrator should keep in mind that adding a PreStop hook consumes more time for recycling pods than usual.
Conclusion
Graceful termination requires time. Rolling updates can take up to several minutes to complete. For certain applications, graceful termination doesn't provide value. Determining whether it is worthwhile, and how long the grace period needs to be to allow traffic to drain, is up to the administrator. When configured appropriately, graceful termination can improve the experience for your end users.
Last updated: September 20, 2023