Introduction
In recent months, a significant shift has been observed in the virtualization landscape. Many organizations are actively seeking alternatives to legacy virtualization solutions, driven by a desire to break free from vendor lock-in and embrace the flexibility of open source technologies. The rise of Kubernetes and containerization is a key driver, pushing organizations towards solutions like OpenShift Virtualization that can manage both VMs and containers on a single platform. However, migrating to a new platform can be a daunting task.
This post will showcase how Ansible Hooks can be the ultimate weapon in your arsenal, enabling a seamless and efficient migration from VMware vSphere to Red Hat OpenShift Virtualization through the Migration Toolkit for Virtualization.
OpenShift Virtualization Overview
OpenShift Virtualization, an addon of Red Hat OpenShift, built with the widely used KubeVirt open source project, allows you to run and manage virtual machines (VMs) alongside containerized workloads on the same platform. It essentially bridges the gap between traditional virtualization and modern containerization, allowing you to bring your traditional VM-based applications into the modern, cloud-native world of Kubernetes. With OpenShift Virtualization, you can manage both VMs and containers from a single point, using familiar Kubernetes tools and concepts.
You can gradually break down legacy applications into microservices and containers over time, all while leveraging the scalability, resilience, and automation capabilities of Kubernetes for your VMs as well as your containers.
OpenShift Migration Toolkit for Virtualization
For handling migration from legacy virtualization platforms you could leverage a preintegrated toolset in OpenShift Virtualization called Migration Toolkit for Virtualization (MTV). It provides a streamlined and automated way to move workloads from various source virtualization platforms, like VMware vSphere, Red Hat Virtualization (RHV), and others, to OpenShift Virtualization.
With its automation capabilities, MTV reduces manual effort, minimizes downtime, and helps to ensure a smooth and successful migration, enabling organizations to quickly realize the benefits of running their virtual machines on OpenShift alongside their containerized applications. It allows migration in phases so that organizations can prioritize critical applications and learn from initial migrations before tackling more complex workloads.
Lastly MTV includes a pre and post hook features that enables the users to include useful Ansible Automation Playbooks in the migration process to interact with any kind of platform or device to get the Virtual Machine up and running in the target OpenShift environment.
Migrating VMs from VMware vSphere to OpenShift
As described earlier, Red Hat developed a fully featured Migration Toolkit that interfaces programmatically with source and target platforms for reducing the manual intervention and migration time. But a migration of Virtual Machines could be an articulated job to be customized around the organization's internal processes and that should take care of the existing configuration and features in place in the source and target environments.
A Real Migration Example from a Customer Engagement
In one of my latest engagements I was working with a customer using VMware vSphere but interested in testing the capabilities of OpenShift Virtualization to evaluate its adoption. I discovered that they were using for almost every virtual machine different kinds of disks in case of Operating System (OS) disk or Data disk. VMware vSphere lets you define mainly two kinds of disk mode: dependent and independent, for choosing which disk to include in a Virtual Machine Snapshot. The VMware platform will include in snapshots only the dependent disk while independent will be skipped.
The customer is using this feature because they are leveraging the snapshot mechanism only to save the state of the OS disk, while for any other Data disk they are leveraging an internal backup agent running directly on the target Virtual Machine.
For this reason we tested the migration of a Virtual Machine with this kind of configuration: one operating system’s disk in mode dependent and several other data disks in mode independent.
Let’s configure our first migration from VMware vSphere
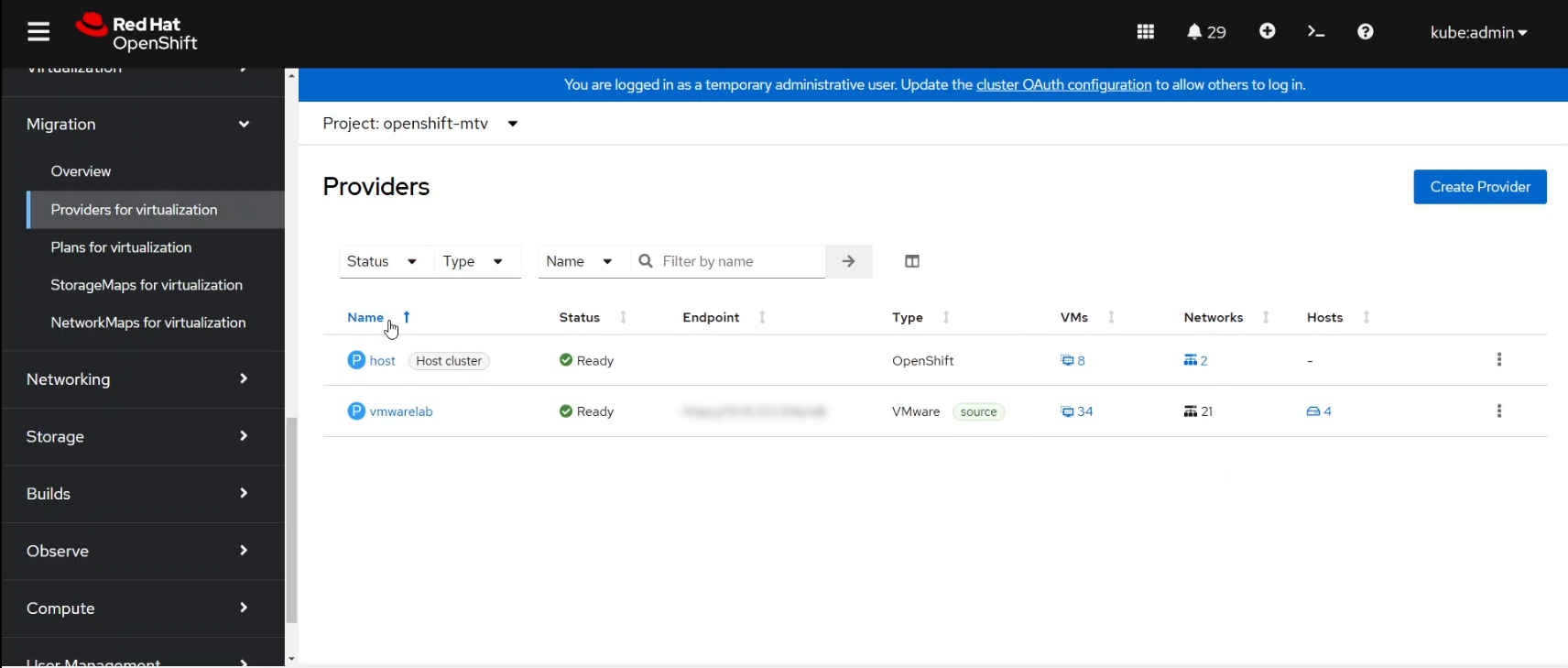
First of all we added the VMware vSphere as a Provider in the Migration Toolkit for Virtualization dashboard. After that the tool under the hood discovered all the information of the existing legacy virtualization platform, as you can see in the following screenshot.
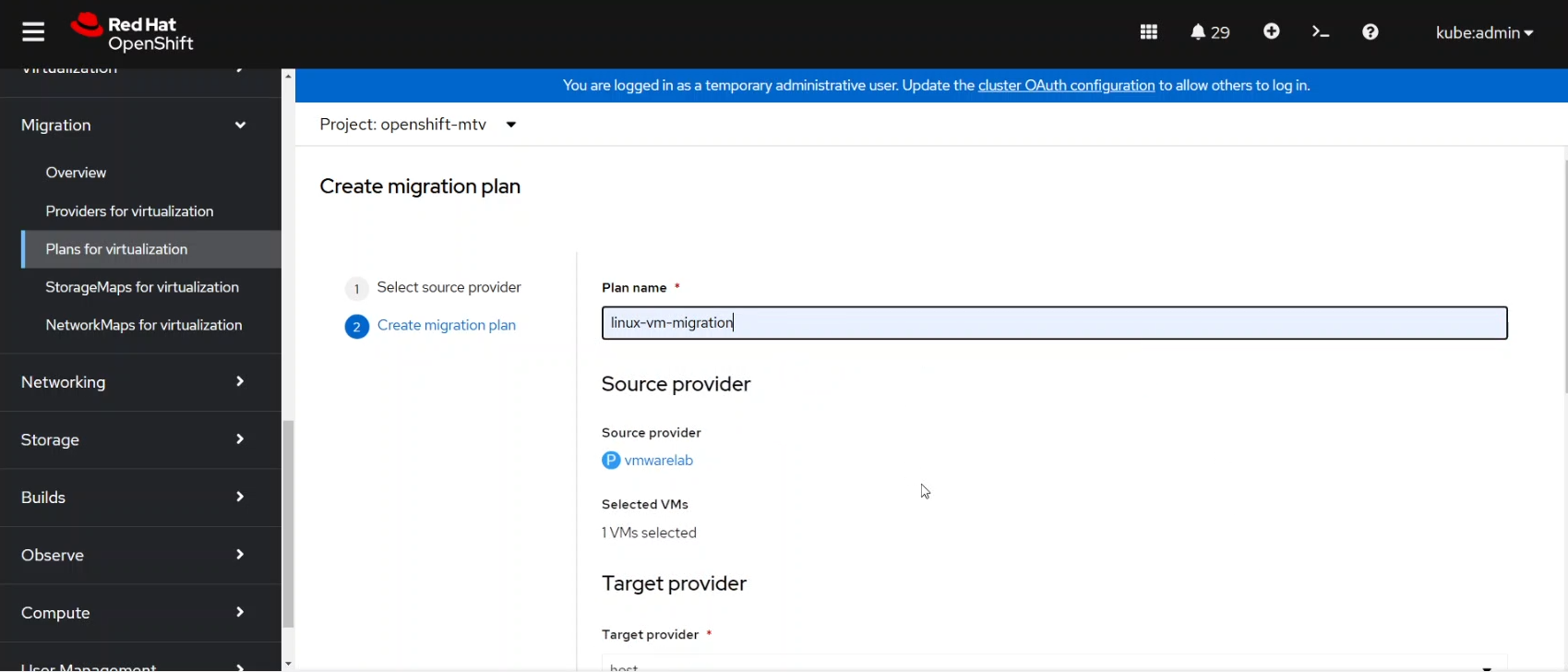
Then we created a new migration plan, selecting the target virtual machine and assigning a name to the plan as you can see in the following screenshot.
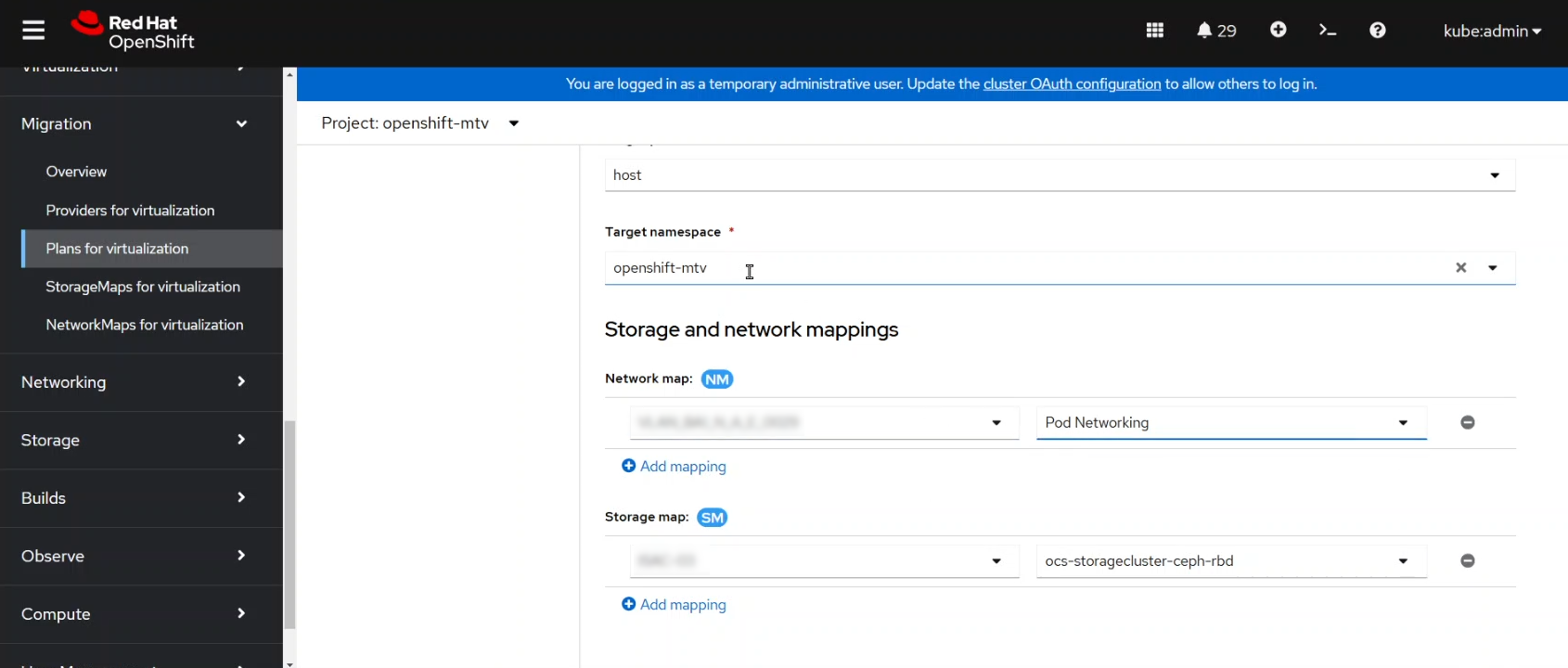
Finally we also mapped the source VMware’s network and storage with the ones available in the target OpenShift Virtualization platform as you can see in the coming screenshot.
The hidden bug in the VDDK
Unfortunately after a first attempt the migration failed!
The migration pod, running the open source tool virt-v2v aborted unexpectedly reporting a strange error like the following one:
GetFileName: Cannot create disk spec for disk <name>.
Error occurred when obtaining the file name for <name>.The Migration Toolkit for Virtualization (MTV) uses the VMware Virtual Disk Development Kit (VDDK) to transfer virtual disks from VMware vSphere. That’s why a prerequisite for MTV in case of a VMware migration is to build of a VDDK container image with the VMware SDK, as reported in the MTV Documentation.
After several searches on the net as well as on the Red Hat Knowledge Base we discovered that if the Disk Mode is Independent-Persistent or Independent-Nonpersistent, then VDDK ≥ 7 has a bug where it cannot open these disks. You can try to leverage VDDK ≤ 6.7 but it didn't work for me, the other available option is to change the Disk Mode to a regular dependent disk. More info could be found here in the nbdkit-vddk-plugin page.
Unfortunately there is not anything we could do to fix or troubleshoot this issue other than try to bypass it.
The easiest way to do this it’s through the manual change of the disk from independent to dependent through the vSphere interface. Even though it seems a really simple task, for massive migration plans this could be a real time consuming bottleneck. That’s where Ansible Hooks come to help us!
The Ansible Pre Hook Solution
Ansible is a powerful, open-source automation tool that simplifies IT tasks like configuration management, application deployment, and orchestration. It allows you to define the desired state of your systems in simple, human-readable YAML files, known as playbooks. Ansible then takes care of connecting to your servers, executing the necessary commands, and ensuring your systems are configured correctly, consistently, and repeatedly. It's agentless, meaning it doesn't require any special software to be installed on the target machines.
For these reasons Ansible is the perfect solution for our repetitive manual task: changing any disk from independent mode to dependent mode for the target VMs we are going to migrate to OpenShift Virtualization.
I leveraged the community.vmware collection that contains all the necessary modules to interact with the vSphere and the VM’s disk settings to build a brand new Ansible Playbook.
The Ansible Playbook is structured with three main tasks:
- Delete all the snapshot for every target Virtual Machine
- Gather all the disk information from the various VMs
- Check and set every disk from independent to dependent for every VM
You can find the full playbook here: playbook-pre-hook.yaml
As you can see from the Ansible Playbook, unfortunately at the moment MTV is not providing the Providers credentials in the Ansible Playbook, even though we are loading all the available variables in the initial tasks. For this reason I’ve opened a Request For Enhancement (RFE): you can leave a vote or a comment if you are interested in this feature.
Please note: Using the community.vmware collection I also discovered that any change to disk mode was not yet implemented in the Python code of the Ansible module. For this reason I’ve added the missing Python code and I’ve created a pull request to the community.vmware Ansible collection: the open source way, what a beauty!
For running the playbook on our OpenShift Virtualization platform we need a custom ansible-runner container that includes the updated community.vmware collection.
You can find the source code of the ansible-runner container here on GitHub or you can just pull and use the container image I built: quay.io/alezzandro/hook-runner-vmware:latest
We are now ready to add the Pre Hook to our Migration Plan on OpenShift Virtualization.
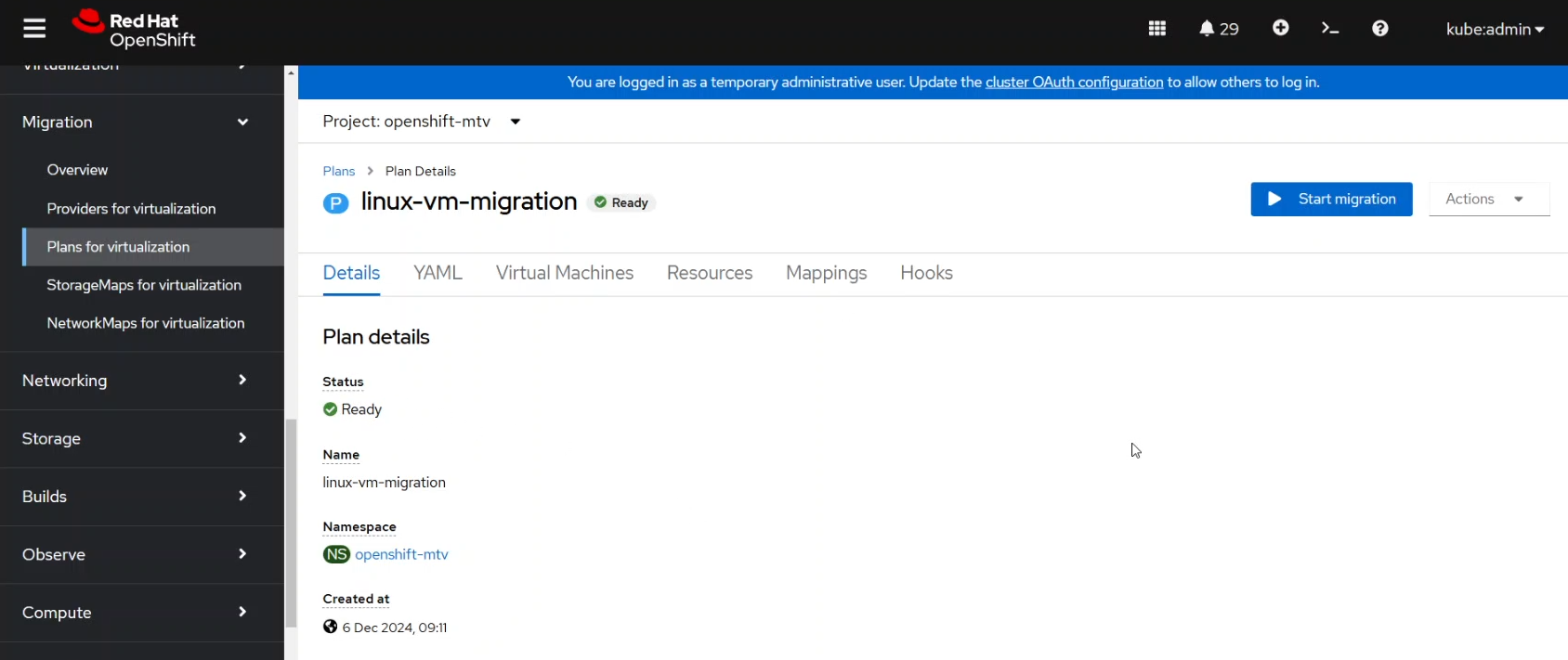
Once the migration plan is ready as shown in the screenshot below (look for the green checkmark):
We are ready to define our Ansible Pre Hook:
- First we need to define the location of our custom ansible-runner container image.
- Then we need to copy and paste the Ansible Playbook in the MTV interface.
You can find an example in the next screenshot:

The process is pretty simple and straightforward but in case you want to know more about MTV Hooks you can find a nice article explaining them here: Using migration hooks in migration toolkit for virtualization.
Once defined the Ansible Pre-Hook we are ready to launch again our Migration Plan: the migration will be successful this time and our target Virtual Machine will be up and running in OpenShift Virtualization!
Conclusion
Ansible Hooks can enable a seamless and efficient migration from VMware vSphere to Red Hat OpenShift Virtualization through the Migration Toolkit for Virtualization.
More in general leveraging Ansible for pre and post migration tasks could speed up the migration, controlling any external platform or device that needs to be updated or configured during the process.