Introduction
This blog post explores how kube-burner-ocp, an opinionated wrapper designed on top of kube-burner can be used to simplify performance and scale testing, and leveraged to evaluate egress IP scalability in OpenShift’s default CNI plugin which is OVNKubernetes . We’ll delve into the intricacies of the egress IP feature, its role in traffic management, and how kube-burner and kube-burner-ocp are helping us understand its behavior under load. This blog also serves as a classic example of how the Red Hat Performance and Scale team works with the Development team to understand, test, characterize and improve features with a holistic approach, for the benefit of our customers who reply on OpenShift for their mission critical workloads on-prem and in the cloud.
Egress IP is a network abstraction assigned to a set of pods within a project. When a pod is configured with egress IP, traffic originating from the pod which is destined to outside the cluster undergoes source IP address translation with the egress IP address by OVN. This ensures external resources, such as firewalls, can consistently identify traffic from a set of pods using a single IP address, regardless of their hosting nodes.
A key requirement for an egress IP is that it should be on the same subnet as OpenShift node’s primary interface. The egress IP for pods from a particular namespace/project can live on any one of the worker nodes in the OpenShift cluster.
Packet Flow through egress IPs
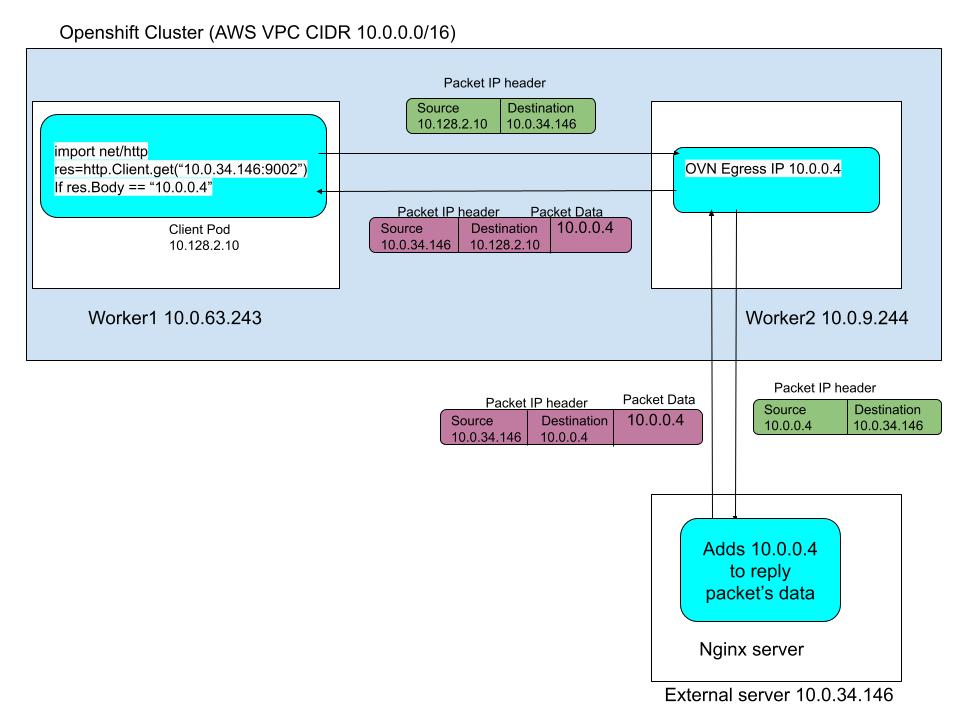
Let us use the above pictorial representation to understand the flow of traffic during this egress IP testing. Client pod (10.128.2.10) on worker1, periodically sends requests to the external Nginx server (10.0.34.146) with a 1-second interval and 3-second timeout. When OVN on Worker1 processes a packet originating from this client pod, it identifies that the pod is configured with an egress IP. This egress IP is hosted on Worker2. As a result, OVN on Worker1 forwards the packet to OVN on Worker2. OVN on worker2 replaces the source IP with egress IP (SNAT and some other magic) and sends the packet to the external Nginx server. External Nginx server receives the request with the egress IP as the source IP in the packet.The Nginx server is customized to function as an echo server. It is configured to retrieve the source IP of received packets, which corresponds to the egress IP. The server then frames a reply packet, embedding this egress IP in the reply packet’s data field. As a result, the response packet from the Nginx server includes the egress IP. OVN on worker2 replaces the destination egress IP with client pod’s IP and forwards the packet back to the client pod. The client pod through our custom written logic validates that the response indeed contains the relevant egress IP, which confirms a successful Egress IP data flow.
Kube-burner for Egress IP Testing
Kube-burner is an open-source kubernetes performance and scale test orchestration toolset written in Golang. It provides multi-faceted functionality, the most important of which are summarized below.
- Create, delete and patch Kubernetes resources at scale
- Prometheus metric collection and indexing
- Measurements
- Alerting
More details about kube-burner including its recent inclusion into the prestigious CNCF sandbox can be found in the following blogs: https://www.redhat.com/en/blog/introducing-kube-burner-a-tool-to-burn-down-kubernetes-and-openshift, https://developers.redhat.com/articles/2024/03/04/test-kubernetes-performance-and-scale-kube-burner and https://www.redhat.com/en/blog/kube-burner-fanning-flames-innovation-cncf-sandbox.
Kube-burner in its most common usage is invoked by passing a YAML based configuration file to the executable on the CLI. The configuration file contains certain global configuration options such as the endpoints of the Elasticsearch/OpenSearch indexer followed by a list of jobs, with each job having its own set of supported parameters. Each job could create, delete or patch objects at a rate defined by the QPS and Burst parameters within the job. An example job would be one that creates several deployment objects per namespace across several namespaces (determined by the jobIterations parameter) and through each deployment creates multiple pods.
In the context of egress IP test orchestration, kube-burner reads a provided job configuration and creates the specified objects for each job iteration.
Each iteration involves:
- Creating a namespace (our test ran 12000 iteration deploying 12000 namespaces)
- Deploying pods within the namespace (our test deployed 2 pods per namespace)
- Creating a cluster-scoped egress IP object with unique Egress IP addresses (our test deployed 2 egress IPs for matching the 2 pods of the namespace)
In our test, a configuration file with a job containing egress IP and deployment objects was run with 12,000 iterations. This was done to test the scalability of the solution to ensure that customers use cases that heavily rely on egress IPs are thoroughly tested internally to find and fix bottlenecks in a quick and reliable manner.
Kube-burner generates unique egress IP addresses for each job iteration and passes them to both the egress IP and pod resources that are created as a part of that iteration. This helps in binding the egress IP to the pods and the validation of egress IP by the pods in the response packet as described in the earlier section.

Kube-burner renders the above templates for each iteration. For example, in iteration 0, it creates
- namespace egressip-0
- cluster scoped egressip-obj-0 egress IP object
- pods client-1-0 and client-1-1 in that egressip-0 namespace

Users can either manually provision an AWS instance with nginx server, or leverage the e2e-benchmarking tool (discussed in the below section) which automates this process. Subsequently, they can run the kube-burner-ocp command to invoke the kube-burner-ocp wrapper to run the egress Ip scale testing workload as shown below:
kube-burner-ocp egressip --uuid <uuid> --addresses-per-iteration=1 --iterations=10 --external-server-ip=10.0.40.194Automation with e2e-benchmarking
Our CI pipeline for continuous automated performance and scale testing leverages a wrapper tool called e2e-benchmarking ) to automate the creation of test environments and configuration of kube-burner. This tool provisions an AWS instance with the same VPC, subnet and security groups (client should reach server on ports 9002 to 9064) as worker node and runs customized nginx server containers to listen on ports 9002 to 9064. The Nginx server configuration includes adding the egress IP to the return packet data field as described in the section on the Packet Flow through egress IPs
OVN assigns egress IPs only to OpenShift worker nodes labeled with ‘k8s.ovn.org/egress-assignable’. For our testing purposes, we need all OpenShift worker nodes eligible for hosting egress IPs. Therefore, this tool automatically labels all OpenShift worker nodes with ‘k8s.ovn.org/egress-assignable’ label.
The README in e2e-benchmarking repo provides details about how to run this workload
git clone https://github.com/cloud-bulldozer/e2e-benchmarking
cd e2e-benchmarking/workloads/kube-burner-ocp-wrapper/
EXTRA_FLAGS="--addresses-per-iteration=1" AWS_ACCESS_KEY_ID=<aws_key> AWS_SECRET_ACCESS_KEY=<aws_secret> WORKLOAD=egressip ITERATIONS=10 ./run.shGoal of Scale testing
The primary goals of this scale testing are to measure startup and failover latency at scale for pods configured with egress IPs. Initially, latency was measured using startup and liveness probes as shown below:
startupProbe:
exec:
command:
- "/bin/sh"
- "-c"
{{- $eips := (splitList " " (GetIPAddress .eipAddresses .Iteration .addrPerIteration) | join "|") }}
- "curl -s http://${SERVER_HOST}:${SERVER_PORT} | grep -qE '{{$eips}}'"
periodSeconds: 5
timeoutSeconds: 3
failureThreshold: 600
livenessProbe:
exec:
command:
- "/bin/sh"
- "-c"
{{- $eips := (splitList " " (GetIPAddress .eipAddresses .Iteration .addrPerIteration) | join "|") }}
- "curl -s http://${SERVER_HOST}:${SERVER_PORT} | grep -qE '{{$eips}}'"
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3Later, a Golang eivalidator application (image quay.io/cloud-bulldozer/eipvalidator prepared from this application) was used to send http requests, validate OVN’s use of the egress IP by inspecting responses, measure latency and expose that as prometheus metrics.Our testing was done with this Golang application instead of startup and liveness probes.
Testing on Openshift
AWS imposes limits on the maximum number of IP addresses that can be assigned per network interface on an instance, ranging from 30 to 50 IP addresses depending on instance size. This means we can only test 30-50 egress IPs per OpenShift worker node. To overcome this limitation, we conducted our tests on a 120-node baremetal OpenShift cluster in one of our internal labs. Each node is a Dell R640 machine with 80 CPUs, 384GB memory and a 25 Gbps NIC for the Node/Pod Networking.
In a test with 12,000 iterations:
- 12,000 namespaces were created
- Each namespace contained 2 pods and 2 egress IPs
- This resulted in a total of 24,000 pods and 24,000 egress IPs
Key Findings
- Startup Latency: To create 24,000 egress IPs (200 per worker node) on the OpenShift cluster, the 99th percentile (P99) startup latency was 8.4 milliseconds. Startup latency refers to the time taken for the application in the pod to begin running and successfully send HTTP request to the nginx server and then validate the HTTP response containing the egress IP (i.e including request response round trip time).
- Failover Latency: OVN monitors health of the nodes by probing a configured port, typically port 9107. When this probe fails, OVN initiates an egress IP failover to other nodes. To simulate egress IP failover, we blocked the health check port on a worker node that was hosting 200 egress IPs. This triggered OVN to seamlessly fail over 200 Egress IPs to other worker nodes. HTTP requests for some client pods will fail during this failover time and once the successful connection is reestablished, we record the failover latency for these pods. Initial failover latencies were high (around 41 seconds), prompting a bug report https://issues.redhat.com/browse/OCPBUGS-32161 that the OVN team successfully addressed, reducing failover latency to a commendable 2 seconds. This is another great example of how diligent scale testing in collaboration with Development teams help establish OpenShift as the industry leader in Performance and Scalability.