Drools is a popular open source project known for its powerful rules engine. Few users realize that it can also be a gateway to the amazing possibilities of artificial intelligence. This two-part article introduces you to using Red Hat Decision Manager and its Drools-based rules engine to combine machine learning predictions with deterministic reasoning. In Part 1, we'll prepare our machine learning logic. In Part 2, you'll learn how to use the machine learning model from a knowledge service.
Note: Examples in this article are based on Red Hat Decision Manager, but all of the technologies used are open source.
Machine learning meets knowledge engineering
Few Red Hat Decision Manager users know about its roots in artificial intelligence (AI), specifically the AI branch of knowledge engineering (also known as knowledge representation and reasoning). This branch aims to solve the problem of how to organize human knowledge so that a computer can treat it. Knowledge engineering uses business rules, which means a set of knowledge metaphors that subject matter experts can easily understand and use.
The Decision Model and Notation (DMN) standard recently released a new model and notation for subject matter experts. After years of using different methodologies and tools, we finally have a common language for sharing knowledge representation. A hidden treasure of the DMN is that it makes dealing with machine learning algorithms easier. The connecting link is another well-known standard in data science: The Predictive Model Markup Language, or PMML.
Using these tools to connect knowledge engineering and machine learning empowers both domains, so that the whole is greater than the sum of its parts. It opens up a wide range of use cases where combining deterministic knowledge and data science predictions leads to smarter decisions.
A use case for cooperation
The idea of algorithms that can learn from large sets of data and understand patterns that we humans cannot see is fascinating. However, overconfidence in machine learning technology leads us to underestimate the value of human knowledge.
Let’s take an example from our daily experience: We are all used to algorithms that use our internet browsing history to show us ads for products we've already purchased. This happens because it’s quite difficult to train a machine learning algorithm to exclude ads for previously purchased products.
What is a difficult problem for machine learning is very easy for knowledge engineering to solve. On the flip side, encoding all possible relationships between searched words and suggested products is extremely tedious. In this realm, machine learning complements knowledge engineering.
Artificial intelligence has many branches—machine learning, knowledge engineering, search optimization, natural language processing, and more. Why not use more than one technique to achieve more intelligent behavior?
Artificial intelligence, machine learning, and data science
Artificial intelligence, machine learning, and data science are often used interchangeably. Actually, they are different but overlapping domains. As I already noted, artificial intelligence has a broader scope than machine learning. Machine learning is just one facet of artificial intelligence. Similarly, some argue that data science is a facet of artificial intelligence. Others say the opposite, that data science includes AI.
In the field, data scientists and AI experts offer different kinds of expertise with some overlap. Data science uses many machine learning algorithms, but not all of them. The Venn diagram in Figure 1 shows the spaces where artificial intelligence, machine learning, and data science overlap.
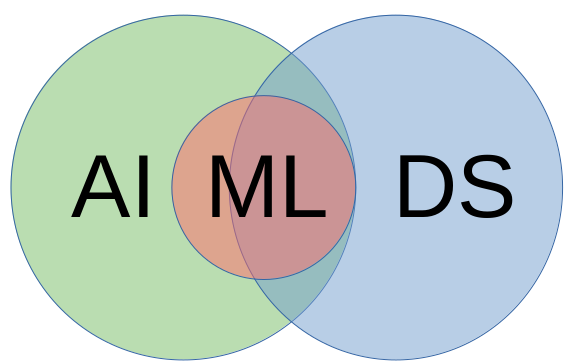
Note: See Data Science vs. Machine Learning and Artificial Intelligence for more about each of these technology domains and the spaces where they meet.
Craft your own machine learning model
Data scientists are in charge of defining machine learning models after careful preparation. This section will look at some of the techniques data scientists use to select and tune a machine learning algorithm. The goal is to understand the workflow and learn how to craft a model that can cope with prediction problems.
Note: To learn more about data science methods and processes, see Wikipedia's Cross-industry standard process for data mining (CRISP-DM) page.
Prepare and train a machine learning algorithm
The first step for preparing and training a machine learning algorithm is to collect, analyze, and clean the data that we will use. Data preparation is an important phase that significantly impacts the quality of the final outcome. Data scientists use mathematics and statistics for this phase.
For simplicity, let’s say we have a reliable data set based on a manager’s historical decisions in an order-fulfillment process. The manager receives the following information: Product type (examples are phone, printer, and so on), price, urgency, and category. There are two categories: Basic, for when the product is required employee equipment, and optional, for when the product is not necessary for the role.
The two decision outcomes are approved or denied. Automating this decision will free the manager from a repetitive task and speed up the overall order-fulfillment process.
As a first attempt, we could take the data as-is to train the model. Instead, let's introduce a bit of contextual knowledge. In our fictitious organization, the purchasing department has a price-reference table where target prices are defined for all product types. We can use this information to improve the quality of the data. Instead of training our algorithm to focus on the product type, we’ll train it to consider the target price. This way, we won't need to re-train the model when the reference price list changes.
Choosing a machine learning algorithm
We now have a typical classification problem: Given the incoming data, the algorithm must find a class for those data. In other words, it has to label each data item approved or denied. Because we have the manager’s collected responses, we can use a supervised learning method. We only need to choose the correct algorithm. The major machine learning algorithms are:
- Linear Regression
- Logistic Regression
- K-Nearest Neighbors
- Support Vector Machines
- Decision Trees and Random Forests
- Neural Networks
Note: For more about each of these algorithms, see
9 Key Machine Learning Algorithms Explained in Plain English.
Except for linear regression, we could apply any of these algorithms to our classification problem. For this use case, we will use a Logistic Regression model. Fortunately, we don't need to understand the algorithm's implementation details. We can rely on existing tools for implementation.
Python and scikit-learn
We will use Python and the scikit-learn library to train our Logistic Regression model. We choose Python because it is concise and easy to understand and learn. It is also the de facto standard for data scientists. Many libraries expressly designed for data science are written in Python.
The example project
Before we go further, download the project source code here. Open the python folder to find the machine training code (ml-training.py) and the CSV file we'll use to train the algorithm.
Even without experience with Python and machine learning, the code is easy to understand and adapt. The program's logical steps are:
- Initialize the algorithm to train.
- Read the available data from a CSV file.
- Randomly split the training and test data sets (40% is used for testing).
- Train the model.
- Test the model against the testing data set.
- Print the test results.
- Save the trained model in PMML.
A nice feature of the scikit-learn library is that its machine learning algorithms expose nearly all the same APIs. You can switch between the available algorithms by changing one line of code. This means you can easily benchmark different algorithms for accuracy and decide which one best fits your use case. This type of benchmarking is common because it's often hard to know in advance which algorithm will perform better for a use case.
Run the program
If you run the Python program, you should see results similar to the following, but not exactly the same. The training and test data are randomly selected so that the results will differ each time. The point is to verify that the algorithm works consistently across multiple executions.
Results for model LogisticRegression Correct: 1522 Incorrect: 78 Accuracy: 95.12% True Positive Rate: 93.35% True Negative Rate: 97.10%
The results are quite accurate, at 95%. More importantly, the True Negative Rate (measuring specificity) is very high, at 97.1%. In general, there is a tradeoff between the True Negative Rate and True Positive Rate, which measures sensitivity. Intuitively, you can liken the prediction sensitivity to a car alarm: If we increase an alarm's sensitivity, it is more likely to go off by mistake and increase the number of false positives. The increase in false positives lowers specificity.
Tune the algorithm
In this particular use case, of approving or rejecting a product order, we would reject the order. Manual approval is better than having too many false positives, which would lead to wrongly approved orders. To improve our results, we can adjust the logistic regression to reduce the prediction sensitivity.
Predictive machine learning models are also known as classification algorithms because they place an input dataset in a specific class. In our case, we have two classes:
- "true" to approve the order.
- "false" to refuse it.
To reduce the likelihood of a false positive, we can tune the "true" class weight (note that 1 is the default):
model = LogisticRegression(class_weight ={
"true" : .6,
"false" : 1
})
Store the model in a PMML file
Python is handy for analysis, but we might prefer another language or product for running a machine learning model in production. Reasons include better performance and integration with the enterprise ecosystem.
What we need is a way to exchange machine learning model definitions between different software. The PMML format is commonly used for this purpose. The DMN specification includes a direct reference to a PMML model, which makes this option straightforward.
You should make a couple of changes to the PMML file before importing it to the DMN editor. First, you might need to change the Python PMML version tag to 4.3, which is the version supported by Decision Manager 7.7 (the current version as of this writing):
<PMML version="4.3" xmlns="http://www.dmg.org/PMML-4_3" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
Next, you want to be able to easily identify the predictive model from the DMN modeler. Use the modelName attribute to name your model:
<RegressionModel modelName="approvalRegression" functionName="classification" normalizationMethod="logit">
The diagram in Figure 2 shows where we are currently with this project.

Conclusion
So far, you've seen how to create a machine learning model and store it in a PMML file. In the second half of this article, you will learn more about using PMML to store and transfer machine learning models. You'll also discover how to consume a predictive model from a deterministic decision using DMN. Finally, we'll review the advantages of creating more cooperation between the deterministic world and the predictive one.
Last updated: January 13, 2021