When examining Linux firewall performance, there is a second aspect to packet processing—namely, the cost of firewall setup manipulations. In a world of containers, distinct network nodes spawn quickly enough for firewall ruleset adjustment delay to become a significant factor. At the same time, rulesets tend to become huge given the number of containers even a moderately specced server might host.
In the past, considerable effort was put into legacy iptables to speed up the handling of large rulesets. With the recent push upstream and downstream to establish iptables-nft as the standard variant, a reassessment of this quality is in order. To see how bad things really are, I created a bunch of benchmarks to run with both variants and compare the results.
Benchmarks used for testing
Disclaimer: All but one of the tests that follow were created by people who don't deal with large and high-performance setups on a regular basis. Instead, my focus was to test aspects of the code given that I know the implementation behind the different commands.
Each of these benchmarks runs multiple times and the mean variation is recorded to build confidence in the results. Running the same benchmark for increasing ruleset sizes adds a second dimension to the results—a scaling factor. The following description of tests uses "N" for the value being scaled:
- Measure
iptables-restoreruntime loading a dump file with:- N rules
- N chains
- 200 chains containing N rules each
- In a ruleset with N rules in the
filtertable's chain X, measure:- Appending a rule to the
filtertable's chain X. - Deleting the last rule in the
filtertable's chain X (by rule spec). - Inserting a rule on top of the
filtertable's chain X. - Appending a rule to the
filtertable's empty chain Y. - Deleting that rule from the
filtertable's chain Y again. - Appending a rule to the
nattable's chain X. - Deleting that rule from the
nattable's chain X again. - Listing the first rule in the
filtertable's chain X. - Listing the last rule in the
filtertable's chain X. - Listing the
filtertable's empty chain Y. - Listing the
nattable's empty chain X. - Flushing the
filtertable's empty chain Y. - Flushing the
nattable's empty chain X. - Flushing the
filtertable's chain X.
- Appending a rule to the
- In a ruleset with N chains, measure:
- Flushing all chains.
- In a ruleset with 200 chains containing N rules each, measure:
- Flushing all chains.
- In a ruleset with N sets of ruleset add-ons consisting of two user-defined
chains—containing one and two rules each—and two rules appended to a common chain, measure:- Adding one further ruleset add-on as described above.
This last benchmark is supposed to be a "real-world example." It stems from Kubernetes and allegedly resembles the firewall config changes happening upon container startup. The less boring aspect, in my opinion, is the fact that the --noflush option of iptables-restore is used. This tactic is a common trick to batch several iptables commands and therefore reduce program startup and caching overhead, and is typically used in performance-critical situations. At the same time, though, optimizing its performance is a bigger challenge, as at program startup not only is kernel ruleset content unknown, but user input is as well.
Baseline results
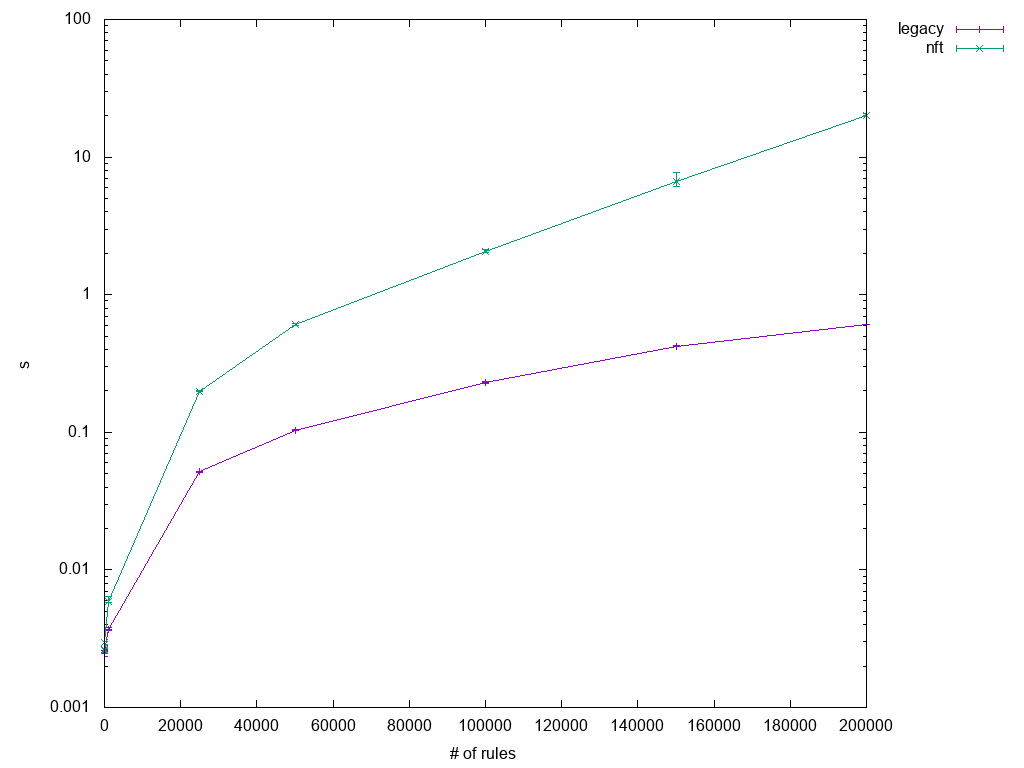
The initial test results were sobering. Legacy iptables performance was superior to iptables-nft in practically all cases, but the regular iptables-restore tests (1.1 through 1.3) were within close range, as you can see in Figure 1.

The rest varied from "performs a bit worse" to "horrible," as you can see in Figures 2 and 3.

My main suspects for why iptables-nft performed so poorly were kernel ruleset caching and the internal conversion from nftables rules in libnftnl data structures to iptables rules in libxtables data structures. The latter is hard to avoid since iptables-nft shares large portions of the parser with legacy iptables, so I focused on improving the caching algorithm.
Max out the receive buffer
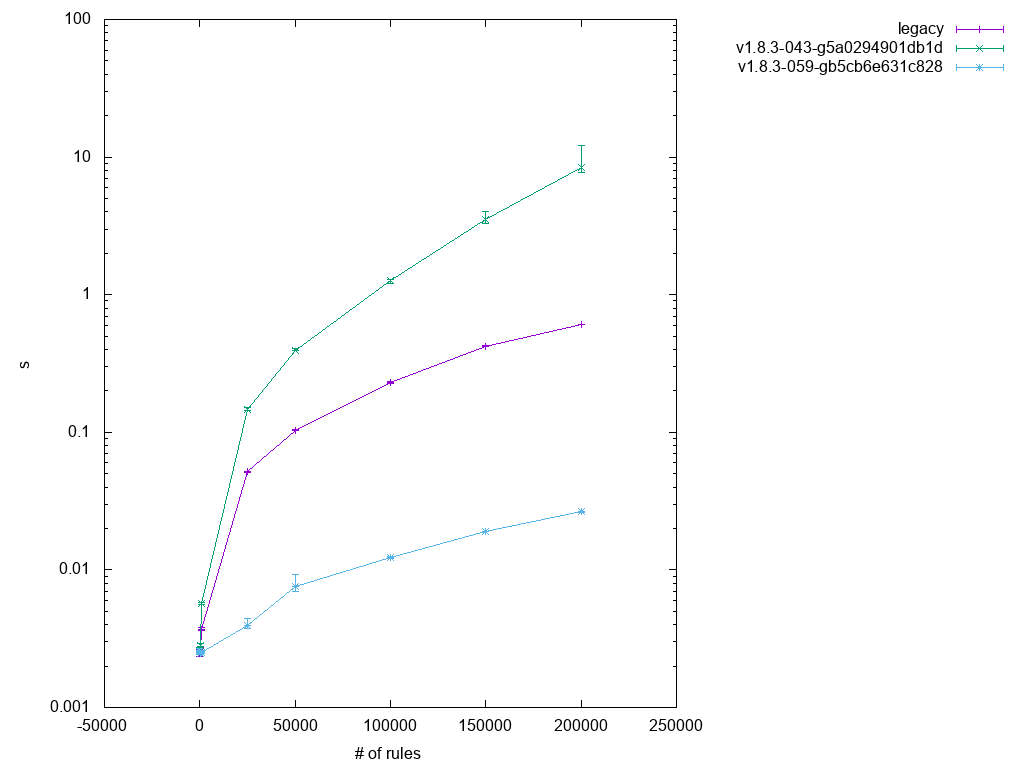
The kernel ruleset is fetched via netlink in chunks of up to 16KB at once, determined by user-space buffers. The kernel, though, supports dumping twice the data at once, and all it took was to double the user-space receive buffer size—a simple fix that improved performance at the large scale of every test that involved caching, in ideal situations by as much as 50%.
Figure 4 is a perfect example of how performance increasingly improved with larger rulesets. The reduced incline of the blue curve also indicates slightly better scaling, although it is still much worse overall than legacy iptables.
Caching chains but not rules
The first real caching optimization was to skip fetching rules if not needed. Taking tests 2.1 and 2.3 as simple examples, there is no reason that the runtime of the rules append or insert (at the beginning of the chain) should depend on the number of rules already in that chain.
Implementing this feature was a simple task. The back-end code in iptables-nft has the function nft_chain_list_get that is supposed to return a linked list of chains that a given table contains. The call to the nft_chain_list_get function implicitly triggered full cache population (unless the cache is already fully populated). I changed this function to fetch only the table's list of chains and make callers request a full-cache update if needed.
To my own surprise, this change significantly improved the results for eight benchmarks. Half of them started to show O(1) complexity (i.e., a constant runtime irrespective of the scaling value). In detail, the results were:
- Tests 2.1, 2.3, 2.14 and 4.1: Runtime still depends on scaling, but performance is constantly better than legacy
iptables. In these cases, the bottleneck is on the kernel side, and user space is already perfect. - Tests 2.6 and 2.13: Constant runtime, performance on par with legacy. This shows that legacy
iptablescan avoid caching in some cases and that its cache is per table. - Tests 2.4 and 2.12: Constant runtime, legacy performance depends on scaling value. Those are the real jewels, a no-op in both user and kernel space, delayed only by inflexible caching in legacy
iptables.
Selective rule cache per chain
Previous changes' results were a good motivation to push even further into that direction, namely to not just decide whether a rule cache is needed or not, but also for which chain(s). This way a large chain won't slow down rule-cache-requiring operations on other chains like it did in tests 2.5, 2.7 and 2.11.
Implementing this change felt natural since there are code paths that accept an optional chain name, like the --list command. My approach was to extend the signature of the nft_chain_list_get function to accept this chain name. If non-NULL, the called code will fetch only that specific chain from the kernel instead of a full chain dump per table. Consequently, the returned chain list contains only a single entry. In addition to that, I changed the full cache update routine (nft_build_cache) to accept that optional chain name as well, so rule fetching can also happen per-chain.
A downside of the above is that the code has to be aware of partial caches. If a full cache update would follow a partial one, we would end up with duplicate entries. Therefore, routines inserting chains into cache must skip already existing ones. This logic is not possible for rules, so the rule cache update is simply skipped for chains that already contain rules.
Streamlining compatibility checks
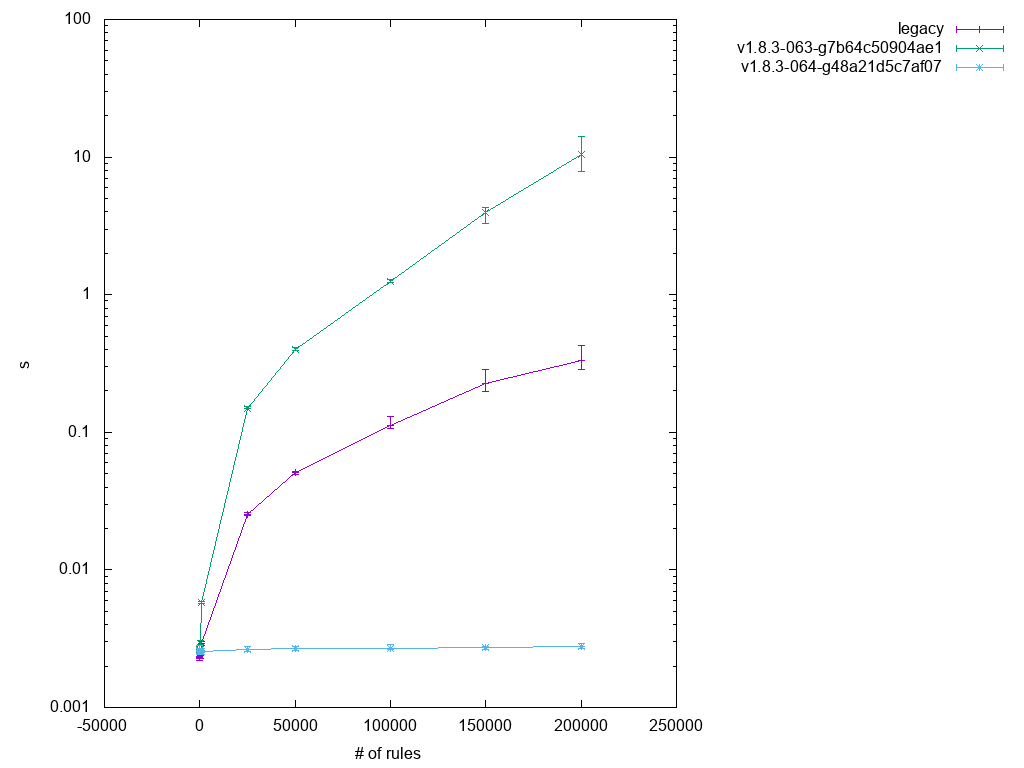
An interesting problem is highlighted by the fact that previous optimizations failed to improve test 2.10, although it should be covered. The reason was hidden in a sanity check performed for "list" commands, because iptables-nft needs the ruleset parts it cares about in a compatible state: Base chains need to have the right name and priority, rules can't contain unknown expressions, etc.
This ruleset "preview" was a bit clumsy in that it applied to all table contents, not just the relevant ones. After making it more fine-grained, test 2.10 started giving expected results as well, as you can see in Figure 5.
Optimizing the flush command
Flushing every chain in a table performed poorly, as expected, with a large number of chains because iptables-nft had to fetch the full chain list and create flush requests for each of them. More by coincidence than intention, I noticed that the kernel already supported flushing all of a table's chains in one go, namely by omitting the chain name attribute from the respective netlink message.
If it wasn't for verbose mode, this would be a trivial fix. But since legacy iptables in verbose mode prints each flushed chain's name, iptables-nft has to fall back to the old logic in case the user passed --verbose.
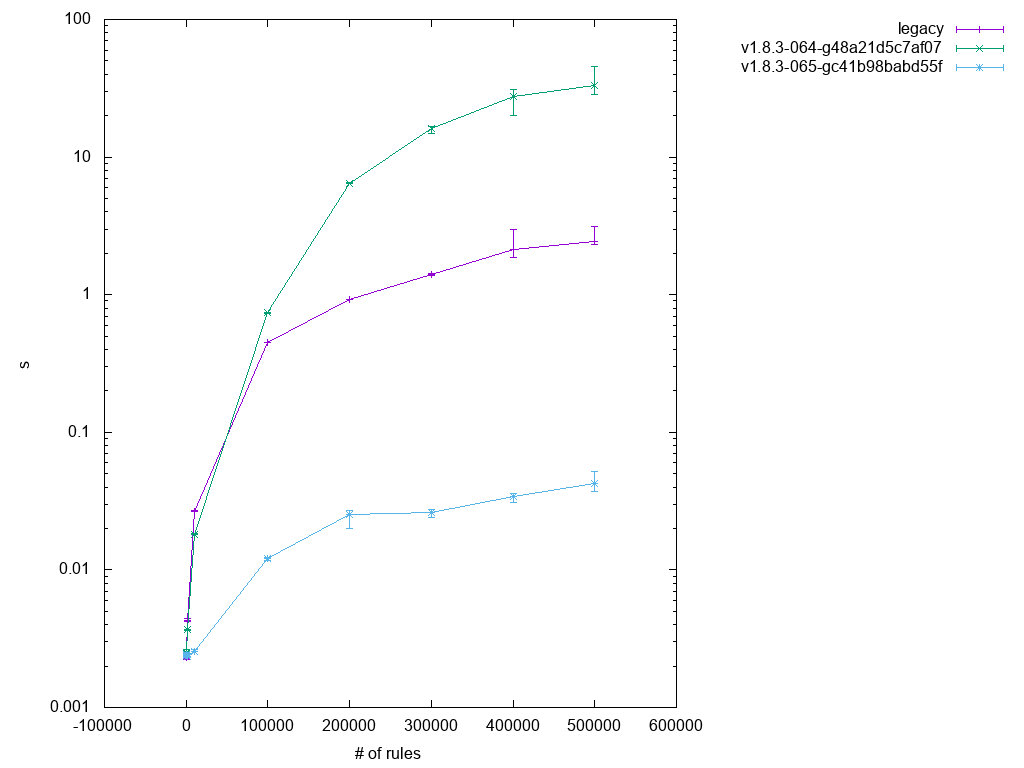
Scaling still looks a bit "funny" in test 3.1 as shown in Figure 6, but that's probably due to kernel code scaling not as well as user space.
iptables-nft-restore --noflush
Sorting cache management in iptables-nft-restore required a bit more effort than in the other tools. The problem was mostly caused by the fact that the input is not known. Assume that after handling a few commands that don't require a rule cache (simple --append commands for instance), the input contains a command that does require a rule cache (for example, --insert with index). That situation means that previously added rules would have to be merged with the rules fetched from the kernel after the fact. With the option to either insert a rule (at the beginning) or append a rule (at the end), fetched rules would potentially go somewhere in between the previously added ones.
In order to avoid this problem and possibly others related to inconsistent caching, I decided to try a different approach and buffer input up to a certain amount. The relevant changes might be found in commit 09cb517949e69 ("xtables-restore: Improve performance of --noflush operation"). In this case, a buffer of 64KB is used to store input lines after testing them for cache requirements. This process continues until either:
- Buffer space is exhausted.
- The input stream signals end-of-file.
- A command is read that requires a rule cache.
With input buffering in place, test 5.1 started to show perfect results, as you can see in Figure 7.

Loose ends
Some test cases remain unoptimized, which means that iptables-nft's performance is worse than that of legacy in those situations. Here's why: Tests 2.2, 2.8, and 2.9 are slow because nftables identifies rules by handle, and a translation from either rulespec or index is required in any case. Since nftables doesn't support fetching a specific rule (for example, by index), user space has no leeway for optimization here. A partial fix would be to implement rule identification by index in the kernel, but in the past this approach was frowned upon due to its inherent concurrency problems.
All of the (flushing) restore tests (1.1, 1.2, and 1.3) remain slow, but that sounds worse than it actually is, looking at the initial test results of 1.3 as shown in Figure 8.
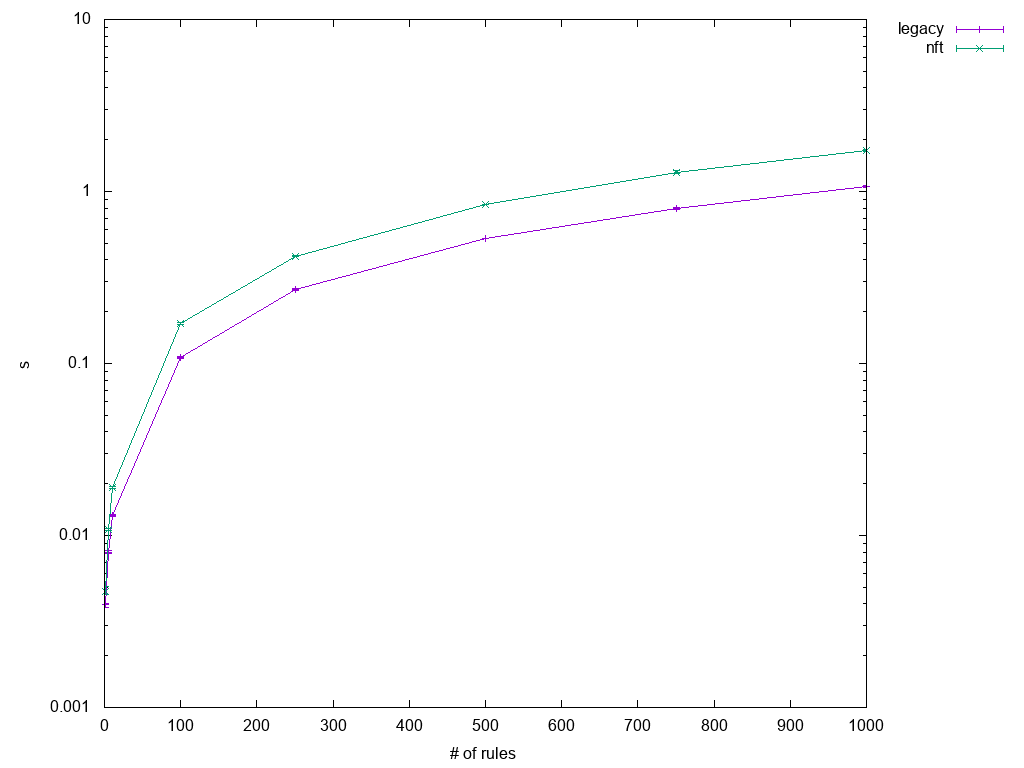
These results show that iptables-nft is slower by a factor ranging from about 1.2 to 1.7. In other
words, restoring a dump containing a little over 200k lines takes 1.7s instead of 1.0s. Along with very similar scaling, I suspect that the culprit is slightly less optimal code or the fact that data has to be packed into netlink messages instead of being copied to the kernel in one go via ioctl.
Summary
The good news is that iptables-nft now outperforms legacy iptables by a large degree in most cases, and doesn't lose much ground in others. This testing also shows how well-prepared nftables kernel code is for high loads despite the somewhat inelegant nft_compat module to use the kernel's xtables extensions. So, while migrating to nftables and making use of the extra goodies is still the best path to maximum performance, swapping iptables variants behind the back of legacy applications might be an effective performance regimen.
Of course, all of these results are to be taken with a grain of salt. On one hand, I certainly forgot specific use cases—all of my tests combined probably don't even reach full code coverage. On the other hand, a sophisticated ruleset leveraging what legacy iptables has to offer (including ipset) will likely prevent user space tool performance from becoming the problem in the first place.