For the last two years, I have been trying to improve CRuby performance. I have been working simultaneously on two major fronts: introducing register transfer language (RTL) for the CRuby virtual machine (VM) and just-in-time (JIT) compilation. For background on the goal of having Ruby 3 be 3 times faster than version 2 (3X3), see my previous article, "Towards the Ruby 3x3 Performance Goal".
The JIT project (MJIT) is advancing successfully. The JIT approach and engine I proposed and implemented has been adopted by the CRuby community. Takashi Kokubun hardened the code and adapted it to the current CRuby stack machine and recently MJIT became an experimental feature of the CRuby 2.6 release.
Introducing a Register Transfer Language (RTL) to the CRuby VM turned out to be an even harder task than introducing the initial JIT compiler. The required changes to the VM are far more invasive than the ones needed for the JIT compiler.
This article describes the advantages and disadvantages of RTL for CRuby.
What is RTL?
First of all, what is RTL? The current CRuby VM uses stack instructions. Here is an example of stack instructions for the Ruby code a = b + c, where a, b, and c are local variables:
getlocal_OP__WC__0 <b index>
getlocal_OP__WC__0 <c index>
opt_plus
setlocal_OP__WC__0 <a index>
The first two instructions put the values of local variables b and c on the VM stack. The third instruction takes both values from the stack, performs the addition and puts the result on the stack. And the last instruction takes the result from the stack and assigns it to local variable a.
The stack instructions refer to operands implicitly from the top of the stack. Therefore, they are simple and short.
We could use instructions referring to operands explicitly. I use the terms register transfer language and RTL for a set of such instructions. I use these names because I have been working on the GCC project for a long time and GCC has an intermediate representation with explicitly referenced operands called RTL.
Here is how the above example would look in RTL:
plus <a index>, <b index>, <c index>
Instructions in RTL are longer but there are fewer of them for the same code. Usually RTL is interpreted faster because a smaller number of executed instructions results in less instruction-dispatching overhead and less memory traffic for operand values, which is more important for modern computers with a bigger gap in speeds of CPU and memory.
Faster interpretation is one reason for adopting RTL. There is another more important reason to use RTL. To improve CRuby performance significantly, we need a convenient intermediate representation (IR) for analysis and transformation of Ruby code. It is hard to do this at the stack instruction level. Therefore, optimizing compilers never use stack instructions.
Stack instructions are a good representation for an interface language because of their simplicity and compactness. Stack instructions of WASM or Java bytecode are examples of interface representation. Optimizations and code transformations are done on instructions with explicit operands like LLVM IR or even on instructions containing both data- and control-flow dependencies like Graal IR.
Additional RTL instructions
To further improve RTL interpretation performance, initially, I added specialized, combined, and speculative instructions.
When we know an operand value during RTL generation, we can use a specialized instruction. Here is an example where we can use plusi, an addition with immediate value operands (t<index> and l<index> denote indices of temporary and local variables, correspondingly):
val2temp t1, 42 plus t2, l1, t1 --> plusi t2, l1, 42
Usually, RTL code contains frequently used pairs of instructions. We can combine such pairs into one combined instruction. Here is an example where we can use btlt, a combined instruction for comparison and branch:
lt t1, l1, t2 bt Label, t1 --> btlt Label, l1, t2
Using specialized and combined instructions decreases the number of instructions and the overall code size.
Usually, one CRuby VM instruction can perform operations on a few different types. For example, the plus instruction can perform both integer and floating point addition. If the operand types are known to be the same, we can use a simpler instruction that works only for given operand types.
Speculative instructions are generated during code interpretation. The original instruction checks the operand types. If they are the same, the instruction modifies itself into a speculative instruction, which works only for the given operand types. The speculative instruction still checks the operand types, and if they are not what is expected, the speculative instruction modifies itself into an unchangeable instruction, which works on all operand types just as the original instruction, but it never modifies itself.
For example, a plus instruction can be changed into iplus or fplus, which work only on integer or floating point operands, respectively. If a speculative plus instruction receives operand values of unexpected types, it is changed into the instruction uplus(unchangeable plus), which works for any operand types. And the instruction uplus is never changed afterwards.
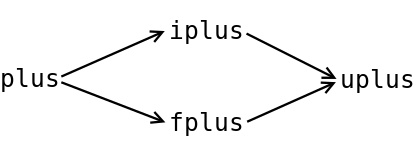
For interpretation usage, speculative instructions are probably unprofitable, because they still perform operand type checks. But these instructions will be quite important for JIT compilation, because they help to perform speculative optimizations. They also create large extended basic blocks in JITted code, which are optimized fairly well by JIT compilers.
Generally speaking, we can add specialized, combined, and speculative instructions to stack instructions too, but this makes little sense when the stack instructions are used as an interface language because such instructions will mostly complicate the interface.
It is a rare case when one solution has only advantages over another one. Introducing RTL is not an exception. I would not be honest if I omitted the following RTL drawbacks here:
- First of all, RTL code is usually longer. RTL could be slower too when operand processing overhead and worse code locality outweigh smaller instruction dispatching overhead and less value memory traffic. Usually, this happens when RTL code has the same number of instructions as analogous stack instruction code. A typical case is code containing only call instructions where operands are processed only in stack mode.
- Execution of RTL code consumes more memory on the VM stack. This can happen when non-call RTL instruction execution results in a call to another RTL instruction sequence. For example, an RTL
plusinstruction could receive an object as the first operand and the object class could have a method+written in Ruby. Most of the time during RTL execution, we maintain a stack pointer with an address of the location after all stack slots for the temporary variables. With such an approach, we do not need to track stack pointer changes and we can easily implement different RTL optimizations involving instruction removal and moves. By the way, the same approach is used by most C compilers: they generate function code that sets up and keeps a stack pointer referencing the location after all stack slots for (user and temporary) variables of the function. More memory consumption on the stack would be not a problem if we had one stack. Because Ruby has threads, each thread has own stack, and currently, we need to reserve memory for each thread's stack for the worst-case stack consumption scenario; an increase of the stack memory reservation for RTL will be multiplied by the number of threads.
Fortunately, the Ruby developers are working on implementing variable length stacks, because fixed length stacks will be a problem for Ruby code in the future when a new concurrency model will permit parallelism and will open the opportunity to use a much larger number of Ruby threads. - When we use stack instructions, all parts of the stack corresponding to a method written in Ruby always contain valid Ruby values. If the value has two zero final bits, it is a pointer to some object in the heap. For RTL, this might be not true, because the values of some stack slots might be undefined or contain obsolete data, for example, pointers to objects already garbage collected. Therefore, in the case of RTL, the garbage collector should treat stack slot values conservatively. If the value looks like a pointer to an object in the heap, we treat it as a pointer even if it is not, for example, even if it is undefined random data. It is a bit more expensive to process the stack values conservatively (we need to check that the value appearing to be a pointer is some address in the heap) and there is a very small possibility that an object is not garbage collected although it should be. CRuby already has code for conservative value treatment for parts of the stack corresponding to methods written in C. We just reuse this code for the RTL implementation.
Recent RTL development
I already described the RTL project in my blog post a year ago. A lot has happened for the project since then. Here is a description of the recent RTL development work.
New RTL code generation
Initially, I implemented RTL code generation directly from CRuby AST in place of the generation of stack instructions. In this approach, there is no additional RTL generation overhead, but there is also no place for the current stack instructions.
Unfortunately, the stack instructions interface is already open to the Ruby programmer. There are Ruby applications that directly handle stack instructions, for example, a Ruby debugger. Also, the Ruby programmer can generate stack instructions during Ruby code execution or save them in persistent memory and load them later into the VM to save time on compiling Ruby source code.
After a discussion with Koichi Sasada, author of YARV and the current stack instructions, I decided to re-implement RTL generation. Instead of AST, RTL should be generated from stack instructions. It could be done after stack instruction generation or after loading stack instructions from persistent memory.
For the past year, I have been working on this implementation. In my presentation at RubyKaigi 2017, I said that it would be simpler to generate RTL from stack instructions instead of the abstract nodes. This turns out to be true only if we don't care about the generation of good RTL code. Here is an example of how to generate unoptimized RTL code. You just need to use temporary variables for all instruction results.
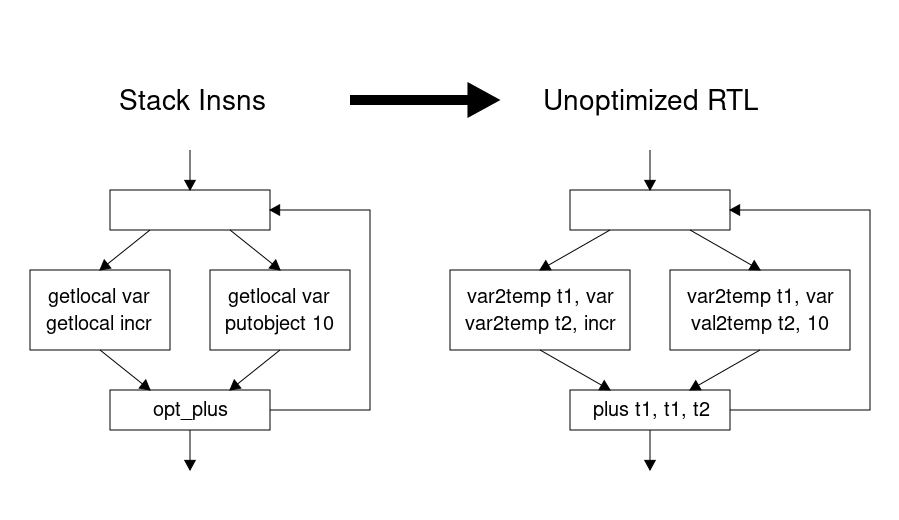
RTL allows us to use local variables and immediate values as instruction operands. Here is optimized code that can be generated for the same example. We can remove two instructions putting the same local variable value on the stack.
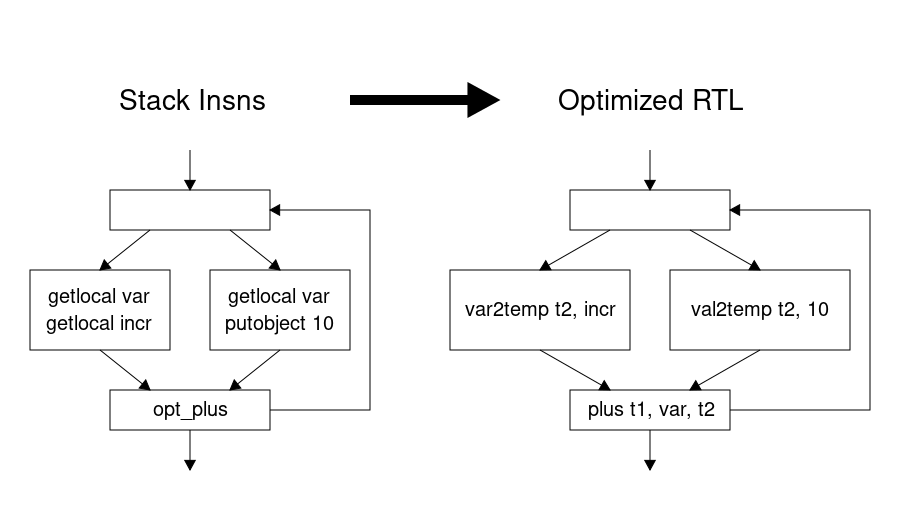
To generate optimized RTL, we need to know what each stack slot contains, for example, a known constant value or some local variable value. If the stack slot may contain different values on a join point of the control-flow graph (CFG), we should put these different values into the same temporary variable.
I will not describe in detail how to get such information. It is defined by the following forward data flow problem, whose solution is based on lattice theory:
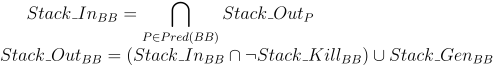
Here, Stack_In and Stack_Out are states of the stack at the start and at the end of a basic block (BB). Stack_Kill and Stack_Gen define changes of the stack state in the given basic block (BB). Possible stack slot state changes are described by the following lattice.
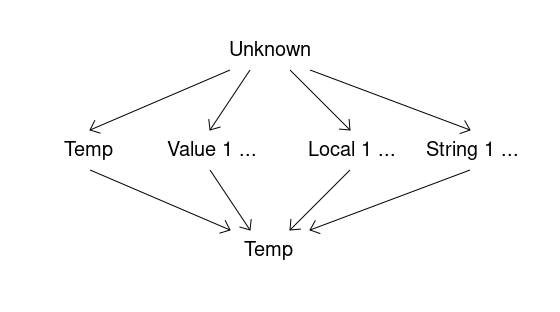
For example, if a stack slot state is unknown in one immediate predecessor BB in the CFG and set to some known value in all other immediate predecessor BBs, the stack slot state will be the known value at the BB start.
If a stack slot state is known to have a value of some local variable in all predecessor BBs, the stack slot state will be the local variable at the BB start. If the states of the predecessors have values of different local variables, the stack slot state will be a temporary variable at the BB start (in this case, we must generate moves of the local variables into the temporary variable in the predecessors), and so on.
I was afraid that RTL generation might be time-consuming. Fortunately, that is not the case. It adds less than 1.5% to the overall compilation time of the Optcarrot benchmark.
By the way, you can also optimize RTL code by using classical constant folding and copy propagation and dead code elimination. But such optimizations will be slower than my approach because they will need more passes.
RTL generation removes a lot of nop instructions but sometimes the generation adds other new nop instructions. This happens when there is no direct correspondence between the original stack and generated RTL instructions and we need nop instructions to correctly mark exception handling and instruction tracing boundaries.
New RTL instructions
To decrease RTL code size, I've added new specialized RTL instructions for numerous cases when operands are processed in stack order. For example, if we have an RTL instruction plus <index -1>, <index -1>, <index -2>, which takes temporary stack slots with index -1 and index-2 and puts the result into stack slot with index -1, we can use the simple instruction splus <index -1>.
CRuby has a generational garbage collector, and every time we assign a value to a (non-temporary) variable, we should inform the garbage collector about this. So for the result of the RTL instruction, we should check that the result is not a temporary variable and call the garbage collector after that.
Although the check is small, it might considerably decrease RTL interpretation speed. I found that in most cases, faster code can be generated for the interpreter if we use only temporaries as RTL instruction results and generate an additional move instruction if we need the final result to be stored in a local variable.
For MJIT, such a constraint on RTL instruction results would not be necessary, because an optimizing compiler can easily remove the check.
RTL code merging
Since the start of my work on RTL and JIT, I never merged trunk into my development branch. This was a big mistake. CRuby is developed at a very fast pace. A lot of changes were made in the VM code by Koichi Sasada and to MJIT by Takashi Kokubun during the last two years.
Merging 2 years of changes to the trunk into my CRuby RTL branch took 6 months. I spent 50% of my work time on CRuby development. So it means that one year of CRuby development needs 1.5 months of my work to merge trunk changes into my CRuby RTL branch. This says a lot about the invasiveness of the changes required to implement RTL in CRuby.
But finally I have fresh RTL CRuby code very close to the CRuby 2.6 release and I can compare RTL CRuby performance in the interpreter and JIT modes with the performance of trunk CRuby on the latest merge point.
Performance comparison of RTL CRuby and trunk CRuby
For an RTL and stack instruction comparison, I used an Intel i7-9700K machine with 16GB of memory under Linux Fedora Core 29. I compared the RTL version of CRuby and the trunk at the latest merge point with the RTL branch. The comparison information below is always given for the same modes (CRuby interpreter only and CRuby with JIT usage).
Each benchmark ran three times and the best result was used. For wall and CPU time, this is the smallest time. For peak memory consumption, this is the smallest maximum resident size of the CRuby process.
I used micro and small benchmarks. You can find these benchmarks in the directory MJIT-benchmark in my repository on GitHub.
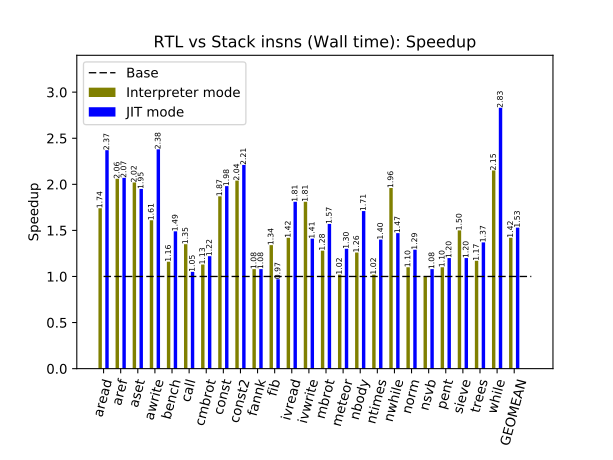
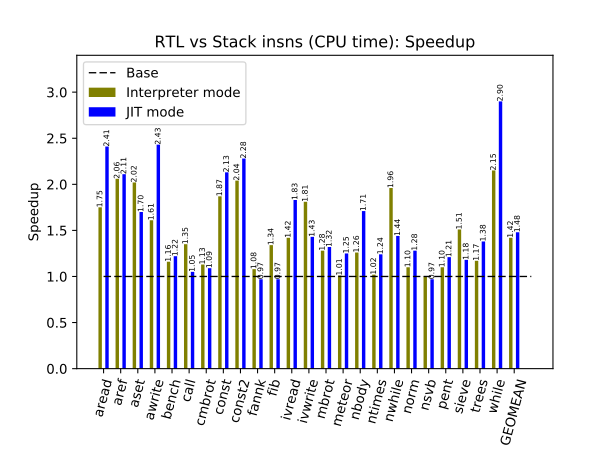
As you can see, the RTL version of CRuby is about 40% and 50% faster, respectively, in the interpreter and JIT modes. Nine months ago, the RTL version with the JIT compiler was almost two times faster but, thanks to Takashi Kokubun, MJIT with stack instructions was improved considerably since then.
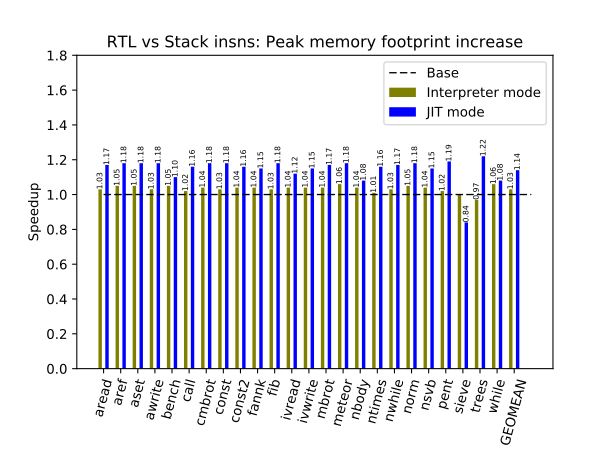
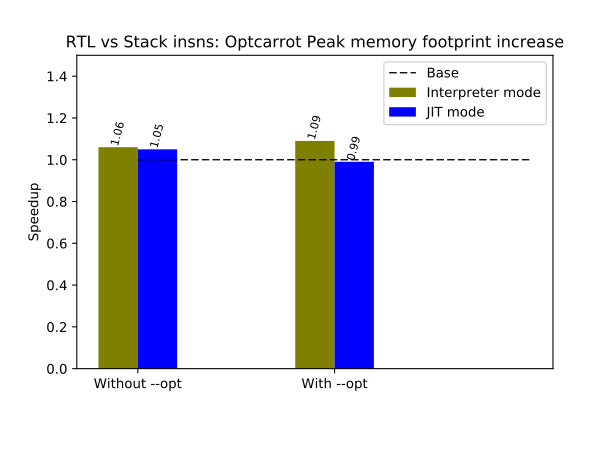
Peak memory consumption is about 3% and 14% more, respectively, in the interpreter and JIT modes for the RTL version of CRuby. The major reasons for this are:
- The code of the RTL version of CRuby is simply bigger.
- We have to keep two versions of the Ruby bytecode: stack and RTL instructions.
- We increased the VM stack size for Ruby processes to pass CRuby tests with deep recursion because RTL code execution can consume more memory on the VM stack.
I also used Optcarrot for benchmarking. It is a medium-size Ruby program that emulates a Nintendo game computer. The number of generated frames for the picture processing unit (PPU) of the emulated computer defines how long the program runs. I used 2,000 frames for Optcarrot. There are two versions of Optcarrot code. One is an unoptimized version and the other is manually optimized. To run the optimized version, the option --opt should be used.
Here are the results.
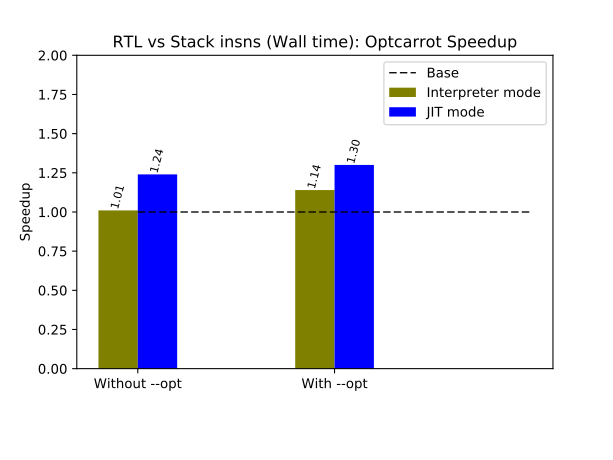
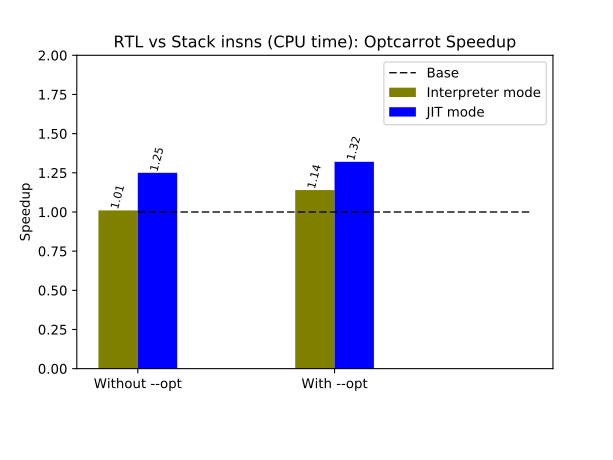
The RTL version of CRuby runs up to 30% faster.
Ruby-specific RTL optimization
To demonstrate the RTL advantage for Ruby code analysis and transformation, I recently implemented redundant code removal for boxing and unboxing floating point values.
CRuby uses so-called tagged values. Let us consider 64-bit machines because they are most commonly used these days.
Many values are just pointers to the objects in the heap. Because the objects in the heap are 8-byte aligned, the last three bits of the pointers are always zero.
Fixnum values use 63 bits and have binary tag 1. Larger integer numbers are represented by multiple-precision numbers in the heap.
Floating point values use 62 bits and have binary tag 10.

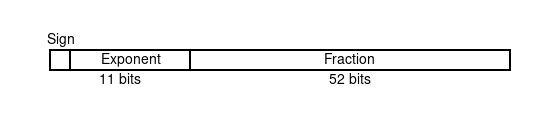
Most computers use the IEEE standard for floating point arithmetic. According to the standard, double floating point numbers have one bit for the number sign, 11 bits for the binary exponent, and 52 bits for the mantissa (also called a fraction).
So how can CRuby fit a 64-bit double into 62 bits? CRuby can do this only for a subset of all possible double values. The numbers outside the subset are kept in the heap.
CRuby could keep fixed 2 bits from the mantissa or sign. But this would be a very bad idea because probably about 3/4 of all numbers would be stored in the heap. The only reasonable choice is to keep fixed 2 bits in the exponent. The exponent range is too big and most programs use only a very small part of it.
CRuby uses this approach. It fixes 2 bits in the exponent. The exponents with fixed bits are in the range from minus 255 to 256. I call the transformation of double floating point values from and to CRuby 64-bit values unboxing and boxing, respectively.
Here is the C code used by CRuby to box an IEEE double floating point value d:
union { double d; VALUE v; } t; int bits;
t.d = d;
bits = (int)((VALUE)(t.v >> 60) & 0x7);
if (t.v != 0x3000000000000000 /* 1.72723e-77 */ && !((bits-3) & ~0x01)) {
return (RUBY_BIT_ROTL(t.v, 3) & ~(VALUE)0x01) | 0x02;
}
else if (t.v == (VALUE)0) { /* +0.0 */
return 0x8000000000000002;
}
/* else create heap representation */
This is very clever and well-optimized code. I will not explain how the code works. It is not necessary for describing the boxing/unboxing optimization. If you like puzzles, you can figure out what this code actually does.
And here is the C code for unboxing a floating point value v:
union { double d; VALUE v; } t; int bits;
if (v != (VALUE)0x8000000000000002) { /* LIKELY */
VALUE b63 = (v >> 63);
t.v = RUBY_BIT_ROTR((2 - b63) | (v & ~(VALUE)0x03), 3);
return t.d;
}
return 0.0;
The CRuby JIT compiler (MJIT) uses GCC or LLVM to generate machine code. For this pair of Ruby multiplication statements:
r *= m
r *= m
the JIT-generated code can be roughly represented by the following pseudocode:
d1 = unbox r
d2 = unbox m
d1 = d1 * d2
r = box d1 // redundant
d1 = unbox r // redundant
d2 = unbox m // redundant
d1 = d1 * d2
r = box d1
where d1 and d2 are C double floating variables.
No optimizing compiler, including GCC or LLVM, can remove redundant unboxing and boxing code. So we need to optimize this ourselves.
Here is simplified RTL for the multiplication statement pair:
mult t1, l4, l3
temp2loc l4, t1
mult t1, l4, l3
temp2loc l4, t1
where l3 and l4 denote local RTL variables for the Ruby variables m and r, respectively.
After interpreting this RTL code several times, the RTL mult instructions are transformed into speculative floating point mult instructions fmult:
fmult t1, l4, l3
temp2loc l4, t1
fmult t1, l4, l3
temp2loc l4, t1
When MJIT generates code for the RTL speculative instructions, we know that the result of a speculative floating point instruction is always a floating point value in the JITted code. If the result is not a floating value for some reason, the speculative instruction would be transformed into the non-speculative form, the execution of the generated machine code would be canceled, and we would switch to the interpretation of the new non-speculative code.
When we know that the result is a floating point value, we can reuse the unboxed double floating value in subsequent instructions. That gives a very brief idea of the optimization.
In more detail, we build a control flow graph of the RTL code (basic blocks of RTL instructions and edges between them describing possible control flow) and determine which local or temporary variables contain floating point values at the beginning and at the end of each basic block, solving the following forward data flow problem:
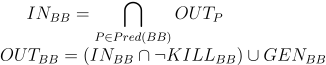
Here, In and Out are local and temporary variables known to contain floating point values at the start and the end of a basic block. Gen defines local and temporary variables containing a floating point value at the end of a basic block because the variables are results of speculative floating point instructions in the basic block. Kill defines local and temporary variables whose values might become a non-floating point value at the end of the basic block. For example, a local variable used as a result of a generic arithmetic instruction in a basic block is killed in the basic block.
Then we use this information to generate JITted code, which reuses unboxed values where possible.
How profitable could this optimization be?
Let us consider the Ruby code:
def f
r = 2.0; m = 1.001
i = 0
while i < 1_000 do
r *= m; r *= m; r *= m; r *= m; r *= m
r *= m; r *= m; r *= m; r *= m; r *= m
i += 1
end
r
end
r = 0.0
100_000.times { r = f}
p r
The following bar-chart contains elapsed time in seconds of Ruby code execution on the Intel i7-9700K for different CRuby usage modes:
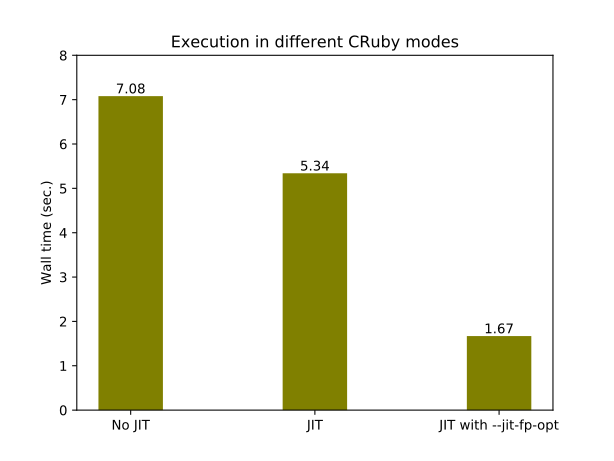
So the optimization improves JITted code by 3.2 times for this example.
It is very hard to implement this optimization using stack instructions where temporary variables are not represented explicitly. The optimization also needs speculative instructions that are absent in the current stack instruction set.
Analogously, RTL could be used for escape analysis to avoid object creation in the heap, which could considerably speed up execution for some cases.
Conclusion
In this post, I've tried to show the advantages and disadvantages of RTL for CRuby. From my point of view, it is worthwhile to seriously consider using RTL for CRuby in the future.
Adding RTL to CRuby will be not an easy task. The change is very invasive to CRuby code, and probably I am not the right person to do this because I am still a novice to CRuby development.
Maintaining the code on the branch requires a lot of effort from me. I think I am done with the RTL project for CRuby and I will spend my efforts on another less-CRuby-code-dependent project that will also be beneficial for improving CRuby performance.
I hope the code and proposed solutions will still be useful for Ruby core developers, and I will be glad to help if someone tries to use them in CRuby.
The RTL implementation sources can be found in my repository on branch stack-rtl-mjit. For easy comparison of RTL and stack VM implementations, this branch is always based on a branch containing only trunk changes, which currently is pretty close to the CRuby 2.6 release.
Other Ruby performance articles on Red Hat Developers
- Towards the Ruby 3x3 performance goal
- Towards faster Ruby hash tables
- Making the operation of code more transparent with SystemTap
- "Use the dynamic tracing tools, Luke"
Last updated: February 6, 2024