This blog post is about my work to improve CRuby performance by introducing new virtual machine instructions and a JIT. It is loosely based on my presentation at RubyKaigi 2017 in Hiroshima, Japan.
As many Ruby people know, the author of Ruby, Yukihiro Matsumoto (Matz), set up a very ambitious goal for performance of CRuby version 3. Version 3 should be 3 times faster than version 2.
Koichi Sasada did a great job improving the performance of CRuby version 2 by about 3 times over version 1, by introducing a byte code virtual machine (VM). So I guess it is symbolic to set up the same goal for CRuby version 3.
I do a lot of GCC benchmarking and I found that benchmarking is a very sensitive topic. People always disagree practically on everything about benchmarking: what benchmarks to use, what options to use, how to measure, even how to present the results. When you implement a new GCC optimization, frequently somebody can provide a benchmark on which the optimization produces negative results.
So I'd rather not touch the topic of what benchmarks should be used as a criteria for achieving the CRuby version 3 performance goal. I just consider Matz's goal as that of CRuby needing another cardinal performance improvement.
1. RTL Instructions
To achieve a cardinal performance improvement we need a convenient intermediate representation (IR) for analysis of Ruby programs. It is also necessary to implement optimizations and JIT code generation.
Analysis of data dependencies is key for such goals. It is hard to reveal dependency information from stack machine instructions. Therefore stack machine instructions are never used in optimizing compilers. Usually optimizing compilers use tuples explicitly containing operands and results. For example, GCC has one intermediate language of this kind. It is called register transfer language (RTL). So I decided to use the same term for the new intermediate representation in CRuby.
Here you can see how code which adds values of two local variables and puts the result into another local variable looks with the current CRuby stack machine instruction set and with the proposed RTL IR.
For stack instructions, we first put the values of local variables b and c on the stack, then the opt_plus instruction takes them from the stack, adds them and puts the result back on the stack. The last instruction takes the result from the stack and assigns it to the local variable a:
getlocal_OP__WC__0 <b index>
getlocal_OP__WC__0 <c index>
opt_plus
setlocal_OP__WC__0 <a index>
For RTL, we have just one plus instruction with explicit operands and result:
plus <a index>, <b index>, <c index>
1.1. Using RTL Instructions for Interpretation
As I mentioned previously we need RTL for analysis and JIT code generation. We can also use it for interpretation. There is a lot of literature (e.g. here is my article or another frequently cited article) saying that RTL instructions are faster for interpretation than stack based instructions. That is because RTL needs fewer instructions to execute the same code and this results in less instruction-dispatching overhead. Another reason for faster RTL interpretation is less memory traffic for instruction operands and results. This reason is frequently omitted in the literature. For recent CPUs, dispatching is less important because modern processors have better branch prediction units. Less memory traffic for operands and results of RTL instructions becomes the more important factor. However, which factor is more important might change after fixing the recently found Specter vulnerability.
Ruby is a very dynamic programming language. A programmer can even redefine built-in operators such as the plus operator for integer numbers. As a result a typical VM instruction in CRuby has to do a lot of things. Therefore the effect of switching to RTL is smaller than for other, less dynamic languages.
In some cases, stack machine instructions can work better than RTL. Here is a table showing features of stack and RTL instructions. Bold font is used for features that work in favor of particular instructions:
| Feature | Stack insns | RTL insns |
|---|---|---|
| Insn length | shorter | longer |
| Insn number | more | less |
| Code length | less | more |
| Operand decoding | less | more |
| Code data locality | more | less |
| Insn dispatching | more | less |
| Memory traffic | more | less |
Whether one instruction format has advantage over the other depends on circumstances.
For example, if we have the same number of instructions, stack instructions will be interpreted faster because of less operand-decoding overhead, smaller size, and better data locality. This might happen for code mostly consisting of method calls where operands are processed in a stack mode.
Because faster RTL interpretation is a common opinion I've decided to use RTL for the interpretation too.
Using RTL for interpretation also simplifies the JIT implementation because we can share a lot of C code executing RTL instructions between the interpreter and JITted code. This is based on heavy use of C inline functions. For example, a part of the code implementing the RTL plus instruction looks like this:
static inline int plus_f(rb_thread_t *th, rb_control_frame_t *cfp,
CALL_DATA cd, VALUE *res,
rindex_t res_ind,
VALUE *op1, VALUE *op2) {
if (FIXNUM_2_P(*op1, *op2))
&& BASIC_OP_UNREDEFINED_P(BOP_PLUS,
INTEGER_REDEFINED_OP_FLAG)) {
*res = fix_num_plus(*op1, *op2);
return 0;
} else if (FLONUM_2_P(*op1, *op2)
&& BASIC_OP_UNREDEFINED_P(BOP_PLUS,
FLOAT_REDEFINED_OP_FLAG)) {
...
}
...
}
This function is called from the interpreter and also in lined into code generated by the JIT.
1.2. RTL Generation
There are two major approaches to generating RTL instructions. We could generate them from stack instructions. As we use RTL instructions for interpretation, I assumed that stack instructions would live only during RTL generation. Therefore at first I thought that generation of RTL directly from CRuby AST nodes is a better approach. So I completely rewrote CRuby's compile.c file to generate RTL from the AST nodes.
But after some discussion with Koichi Sasada, I realized that this is not the right approach. The existing stack instructions are already a part of CRuby's public interface. There is for example a Ruby debugger using them. So for compatibility reasons the only possible approach is to retain stack instructions as an intermediate step in RTL generation. Currently I am working on the generation of RTL from existing stack instructions.
1.3. RTL Operands
There is an interesting question of what kind of variables and values should be used as operands of RTL instructions. We could only use temporaries and have special instructions to load and store them into local variables or into instance variables. This makes little sense for interpreter performance, as we will have the same number of instructions as in the case of stack machine instructions, only the RTL instructions will be longer.
We could allow instance variables as operand. We could do the same for local variables from other scopes. This will complicate operand decoding. It will also complicate the JIT implementation as RTL is used for JIT code generation. I did some experiments with using different operands and found that using only temporaries and local variables from the innermost scope gives the best performance results.
1.4. RTL Complications
There are some complications with implementing RTL for CRuby. Practically any RTL instruction might actually be a call of a method defined by the Ruby programmer. For example, the programmer can define a different plus method for integers. In the CRuby virtual machine, a call always puts the result on the stack top, which corresponds to some temporary in RTL. However, the destination operand of an RTL instruction is in many cases not a temporary.
We have a solution with small overhead. If an instruction is actually a method call, we change the return program counter to execute a move instruction after the call. This move instruction is embedded as a part of the original instruction. For example, the plus instruction has a move operand opcode as its first operand:
plus <move insn opcode>, <call data>, dst, op1, op2
After the method call, this operand will be treated as the beginning of the special move instruction:
<move insn opcode> <call data>, dst, op1, op2
1.5. RTL Instruction Combining and Specialization
To decrease the size of RTL code and speed up its interpretation, we also generate specialized instructions such as addition with intermediate operands with known fixnum values. Here is an example. (t<index> and l<index> denote indices of temporary and local variables correspondingly):
val2temp t1, 10
plus t2, l1, t1 --> plusi t2, l1, 10
We also combine frequently occurring pairs of comparison and branch instructions:
lt t1, l1, t2
bt Label, t1 --> btlt Label, l1, t2
The specialization and instruction combining optimizations decrease the number of instructions and the overall code size.
1.6. Speculative Instruction Generation
Usually a CRuby instruction performs many checks of operand types. For example, the plus instruction checks the operand types and performs fixnum or floating point addition or string concatenation. If we knew the operand types ahead of time, we could use simpler instructions. We could analyze the program and infer the types. RTL would be a good fit for doing this. But the algorithm would be complicated and reveal only some of the types. And the inferred types would only be true if the basic operations are not redefined.
There is a simpler way to reveal the types. Code executing an instruction can check the operands and transform the instruction into a new one working with the particular operand types. The new instruction still checks the types. If they do not match what was expected, the instruction is transformed into an instruction working with any operand types.
For example, the plus instruction can be changed into iplus or fplus which work only on fixnum or double operands respectively. If these instructions were given unexpected operand types they are changed into the instruction uplus (universal and unchangeable plus), which works with any operands. And this instruction is never changed afterwards.
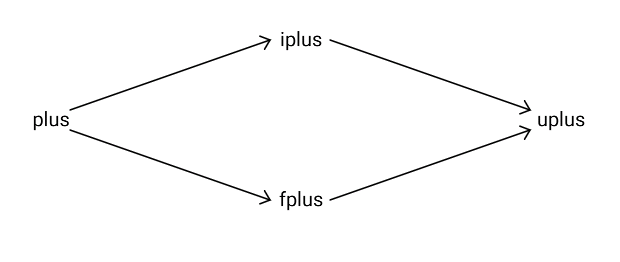
It may seem that speculative instructions are not profitable. They perform operand type checks too, although there are fewer checks. But these instructions will be quite important for JIT, as they create large extended basic blocks in JITted code. C compilers are able to optimize these extended basic blocks pretty well.
1.7. RTL Instruction Status and Future Work
So what is the current status of the RTL instruction implementation? RTL instructions mostly work. There are no regressions on the CRuby test suite. Geometric mean performance improvement is about 27%. That is measured on a set of small benchmarks I use. You can find them in my github repository. Overall, using RTL results in anywhere from 110% faster to 7% slower execution depending on the benchmark. The number of executed instructions on the Optcarrot benchmark is about 23% less with RTL although the overall length of the executed instructions is about 19% more.
As I wrote the above statement, I need to retain stack instructions as an intermediate step in RTL generation. Currently I am spending most of my CRuby work time on implementing RTL generation from stack instructions instead of the already existing generation from AST.
2. JIT
Unfortunately, using just RTL instructions did not bring us significantly closer to the Ruby3x3 performance goal. Only machine code specialized to a particular Ruby program can do this. This actually means we must use JIT compilation. And this is a more interesting topic than RTL.
2.1. JIT Implementation Approaches
There are many possible approaches to implementing a JIT. I considered several of them:
- We could write our own JIT as it was done for Lua, for example.
- We could base our JIT on the widely used optimizing compilers GCC or LLVM.
- And finally, we could use an existing general-purpose or specialized JIT such as JVM HotSpot JIT or Chrome V8.
Let us consider the advantages and disadvantages of these approaches.
2.1.1. Writing Our Own JIT From Scratch
The advantages of implementing our own JIT are complete control over the code, small size, and fast compilation. But it also means huge efforts to implement a decent number of optimizations and port the JIT to new targets, as well as a huge burden for ongoing maintenance.
It could be an interesting project for me but I do not have enough time to implement or even to participate in such a project. Especially when I believe I can reach better results with another approach.
2.1.2. Using Widely Used Optimizing Compilers
A general optimizing compiler could be used to implement a JIT. Here, I seriously consider only GCC and LLVM. They generate highly optimized code. To achieve such a degree of optimization, more than 2 thousand people contributed code to GCC since its version 2.95. GCC and LLVM are widely used and portable. GCC currently supports 49 targets and many more sub targets.
They are reliable and widely tested. For example, each year the GCC community spends a half-year on fixing bugs for the next upcoming GCC release. We have had about 90 thousand problem reports and more than 16 thousand reporters since GCC 2.95.
Also, GCC and LLVM do not create new dependencies as they already are being used to compile CRuby.
Of course, GCC and LLVM compilation speed is worse in comparison with other JITs, but this is mostly a consequence of including many more optimizations.
Perhaps in the future CRuby will also need a faster JIT compiler. But even in this case GCC or LLVM could still be useful as a tier 2 JIT compiler for more frequently running code.
2.2.3. Using Existing JITs
We could use an existing JIT, and there are a few serious JIT frameworks. But, surprise! Practically all of them are already being used for Ruby implementations. This says a lot about Ruby's popularity. So if I use an existing JIT, it would be just a duplication of existing work.
And still, even the best optimizing and widely tested JIT, JVM HotSpot JIT, has fewer optimizations than GCC or LLVM. A lot of GCC optimizations are not implemented in JVM or implemented in a sub-par fashion. For example, JVM autovectorization is mediocre compared to the GCC and LLVM versions.
I saw a report where JVM achieves only 40% of GCC performance on a SHA1 calculation benchmark. Another example is Falcon, an LLVM-based implementation of a Java JIT tier 2 (server) compiler. Falcon can achieve several times better performance than the JVM server compiler on small vector benchmarks.
A couple more examples: WebKit JavaScript moved from LLVM based JIT to its own JIT implementation. They implemented about 20 optimizations and improved compilation speed by about 5 times. Still they reported that the new JIT has practically the same performance on widely used JavaScript benchmarks. Now they have an ongoing burden to maintain their own JIT on several targets.
Another example is a research project done by the Institute of System Programming of Russian Academy of Sciences. I worked there a long time ago and trust their results. They implemented an LLVM-based JIT in JavaScript V8. They achieved slightly better performance than the V8 JIT.
The WebKit and V8 JITs are high quality projects. A lot of smart people are working on them and the performance results in these examples could be considered as pretty close. But in my opinion, GCC and LLVM based JITs are winners especially for long-running server programs. On long running programs, the optimization potential of GCC and LLVM can finally reveal itself. And long-running server programs are a major application domain for Ruby.
2.2. Using GCC or LLVM for Implementing CRuby JIT
I hope that I gave a convincing case to use GCC or LLVM for a Ruby JIT implementation. Still, there are several possible ways to use these compilers.
JITted code is not stand-alone code. It interacts with other parts of the VM. Here I use term environment for the set of VM declarations that JITted code can potentially use.
A popular approach for a JIT based on GCC or LLVM is to use their JIT frameworks, LibGCCJIT for GCC or MCJIT or ORC for LLVM. But we can be even simpler and just generate C code for GCC and Clang. I will use LIBGCCJIT here for a comparison with the approach based on C code generation. That is because I am more familiar with LIBGCCJIT. It was written recently by our Red Hat team member, David Malcolm.
Here is a data flow diagram of both approaches:
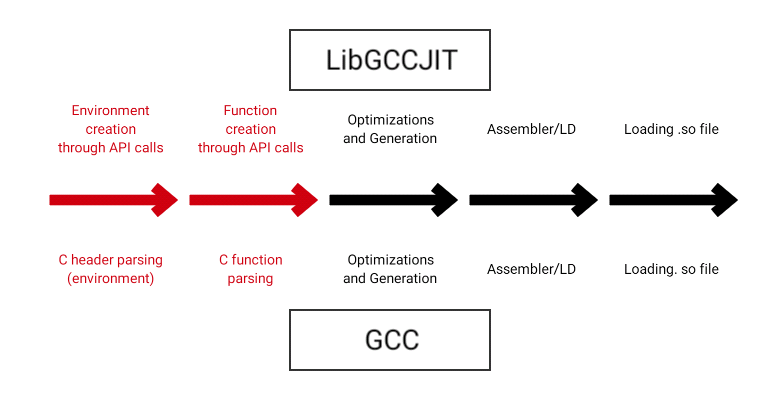
The red stages are different the between two methods. These include creation of C compiler intermediate representation for the environment and the JITted code. If we can make the run time of these stages approximately the same between the two methods or reduce them to a small fraction of the entire compilation process, there will be no advantage to using LIBGCCJIT. The definition of C is very stable. That is not true for the JIT APIs of GCC or LLVM. We don't depend on a particular C compiler. The debugging of generated C code is easier. Finally, we can reuse existing VM declarations to create the environment.
A key to achieving the same run time is precompiled headers (PCH). This feature is present in most modern C compilers. It was created to speed up C++ compilation. Here is a graph that gives the time for different stages of JIT compilation:
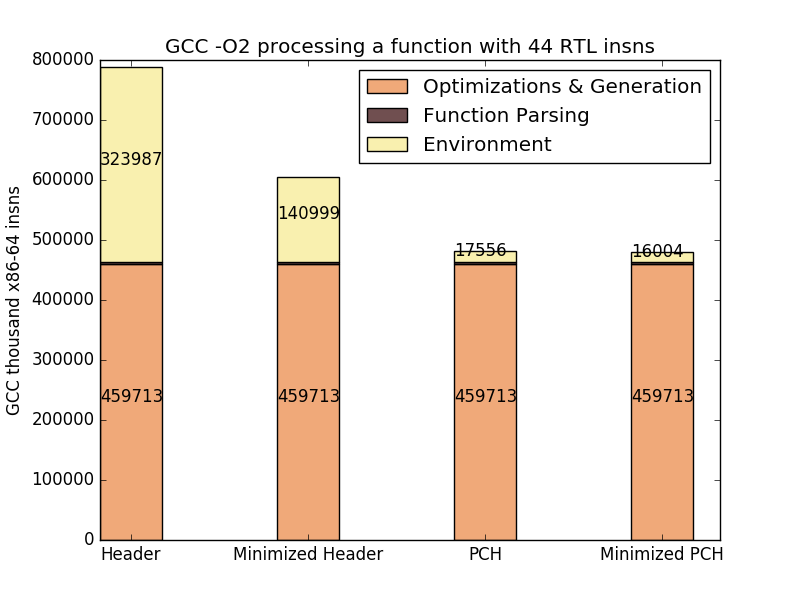
I used a typical RTL instruction sequence, about 40 instructions long. As you can see, optimizations and code generation take the biggest portion of the time. Parsing time for the generated C function which implements the RTL instruction sequence is very small. Still, parsing the environment is quite a large task even when we discard all unnecessary VM declarations. But when we use a precompiled header for the environment, its processing time drops to 3.5%. So using PCH basically speeds up JIT compilation by about 2 times compared to the native approach.
There is practically no difference in code size between LIBGCCJIT (22.6MB on x86_64) and GCC (25.1 MB).
2.3. MJIT
In my implementation of JIT for CRuby I use C code generation and precompiled headers. I call this implementation simply MJIT. M here stands for MRI (another name for CRuby) and method.
Here is a data flow chart illustrating how MJIT works:
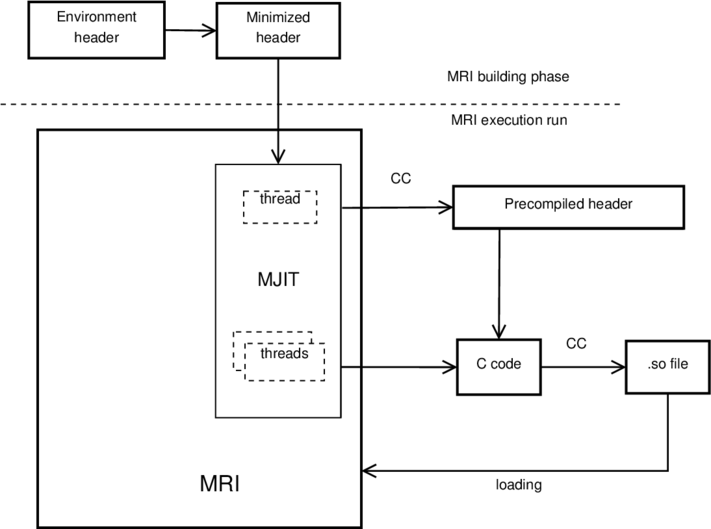
When building CRuby we create the environment from some CRuby include files and then we minimize it by removing unnecessary declarations. The result of this is a preprocessed C header file.
When CRuby starts, MJIT creates a thread to generate a PCH from the minimized header file.
When the PCH is ready, other threads in MJIT generate C files with one C function for each RTL code sequence. The files include the PCH. MJIT starts a C compiler generating dynamically loaded libraries, and loads them. When JITted code is ready, it is called instead of interpreting the corresponding RTL code. This way JIT mostly works in parallel with Ruby program interpretation and no real time delay should exist when MJIT is used.
2.3.1 Example of How MJIT Works
To better understand how JIT works with RTL, let us consider an example. The example Ruby program is just a method with a simple while loop. The method returns the value of variable i at the final iteration:
def loop
i = 0; while i < 100_000; i += 1; end;
i
end
Right after compiling this program to RTL we have the following non-speculative code:
...
0004 val2loc 3, 0
0007 goto 15
0009 plusi cont_op2, <calldata...>, 3, 3, 1
0015 btlti cont_btcmp, 9, <calldata...>, -1, 3, 100000
0022 loc_ret 3, 16
...
Here, local variable i has index 3.
The first instruction assigns zero to i.
The third instruction increments i by 1. It actually can be a method call if we redefine the integer plus operation. In this case, the method call puts the result on the stack and the next executed instruction will be cont_op2 which assigns it to i.
The fourth instruction compares i with 100,000 and, if it is smaller, jumps to the third instruction. Again, the comparison part of the instruction can be a method call. In this case, the instruction cont_btcmp will jump to the third instruction if temporary 1 (with index -1) is set to true after the call.
The last instruction returns the value of the variable i.
After executing several times, the non-speculative instructions plusi and btlti test their operands and, since the operands were always of integer type, become the speculative instructions iplusi and ibtlti respectively:
...
0004 val2loc 3, 0
0007 goto 15
0009 iplusi _, _, 3, 3, 1
0015 ibtlti _, 9, _, -1, 3, 100000
0022 loc_ret 3, 16
...
Here, underscores designate unused operands.
After the method has been called several times, MJIT generates the following C code. This is done in parallel with RTL code interpretation:
...
l4: cfp->pc = (void *) 0x5576729ccd88;
val2loc_f(cfp, &v0, 3, 0x1);
l7: cfp->pc = (void *) 0x5576729ccd98;
ruby_vm_check_ints(th); goto l15;
l9: if (iplusi_f(cfp, &v0, 3, &v0, 3, &new_insn)) {
vm_change_insn(cfp->iseq, (void *) 0x5576729ccda6,
new_insn);
goto stop_spec;
}
l15: flag = ibtlti_f(cfp, &t0, -1, &v0, 200001, &val, &new_insn);
if (val == RUBY_Qundef) {
vm_change_insn(cfp->iseq, (void *) 0x5576729ccdd6,
new_insn);
goto stop_spec;
}
if (flag) goto l9;
l22: cfp->pc = (void *) 0x5576729cce26;
loc_ret_f(th, cfp, &v0, 16, &val);
return val;
...
The code for each instruction has a label. We make sure to set the value of pc (the program counter) wherever a switch from JITted code back to code interpretation might happen.
In our example program, the speculation always works. If the speculation were wrong for the iplus and ibtlti instructions, the function vm_change_insn would be called to change the instruction into a non-speculative variant. In this case we would also switch back to code interpretation and request MJIT to generate a non-speculative version of the machine code.
After compiling with GCC we have machine code that basically looks like this:
...
movl $200001, %eax
...
ret
There is no loop. 200001 is CRuby's internal representation of the integer constant 100000.
A simple optimization based on scalar evolution analysis is responsible for eliminating the loop. Basically, scalar evolution finds a simple function describing the value of a scalar variable at each iteration.
By the way, JVM cannot do this for a large number of iterations of a loop, and neither can other widely used JITs. Unfortunately Clang cannot do this either although it has also a scalar evolution analysis. For this particular example we can make the performance speedup of MJIT as fast as we wish relative to other Ruby implementations. We just need to increase the number of iterations.
2.4. MJIT Performance Results
I've benchmarked MJIT and the following actively developed Ruby JIT implementations:
- CRuby version 2 (v2)
- CRuby 2.4 with MJIT using GCC (MJIT) and LLVM (MJIT-L)
- OMR Ruby rev. 57163 using JIT (OMR)
- JRuby9k 9.1.8 without (JRuby9K) and with -Xdynamic (JRuby9k-D)
- Graal Ruby 0.22 (Graal)
I used micro- and small benchmarks. You can find these benchmarks in the directory MJIT-benchmark in my repository on GITHUB. I ran them on an i3-7100 computer under Linux (Fedora Core 25) with GCC-6.3 and Clang-3.9. I expect it will be a typical mainstream processor for the next couple of years. To play a fair game, each benchmark runs for about 20-30 seconds without JIT. This is important for getting good results for Graal Ruby and JRuby as they have a large start up time.
I also used Optcarrot for benchmarking. It is a medium size Ruby program which emulates a Nintendo game computer. The number of generated frames for the picture processing unit (PPU) of the emulated computer defines how long the program runs. I used the default number of frames for optcarrot. Here are the results.
2.4.1. Microbenchmark Wall Time Speedup Relative to CRuby v2:
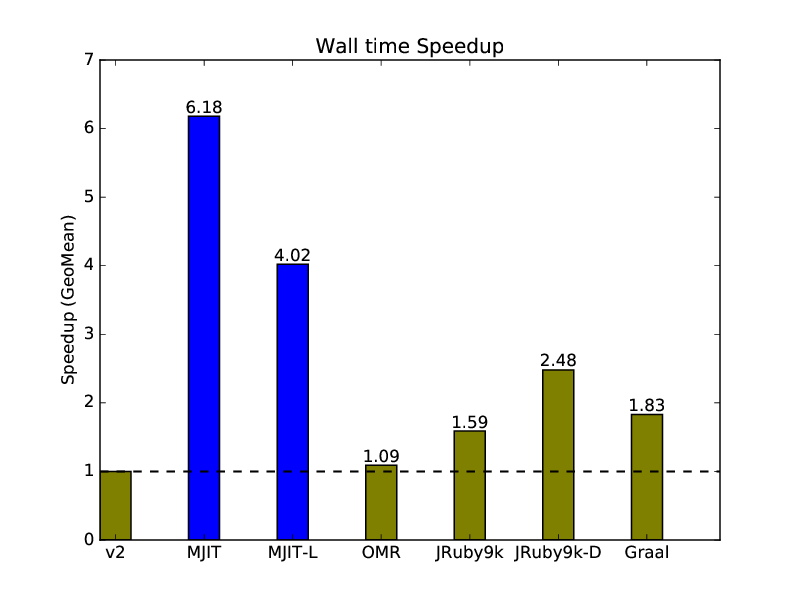
The wall time is primarily used by people for JIT performance comparison. The results are geometric means of the speedups on all benchmarks relative to CRuby version 2. As you can see, GCC works better for MJIT than LLVM.
The JVM -Xdynamic option is very profitable for JRuby. I have no idea why it is not switched on by default. Also, while analyzing individual benchmark results I got an impression that the potential of Graal optimizations is somewhere between that of the JVM client (tier 1) and JVM server (tier 2) JIT compilers.
2.4.2. Microbenchmark CPU Time Speedup Relative to CRuby v2:
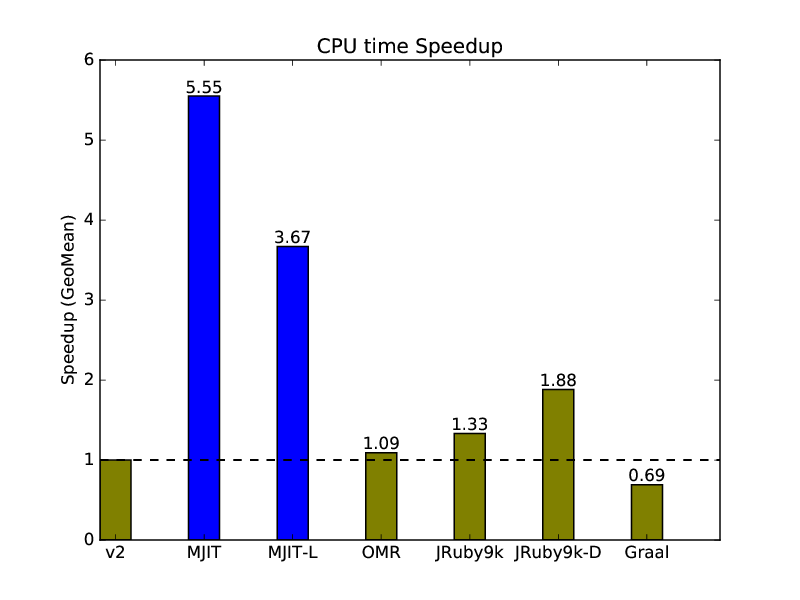
People frequently omit CPU time in JIT performance comparisons. But it is important to understand how many resources you spend to execute a program. This is important for mobile devices using battery and for cloud applications because usage of more CPU resources in the cloud is costly.
As we can see, the CPU time speed up is smaller as we spend some additional CPU resources to generate JIT code. An interesting observation is that Graal Ruby is too aggressive with JIT generation and actually spends more processor resources than the CRuby interpreter.
2.4.3. Microbenchmark Peak Memory Overhead Relative to CRuby v2:
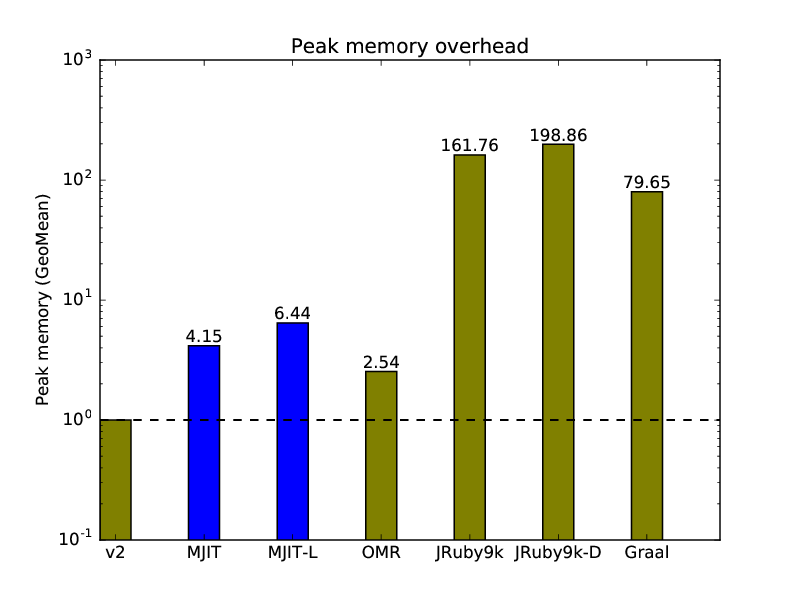
For MJIT, the microbenchmark peak memory consumption includes memory used by GCC or LLVM. Again, we need to spend additional resources to generate and store JIT code. JRuby spent too much memory. No surprise here. People have always complained that JVM uses too much memory and that running JVM applications requires beefy servers.
2.4.4. Optcarrot Frames Per Second Speedup Relative to CRuby v2:
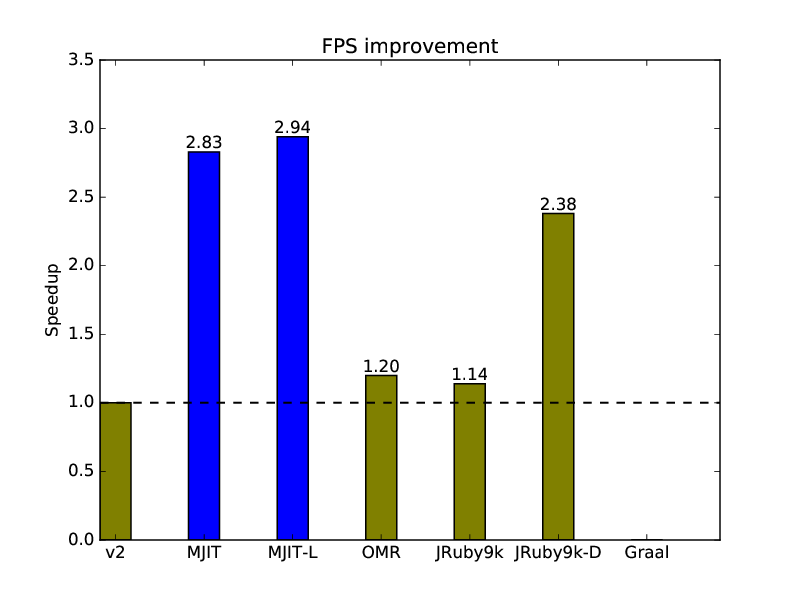
Unfortunately, I was not able to collect my own data for Graal because it crashes on Optcarrot with some kind of type conversion exception (but I can say from preliminary benchmarking of the latest version of Graal that it is 2-3 times faster on optcarrot compared to MJIT). MJIT with LLVM achieve almost 3x improvement relative to CRuby version 2. For more frames, MJIT with LLVM is more than 3 times faster. That is because MJIT has enough time on a longer benchmark to compile more RTL code.
2.4.5. OptCarrot CPU Time Speedup Relative to CRuby v2:
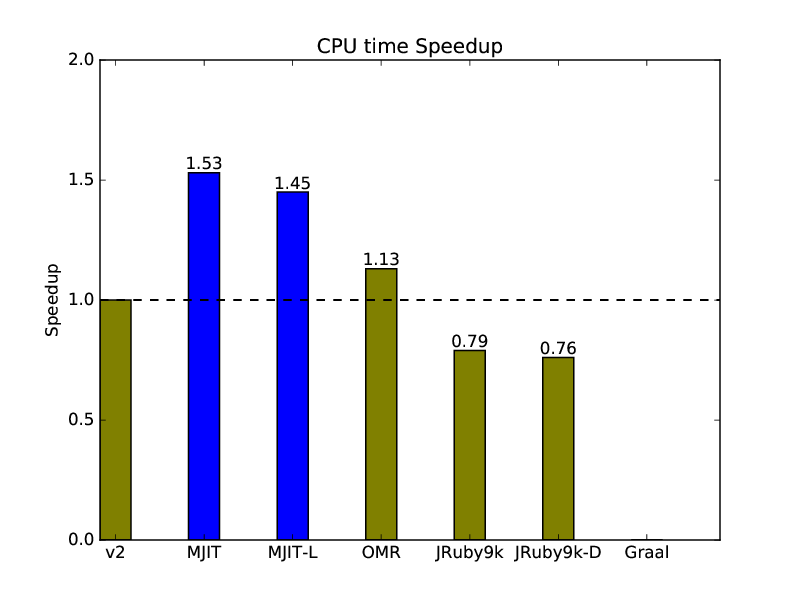
Optcarrot CPU time results are analogous to the microbenchmark ones. JRuby has the same problem as Graal. It spends more processor resources than the CRuby interpreter.
2.4.6. OptCarrot Peak Memory Overhead Relative to CRuby v2:
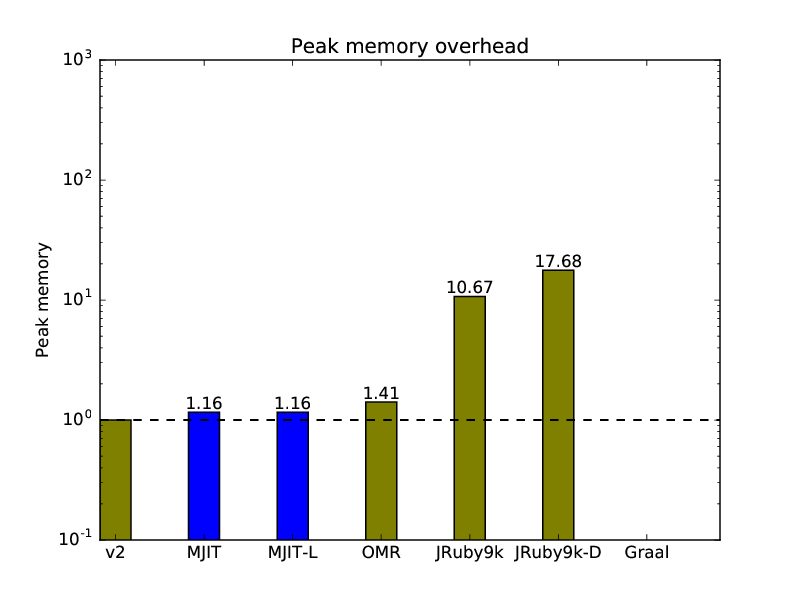
As we can see, MJIT peak memory overhead for Optcarrot is small. Optcarrot is a bigger program that uses more data. I hope that the memory overhead for Ruby on Rails will be analogous or even smaller.
2.5. My Recommendations To Use GCC/LLVM For a JIT
Here are my recommendations for how to use GCC or LLVM as a JIT for any programming language:
- Don't use MCJIT, ORC or LIBGCCJIT. It seems unorthodox and I guess the developers of these frameworks will strongly disagree with me. I believe my work demonstrates that there is no need to use complicated, unstable, and hard to debug interfaces, as they do not have significant performance advantages.
- Use precompiled headers. They greatly increase the compilation speed.
- Generate JIT code in parallel with interpretation. It is another strategy to improve the performance and to ensure there is no slowdown for any program.
- Use a file system in memory (
/tmpis usually mounted as an in-memory filesystem in Linux) for storing the precompiled headers and generated C files. - Pay attention to how code is prioritized for JITting to get good results. I found this to be quite important. Currently MJIT chooses the most frequently called code to be JITted first. There might be better approaches and investigating them could make a good topic for a research project.
2.6. MJIT Status and Future Directions
I wish I could say that Ruby on Rails works with MJIT. Unfortunately, it is far from that point. The development of MJIT with RTL is in its very early stages. The code is still unstable. Currently it passes only the CRuby bootstrap tests.
As I wrote earlier, I will also need to implement RTL generation from stack instructions instead of generating from AST.
So I believe I need at least one more year to make the code stable and more useful.
This time is also needed to implement inlining of Ruby methods written in Ruby or in C in MJIT. Basically, this can be done on the AST or RTL level or with C compiler inlining. What approach is the best for implementing inlining is a topic that deserves a separate blog post.
Takashi Kokubun proposed to implement a version of MJIT working directly with the stack instructions. This project is going well and has a good opportunity to be adopted by CRuby first. It will be a good step in the right direction. Still, I think RTL enable better JIT performance results in the long run and will create a solid base for developing new optimizations in CRuby.
I don't know what parts of my project will eventually be in the CRuby repository and when. I would be glad even if some ideas from the project will be used in a future CRuby JIT.
To conclude my blog post, I would like to say that my goal is to create not necessarily the fastest Ruby JIT, but rather a simple one that is easy to debug and maintain (and not only for me), without introducing new dependencies for CRuby, and without license and patent issues.
Last updated: February 6, 2024