In this blog post, I’ll guide you through the most important characteristics that define a 'link' in packet-switched networks, how they can impact your application, give some examples of real world parameters and how to use NetEm to emulate them.
In every packet-switched network, you will notice characteristics that are intrinsic to them and that varies depends on the communication channels being used. Such characteristics are bandwidth, delay (including jitter), packet loss, packet corruption and reordering.
Bandwidth probably is the most known one, though still often wrongly blamed for poor online experiences. Actually, any of the characteristics above will impact the user experience, to some extent depending on how big they are.
The available bandwidth of a given path on a network with multiple hops such as the Internet is given by the smallest bandwidth available in it, pretty much like highways between two cities. If some specific hop is congested, it may affect the user experience more than his/her connection itself even if it seems small.
Delay is the sum of all delays imposed by the network. There are 4 kinds of delays on the network: transmission delay, propagation delay, processing delay, and buffer delay, and they happen on each and every hop of the network, to different levels.
Transmission delay is how much time the system needs to actually transmit a packet. Consider that a packet with 1500 bytes is output serialized, so it needs at least 12us to output it at 1GBps rate, not considering overheads, no matter how far the other endpoint is from it.
Then we have the propagation delay, which is how much time that outputted signal takes to travel to the other endpoint. On a rough example, the time delay for traveling 2km in fiber optics is close to 10us. From San Francisco to New York, ~4700km, gives ~23ms, if you had a straight fiber connecting the two cities.
Then there is processing delay, which is how much time the node in the hop needs to identify the packet that is arriving and knows where it should be sent. Some nodes may even do some other work on it, like NAT or firewalling, which is also accounted here.
Finally, there is the buffer delay. A system must have at least some level of receive and transmit buffers in order to operate at full capacity, but some have (way) more than that. If your packet arrives and there is no other packet in its buffer, you’re next in line. But there can be some in there already, and you may have to wait a bit before continuing. The usage of excessive buffers is currently not recommended as they will likely trigger the BufferBloat[6] effect.
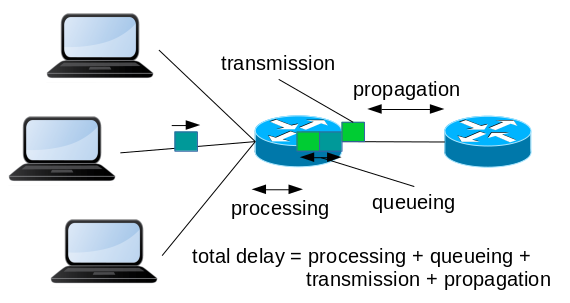
On cabled connections, the first three delay sources, transmission, propagation, and processing, are generally considered constant, especially when compared to the buffer delay. Some may call their sum as 'latency', or just 'delay'. That last one, the buffer delay, is considered as the main component of jitter. This gets more complicated when you consider Wi-Fi connections, for example, on which the transmission delay can also float, due to signal strength and/or collisions and/or interference. That is because the PHY layer protocol used on Wi-Fi will attempt to retransmit a packet up to 6 times by default, causing additional delays to that retransmitted packet and all others on queue. So regardless of the actual source, the delay is the constant part and jitter is the variable one. Usually two times the delay results in the Round Trip Time: how much time it takes to go, and go back.
Packet loss can have multiple sources, all of which causes packets to be simply lost. One very possible situation is that, when arriving on a hop, the packet had to be discarded because there was not enough space in the buffers. There is some active queue management such as RED (Random Early Drop) being used which can drop packets even before so, so it starts to signal everyone that it is reaching its limit. Packet loss can also be a result of interference, especially in wireless communication.
Packet corruption is either a result of a bad processing or some interference, which mangles some bits on a packet. Link layers such as Ethernet and Wi-Fi have built-in checks to avoid letting such corrupted packets to continue on the network, so nowadays when this happens it is more likely that the packet was badly processed.
The last characteristic is reordering. Reordering can happen, for example, when a hop decides that now it is better to send packets through another path other than the current one. If this new path has less delay, the first packets sent just after the switch are likely to arrive before the last ones sent on the old path.
Applications and the impacts of the network on them
Website
Now back to the user experience. Say you are developing a website that will be used by other employees in your company but they are based on another continent. When you test the website, it seems “fast”. When they test it, it is “slow”. Why, bandwidth? Probably not. Loading a webpage, as simple as it seems these days, is a very complex task for a browser.
Assuming DNS is already resolved, it connects to the web server and downloads the first part of the page, like the index.html file. To download this, it had to open a TCP connection, issue an HTTP request and get the reply. All this takes at least 2 RTT (Round Trip Time). Then the browser parses the HTML file and notices it has to download a CSS file. With HTTP/1.1 it can reuse that same TCP connection, and short the time to download the CSS file to at least 1 RTT.
Then, when parsing the CSS, it notices it also has to download an image, which is hosted on another server. So it opens this new TCP connection, issues the HTTP Request and downloads the image, consuming at least 2 RTTs again. So just for this, it took at least 5 RTTs. Note how we did not consider how big the files are, so bandwidth is irrelevant here. Now, if the two servers are downstairs, that is quick. But if you have an RTT of 200ms, which is common for intercontinental links, that is a whole second!
Even if you decide to put the CSS part inline, that would save only 1 RTT, and it would still be facing a page load time of 800ms.
You probably can understand now how delay has a big impact on Request/Response protocols such as HTTP.
The example above also did not consider possible packet drops, which can cause TCP to wait a bit more for getting your data through, and this waiting can also be RTT dependent.
This brings us to a known problem, called Head-of-Line blocking[7]: it is when a packet (or a request) is held waiting on the current one to complete first. For TCP, as it has to delivery data in order to the receiving application, it can happen because of packet drops or out-of-order delivery. On HTTP level, when a browser issues 2 or more requests on the same connection and the first one is considerably bigger than the others, it will block them until it completes. There are multiple ways to solve or workaround this, like with HTTP Pipelining[8] and/or by using HTTP/2, which allows interleaving of the replies.
Video streaming
Things change if you have a streaming application, such as video. Watching security cameras in real time requires at least a certain amount of bandwidth, but if the RTT is 10ms or 1s, you may not even notice.
Video streaming such as Netflix or Youtube uses a protocol called DASH[5], which builds on top of HTTP. DASH downloads the video in chunks and does buffering to some level, enough to give you time to download the next chunk at least. By this time, it will decide if it should download it from a higher or lower quality stream, considering the amount of buffer left and how long it thinks it will take to download the next ones. So delay and jitter affects the experience by very little but packet drops or corruptions may cause a chunk to take longer than expected to download, leading to degradation.
Interactive content, such as VoIP and gaming
For VoIP, if the delay gets on any path gets above 250ms, it gets annoying because you don’t know if it’s silent because the other person is waiting for you to speak, thinking or what, so you start talking and suddenly the other person is also talking. It's recommended that it shouldn't be bigger than 150ms in any way. Jitter above 40ms will also cause degradation. VoIP applications will usually use a buffer only as large as to compensate the jitter that was detected during startup, so it keeps as real time as possible, though further jitter variations bigger than it will cause pauses on the stream. Packet drops will also cause degradation but the codec used will say how tolerant it will be to some drops.
Online gaming. Depends on which kind of game it is. If it is online chess you’re probably just fine anyway, minding the web page itself. For first person shooters, you want to have the lowest delay as possible, preferably with a low jitter too.
Can I emulate this on a lab?
To that purpose, Linux has the tc queue discipline 'netem' for quite some time now. Netem is capable of emulating all the characteristics above and can be used even with veth tunnels between net namespaces, so testing can be very handy. Its manpage is very detailed and contains command examples on how to use them. There is also a good tutorial on the command line parameters at Linux Foundation website[1], to the point that it’s not worth duplicating it here.
But which values should I use??
That is something that probably was left out of the manpage on purpose. Each link has its own characteristics, leading to specific values to be used. Then you have the multiple hops, which is nothing more than multiple links connected together, and you can have some pretty complex scenarios. Luckily, if this is your first time with such type of emulation, it probably means you don’t need anything fancy. You can/should start with a simple configuration and evolve it as you see fit.
Below are some values, based on my experience, for WAN links that can be used as a starting point. Once those grow insufficient for you, it’s recommended to look for scientific papers for more recommendations and/or do your own measurements. Note that you should also account for the remaining of the path, these are just for the last mile.
WAN ADSL: 6ms latency, drops ranging 0-1%, jitter 0.5ms
WAN Fiber: 2.2ms latency, 0% drops, jitter 0.1ms
Some institutions like RNP.br seems to consider:
Loss <= 0.01%: excellent
0,01% < loss <= 1%: good
1% < loss <= 3%: regular
3% < loss: bad
You can also use the information provided by AT&T here[2]. They make available the current status and some past data too[3,4]. In [2] we can see that from New York to San Francisco it actually takes 64ms, with currently 0% drops.
[1] https://wiki.linuxfoundation.org/networking/netem
[2] http://ipnetwork.bgtmo.ip.att.net/pws/network_delay.html
[3] http://ipnetwork.bgtmo.ip.att.net/pws/global_network_avgs.html
[4] http://ipnetwork.bgtmo.ip.att.net/pws/averages.html
[5] https://en.wikipedia.org/wiki/Dynamic_Adaptive_Streaming_over_HTTP
[6] https://en.wikipedia.org/wiki/Bufferbloat
[7] https://en.wikipedia.org/wiki/Head-of-line_blocking
[8] https://en.wikipedia.org/wiki/HTTP_pipelining
Whether you are new to Containers or have experience, downloading this cheat sheet can assist you when encountering tasks you haven’t done lately.
Last updated: May 31, 2024