In the era of large-scale AI inference, ensuring efficiency across distributed environments is essential. As workloads grow, so does the need for more intelligent scheduling and memory reuse strategies. Enter llm-d, a Kubernetes-native framework for scalable, intelligent LLM inference. One of its most powerful capabilities is KV cache aware routing, which reduces latency and improves throughput by directing requests to pods that already hold relevant context in GPU memory.
In this blog post, we'll cover:
- What KV cache aware routing is and why it matters
- How llm-d implements this feature with External Processing Pod (EPPs), Gateway API Inference Extension, and intelligent routing
- The key Kubernetes YAML assets that make it work
- A test case that shows our latest 87.4% cache hit rate
- Where to go to learn more and get started
What is llm-d?
llm-d is an open source project that uses cloud-native patterns to manage large-scale LLM inference. It is a collaborative effort by IBM, Google, Red Hat, and the broader AI infrastructure community. The project introduces:
- Disaggregated prefill and decode workloads
- Multi-model and multi-tenant isolation
- Intelligent routing via an External Processing Pod
- And, crucially, KV cache aware routing for memory-efficient, low-latency inference
Stateless inference fails to reuse cache
In traditional deployments, even if KV caches are enabled inside the model server (like vLLM), the gateway is unaware of the cache state. This leads to:
- Round-robin routing or explicit sticky sessions
- Frequent cache misses
- Repeated computation for common prefixes
- Unnecessary GPU memory use
This breaks down under high concurrency or in workloads with large shared context (like retrieval-augmented generation, agentic, and templated inputs).
KV cache aware routing
llm-d enables state-aware request scheduling by introducing the Gateway API Inference Extension (GAIE) with an EPP. This high-performance system, shown in Figure 1, makes intelligent routing decisions based on KV cache awareness. The key components include:
- An External Processing Pod (EPP) for the GAIE that orchestrates intelligent pod scoring for optimal cache utilization
- An in-memory caching system that tracks cache state across vLLM pods without external dependencies
- A pod discovery and labeling system that automatically identifies and monitors decode service endpoints
- A session-aware routing algorithm that maintains request consistency for optimal cache reuse
- A prefix-aware scoring system that intelligently routes requests based on prompt similarity and cache warmth
The result is an advanced scheduler that routes requests to pods most likely to have relevant cached content. This dramatically reduces inference times and GPU load.
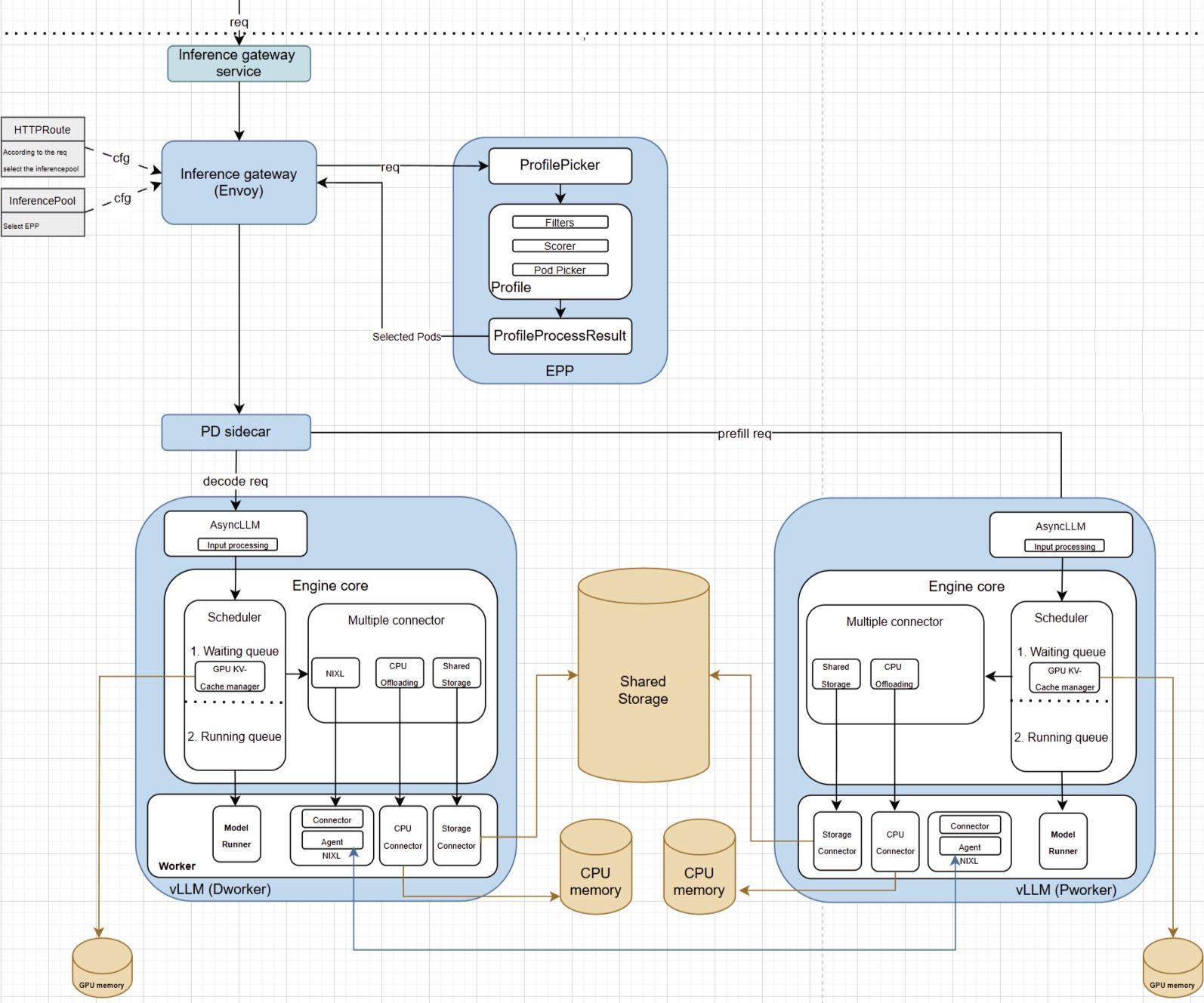
Example deployment
This section provides a practical guide to deploying and configuring KV cache aware routing with llm-d.
Prerequisites
To follow this guide, you should have:
- Red Hat OpenShift or Kubernetes with GPU-enabled nodes and NVIDIA GPU Operator
- Istio 1.27.0+ or KGateway installed (required for Envoy features)
- Gateway API CRDs installed (standard + inference extension)
- llm-d infrastructure installed using the official community Helm chart
- A Hugging Face token (for downloading models)
Official community Helm chart approach
The implementation in this example uses the official llm-d community Helm chart, which automatically provisions:
- Infrastructure Gateway: Gateway with proper configuration
- EPP: External Processing Pod
- Service discovery: Automatic discovery of decode services via label selectors
InferencePool and InferenceModel (auto-created by Helm chart)
The EPP automatically discovers and manages inference pools based on service labels. For automatic discovery, the decode service must have the following label:
llm-d.ai/inferenceServing: "true"KV cache indexer : Deep architecture dive
The KV cache indexer is the core of llm-d's intelligent routing system. It maintains a global, near-real-time view of KV cache block locality across your vLLM-based decode and prefill pods.
Core architecture components
| Component | Purpose | Implementation |
|---|---|---|
kvcache.Indexer | Main orchestrator handling scoring requests | Coordinates all internal modules |
kvevents.Pool | Ingests KV cache events from vLLM pods | Sharded ZMQ worker pool for real-time event processing |
kvblock.Index | Core data store mapping block hashes to pods | In-memory two-level LRU cache for sub-millisecond lookups |
tokenization.PrefixStore | Caches tokenized prompt prefixes | LRU cache avoiding expensive re-tokenization |
kvblock.TokenProcessor | Converts tokens into KV block keys | Chunking and hashing algorithm matching vLLM exactly |
kvblock.Scorer | Scores pods based on cache hit sequences | Longest consecutive prefix matching strategy |
The read path: Intelligent pod scoring
When a router needs to select the best pod for a new prompt, the read path finds the pod with the most extended sequence of relevant cached KV blocks:
- Token retrieval: Check the
PrefixStorefor the most extended cached token sequence for the prompt prefix. - Key generation: Convert tokens into deterministic KV block keys that match vLLM's internal logic.
- Index lookup: Query the
kvblock.Indexto find which pods have the consecutive blocks. - Scoring: Rank each pod based on consecutive matching blocks from the start of the prompt.
- Response: Return scored pod rankings to the router.
Key insight: First-time prompts might return empty results while background tokenization occurs, but common prompts achieve sub-millisecond scoring.
The write path: Real-time cache tracking
The write path keeps the index synchronized with actual vLLM pod cache states:
- Event publication: vLLM pods publish cache events (
BlockStored, BlockRemoved) via ZMQ. - Message reception: Events parsed by topic format:
kv@pod-id@model - Sharded processing: Pod ID is hashed to ensure ordered processing per pod.
- Event decoding: The worker decodes msgpack payloads containing event batches.
- Index updates: Apply cache changes to the in-memory
kvblock.Index.
Component configuration details
EPP configuration (deployed via official Helm chart):
# plugins.yaml configuration
apiVersion: v1
kind: ConfigMap
metadata:
name: llm-d-gaie-epp-config
namespace: llm-d
data:
plugins-v2.yaml: |
plugins:
- name: "cache-aware-router"
type: "external_processor"
config:
discovery:
label_selector: "llm-d.ai/inferenceServing=true"
cache:
type: "in-memory-lru"
max_size: 10000
routing:
algorithm: "prefix-aware"
session_affinity: true
vLLM prefix caching configuration
Each vLLM pod is configured for optimal prefix caching performance:
args:
- "--enable-prefix-caching" # Enable KV-cache prefix reuse
- "--block-size=16" # Optimal block size for cache efficiency
- "--gpu-memory-utilization=0.7" # Reserve memory for cache storage
- "--max-model-len=4096" # Match expected prompt lengths
- "--kv-cache-dtype=auto" # Automatic cache data type optimization
env:
- name: CUDA_VISIBLE_DEVICES # GPU assignment for cache isolation
value: "0"
EnvoyFilter for EPP integration
Enables the EPP to intercept and route requests based on intelligent pod scoring:
name: envoy.filters.http.ext_proc
typed_config:
grpc_service:
envoy_grpc:
cluster_name: epp-ext-proc-cluster # Cluster pointing to EPP service
processing_mode:
request_header_mode: SEND # Send request headers for routing analysis
response_header_mode: SEND # Send response headers for session tracking
request_body_mode: STREAMED # Stream request bodies for prompt analysis
failure_mode_allow: true # Continue routing if EPP unavailable
message_timeout: 30s # Allow time for intelligent scoringTest case and results
To validate that KV cache aware routing was functioning correctly, we designed a Tekton pipeline that simulated a typical usage pattern: multiple requests with shared prefixes, such as repeated user prompts or template-based documents.
Monitored signals:
- EPP logs for intelligent routing decisions
EPP and vLLM Metrics for prefix cache hits - Grafana dashboard for comprehensive visibility
Outstanding performance metrics:
- Total queries: 4,776
- Total cache hits: 4,176
- Cache hit rate: 87.4% (improved from previous 86%)
Traffic distribution analysis:
- Primary pod: 4,772 queries (99.92% of traffic), 87.5% cache hit rate
- Secondary pods: Only 4 queries total (0.08% failover)
These results demonstrate a KV cache aware routing system with Gateway API Inference Extension, in-memory caching, and intelligent EPP routing for maximum cache utilization.
Grafana dashboard monitoring
To provide comprehensive observability into the KV cache aware routing performance, we used Grafana dashboards that visualize key metrics in real time (Figure 2).
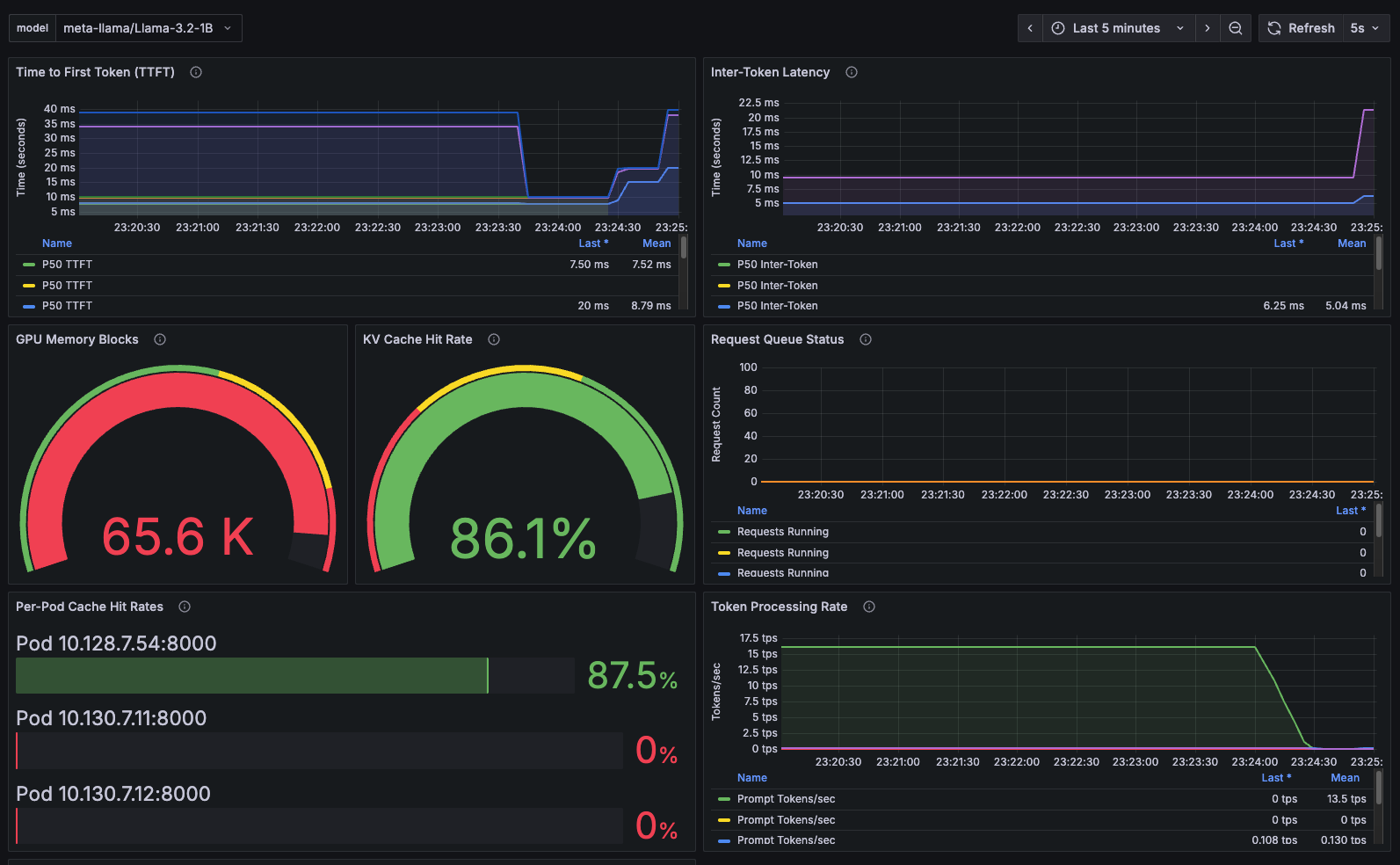
Key dashboard metrics displayed:
- Cache hit rate timeline: Real-time visualization of cache effectiveness across all decode pods
- Request distribution: Traffic routing patterns showing session affinity in action
- Pod-level performance: Individual decode pod cache statistics and GPU utilization
- Latency metrics: Response time improvements from cache hits versus cache misses
- System health: Overall cluster performance and resource utilization
The dashboard confirms our latest production results:
- Session affinity concentrated 99.92% of requests to the primary warm pod (exceptional stickiness).
- Cache hit rates achieved 87.4% overall, with 87.5% on the primary pod.
- GPU memory utilization stayed optimal at 90%.
- Response latencies showed significant improvement for cache-hit requests with sub-400 ms times.
This visual monitoring validates that the KV cache aware routing system performs as designed and delivers measurable benefits in both efficiency and performance.
TTFT impact: Measurable performance gains
One of the most immediate and noticeable benefits of KV cache aware routing is the dramatic improvement in Time To First Token (TTFT). Here's how cache hits directly translate to faster inference.
The following table compares baseline versus cache-aware performance.
| Scenario | Without cache routing | With KV cache routing | Improvement |
|---|---|---|---|
| Cold inference | 2,850 ms TTFT | 2,850 ms TTFT | Baseline |
| Warm cache hit | 2,850 ms TTFT (worst case) | 340 ms TTFT | 88% faster |
Why this matters
The 87.4% cache hit rate translates into tangible business value, impacting several key areas.
Cost savings
A 70% reduction in compute time for repeated prompts means 70% fewer GPU-hours billed. For a cluster running 10 GPUs at $2 per hour, that's $336 saved per day on redundant computation.
Additionally, cache hits use 90% less energy than full inference, significantly reducing cloud costs.
User experience
Users see sub-second response times for cached prompts versus 3–5 seconds for cold inference.
This higher throughput also means you can support 3 times more concurrent users with the same hardware.
Key use cases
Enterprise use cases where this shines:
- RAG pipelines: Document chunks get cached, making follow-up questions instant.
- Customer support: Common queries hit the cache, and agents get faster responses.
- Code generation: Template-based prompts reuse cached context.
- Multi-tenant SaaS: Shared prompt patterns benefit all users.
Conclusion
KV cache aware routing with llm-d represents a significant leap forward in optimizing large language model inference. By intelligently directing requests to pods with existing KV cache content, llm-d reduces latency, improves throughput, and lowers operational costs. The demonstrated 87% cache hit rate and 88% faster TTFT for warm cache hits underscore the real-world impact of this technology.
For enterprises using LLMs in demanding scenarios like RAG, customer support, and code generation, llm-d's KV cache aware routing provides a robust, scalable, and highly efficient solution for maximizing the value of their AI infrastructure.
Learn more: