Large language models (LLMs) use a key-value (KV) cache to store the context of ongoing text generation. However, managing the memory for this cache is challenging because its size is dynamic and unpredictable. In other words, when we run LLMs, we store something called the KV cache in memory. This helps the model remember what it has generated so far.
The KV cache is tricky, because:
- It grows and shrinks as the model generates text.
- We don’t know ahead of time how long each request will be or how long it will live.
Current LLM serving systems handle this in a very basic way:
- They store the KV cache in one big chunk of memory (contiguous memory).
- They also pre-allocate memory based on the maximum possible length of the request, not how long the request will actually be.
This article explains how PagedAttention solves the memory waste problem of traditional LLM systems by breaking the cache into small, on-demand blocks (similar to virtual memory).
Memory waste (fragmentation)
Let’s say we allow a max length of 2048 tokens.
But in reality:
User A sends 50 tokens.
User B sends 300 tokens.
User C sends 700 tokens.
Without PagedAttention, the system reserves 2048 tokens worth of memory for each user, even though they use much less. This results in significant wasted memory due to the reserved full chunk, therefore other users can’t use that free space.
Here we have found three types of memory waste:
- The first is internal fragmentation, that is we are preallocating the memory since we don’t know how much token the model will generate. So if the model is generate less token than the allocated memory then the free part of the memory is wasted.
- The second is reservation not used at the current step, but used in future.
- External fragmentation request A and request B may have different sequence length.
External fragmentation happens when KV caches require large contiguous blocks but leave behind scattered gaps, preventing efficient reuse of total GPU memory (Figure 1).

[Image source: Efficient Memory Management for Large Language Model Serving with PagedAttention]
PagedAttention
How does PagedAttention solve this problem? PagedAttention in vLLM mainly solves external fragmentation Here the large kv cache is divided into block of pages(kv blocks) and here we avoid preallocation the contiguous memory as a result the chance of memory wastage becomes less. Also here the memory need not to be allocated in contiguous fashion.
vLLM used the concept of virtual memory and paging in OS.
We virtualize the kv cache in logical and physical blocks and we will have a block table to map them (Figure 2).
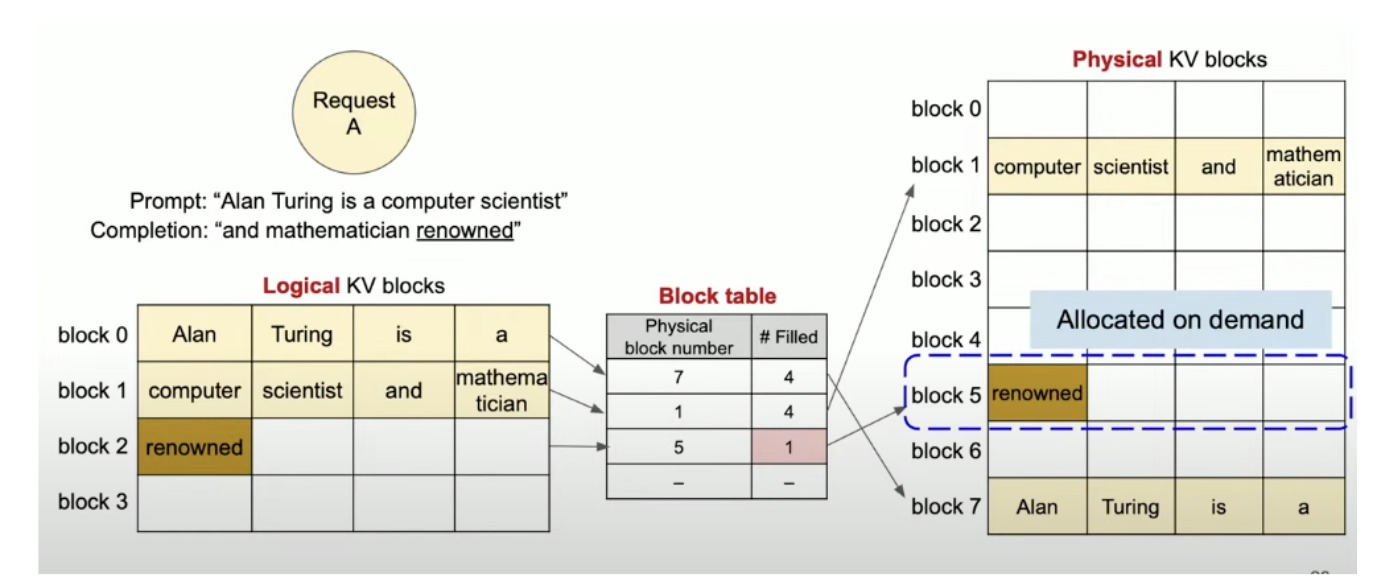
[Image source: Efficient Memory Management for Large Language Model Serving with PagedAttention]
In logical view the tokens are stored in a continuous fashion but in the physical view token are may not necessary to be stored in continuous fashion (Figure 2).
The mapping between logical and physical blocks are stored in a block table (Figure 2).
This design helps in several ways:
- Since blocks are small and added only when needed, it avoids wasting memory inside big pre-allocated chunks.
- Since all blocks are the same size, it prevents memory getting too fragmented over time.
- It lets the system share blocks between different sequences. For example, when using advanced text generation (like beam search), the model doesn't have to store the same information more than once.
Say for example the model has generated a new token renowned the new token will be first appended to the last logical block and using the block table the respective token will be stored in the physical kv blocks (Figure 2).
In short we are allocating memory on demand instead of pre-allocating a big chunk.
Here, we only have minimal internal fragmentation. There will be no external fragmentation since we will have same block size.
Final thoughts
PagedAttention is an advanced technique designed to overcome the memory inefficiencies in serving large language models (LLMs). By dividing the KV cache into fixed-size, reusable memory pages and using a lightweight indirection table for access, it enables fine-grained memory allocation and reuse. This approach significantly reduces memory fragmentation, improves GPU memory utilization, and allows for higher throughput under variable-length and concurrent workloads. For more details refer to: Efficient Memory Management for Large Language Model Serving with PagedAttention.