In a previous article, I described how to create a SaaS platform in a Kubernetes cluster. This article takes a detailed look inside the demonstration project that accompanied that earlier article. The demonstration project is the code base shared by all tenants using the SaaS platform. This article describes the structure of the demonstration application. You'll also see how to get the code up and running for multiple containerized tenants in a Kubernetes cluster, and how to expose the service to clients.
A key aspect of SaaS architecture is a generic code base used by all tenants running in the Kubernetes cluster. The application logic used by each tenant is encapsulated in a Linux container image that's declared within the definition of the tenant's Kubernetes deployment. We'll see multiple examples of this generic approach and its benefits in this article.
The Linux container for each tenant is configured by setting a standard set of environment variables to values specific to that tenant. As shown in the previous article, adding a new tenant to the SaaS platform involves nothing more than setting up a database and creating a Kubernetes Secret, deployment, service, and route resources, all of which are assigned to a Kubernetes namespace created especially for the tenant. The result is that a single code base can support any number of tenants.
Purpose of the demonstration project
The demonstration project (which you can download from GitHub) is an evolution of code that started out as a single, standalone application used by a company named Clyde's Clarinets. The company determined that its code logic was generic enough to be converted to a SaaS platform that could support a number of other instrument resellers. Thus, Clyde's Clarinets became the Instrument Resellers SaaS platform.
Note: The following 20-minute video shows you everything you need to know to get the Instrument Reseller demonstration application up and running on your local computer.
The Resellers SaaS platform enables each vendor to acquire, refurbish, and resell a type of musical instrument special to that vendor. The Instrument Resellers demonstration project supports three vendors: Clyde's Clarinets, Betty's Brass, and Sidney's Saxophones (see Figure 1.)
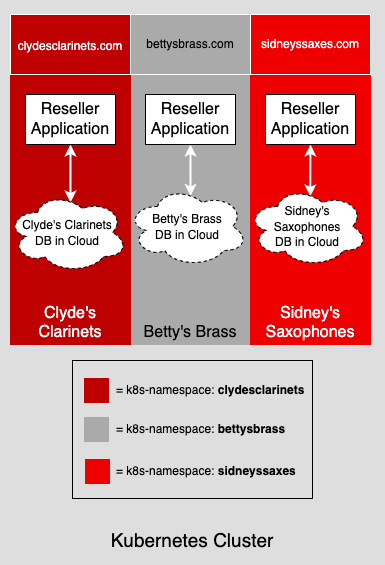
The sections that follow describe the design and code of the Instrument Reseller SaaS platform. Be advised that the demonstration code is still a work in progress. Most of the initial design work has been done and the endpoints for the GET methods to the API resources are fully functional. Also, the project ships with a data seeding feature that makes it possible for each tenant's API instance to return instrument data that is specific to the reseller. However, the workflow code that moves an instrument through its phases, from Acquisition to Refurbishment and finally to Purchase, still needs to be written. There also has to be logic for POST, PUT, and DELETE actions in the API.
Still, for the purposes of this article, the demonstration code provides a good starting place to understand how to use Kubernetes namespaces to implement a multitenant application in a single Kubernetes cluster. Once you get the code up and running in a Kubernetes cluster, you can experiment with adding the features that still need to be implemented.
Designing the Instrument Resellers SaaS Platform
The Instrument Resellers SaaS platform is written using the Node.js JavaScript framework. The code exposes a RESTful API that represents resources for acquiring, refurbishing, and reselling musical instruments. Each tenant using the SaaS platform exposes an instance of the API. For example, Sidney's Saxophones has its own instance of the API, as does Clyde's Clarinets and Betty's Brass. Figure 2 shows a user interface (UI) that exposes the GET operations in Sidney's Saxophones.

The structure of the API is generic and is described in a YAML file formatted according to the OpenAPI 3.0 specification. As mentioned previously, the purpose of the Instrument Resellers SaaS is to allow a vendor to acquire, refurbish, and resell an instrument. The API represents these generic resources as Acquisitions, Refurbishments, and Purchases. (The Purchases resource describes instruments that have been sold via resale.)
The underlying logic assumes that once an instrument is acquired it will need to be refurbished, even if it only requires a cleaning. A Refurbishment is specified with startDate and finishDate properties. Once a Refurbishment is assigned a finishDate, the associated instrument is ready for sale. Thus, the availability of an instrument for sale is determined through implication: if it has a finishDate value, it can be sold. Once an instrument is sold, it becomes a Purchase resource.
There is a good argument to be made that instead of relying upon inference to determine that a Refurbishment is ready for sale, the developer experience would be improved through a more explicit approach, such as moving the instrument into a RESTful resource named Inventory. Making such a change would not degrade the generic status of the API, and creating an Inventory resource would not corrupt the intention of the SaaS, because all resellers—whether they're reselling clarinets, drums, or guitars—could support an Inventory resource. However, the internal logic in the source code for the SaaS would need to be altered to create an Inventory resource once a Refurbishment is assigned a finishDate.
Again, making such changes would be OK because the change is generic. The important thing to remember is that keeping the API generic is essential to the design of the SaaS. Were the API to become too explicit, it would become brittle and lose its value for a SaaS platform.
Defining a versatile data schema
The need for a generic approach also holds true when designing the various data schemas used in the SaaS. Figure 3 shows the schemas used by the Instrument Resellers SaaS Platform.
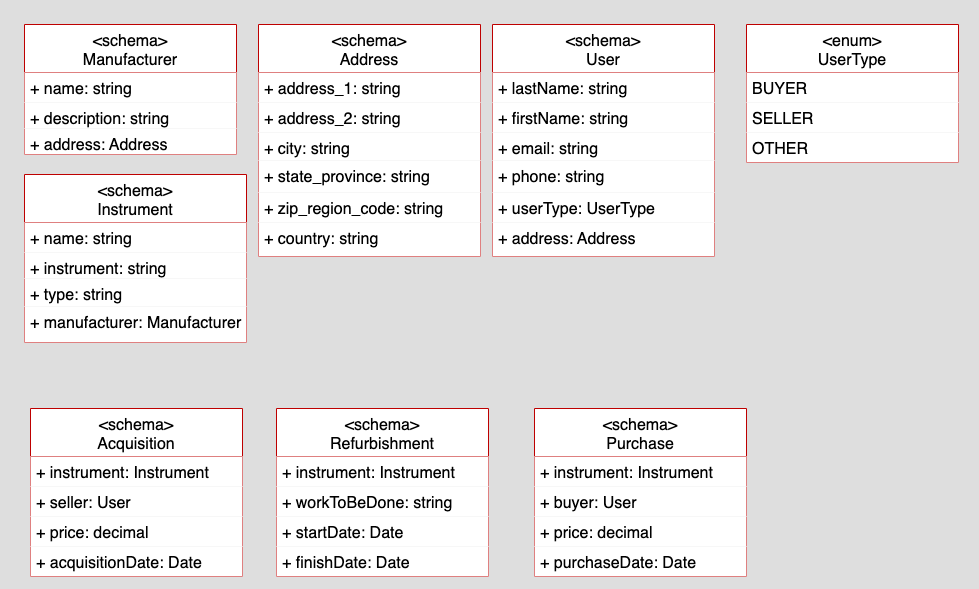
The important thing to note about the data schemas is that the data types are generic. Along with scalar types such as string and decimal, there are complex types for Manufacturer, Address, User, Acquisition, Refurbishment, and Purchase. The complex types are designed to apply to all instrument types and locales. Thus, the Address type can be used for a location in the U.S. as well as a location in France. Also, the Instrument type uses the data type string to describe the name, instrument, and type properties.
To see how a particular tenant uses the schema, we'll retrieve the information for one clarinet offered by Clyde's Clarinets:
$ curl clydesclarinets.local/v1/instruments/62bb6dde9b6a0fb486702123The output from this command shows that the clarinet has a type of standard B flat and the name Excellent Clarinet. The instrument was manufactured by Hanson Clarinet Company. The address of Hanson Clarinet Company is displayed in JSON assigned to the address property.
{
"_id": "62bb6dde9b6a0fb486702123",
"name": "Excellent Clarinet",
"instrument": "clarinet",
"type": "standard B flat",
"manufacturer": {
"name": "Hanson Clarinet Company",
"description": "Noted for their clarinets which are made in their workshops in Marsden, West Yorkshire",
"address": {
"address_1": "Warehouse Hill",
"address_2": "Apt. 745",
"city": "Marsden",
"state_province": "West Yorkshire",
"zip_region_code": "HD7 6AB",
"country": "UK",
"_id": "62bb6dde9b6a0fb486702125",
"created": "2022-06-28T21:08:46.549Z"
},
"_id": "62bb6dde9b6a0fb486702124"
},
"__v": 0
}Using a string for the type property allows any vendor to describe an instrument with a good deal of distinction, regardless of whether the instrument is a guitar, a drum, or a saxophone.
Again, the trick with defining data structures is to keep the schemas generic. Just like the API, if a schema becomes too specific, it becomes brittle and subject to breakage.
Deploying the demonstration application
Now that you've learned about the structure of the RESTful API published by the Instrument Reseller SaaS platform as well as the data schemas used by the API, you're ready to get the demonstration code up and running.
Identifying the runtime environment
The demonstration code is intended to run on an instance of the Red Hat Enterprise Linux or Fedora operating system with MicroShift installed. MicroShift is a scaled-back version of the Red Hat OpenShift Container Platform. The reason we use MicroShift is that it offers a convenient way to deploy Kubernetes while providing the OpenShift route resource, which provides an easy way to bind a Kubernetes service to a public URL that is accessible from outside the Kubernetes cluster. This Getting Started page explains how to install MicroShift on a Red Hat operating system.
Also, the demonstration code is designed to use a MongoDB database. A later section shows some of the details of working with MongoDB.
The deployment process is facilitated by using Kubernetes manifest files. You'll examine the details of the manifest files in a moment. But first, let's cover the demonstration project's data seeding feature.
Data seeding
The demonstration application seeds itself with random data that is particular to the instrument type that each reseller supports. For example, when the reseller Clyde's Clarinets is deployed into the Kubernetes cluster, the deployment seeds that reseller with data about acquiring, refurbishing, and reselling clarinets. The Sidney's Saxophones deployment seeds data relevant to saxophones. Betty's Brass is seeded with data relevant to brass instruments.
The purpose of data seeding is to provide a concrete way to understand multitenancy during this demo application. When you exercise the API for Clyde's Clarinets, you'll see only data relevant to Clyde's Clarinets. The same is true for Betty's Brass and Sidney's Saxophones. Seeing relevant data in a concrete manner makes it easier to understand the concept behind supporting multiple tenants in a SaaS platform.
The actual seeding process is facilitated by a Kubernetes init container that executes as part of the Kubernetes deployment. An init container is a container that runs before any other containers that are part of the Kubernetes pod. Our particular init container seeds the MongoDB database defined for the given reseller by loading the database with random data appropriate for the tenant (see Figure 4.)
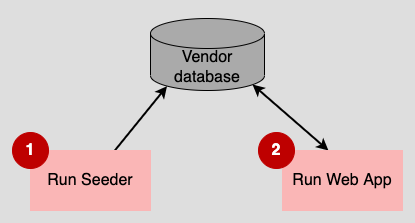
The data seeding pattern has one small risk because the init container runs for every replica in the cluster. Unless some precaution is taken, the init container will write more data to the database each time a new replica starts, even though we need to run the init container only once. So the seeder used in the demonstration project checks for the existence of seed data and refrains from adding redundant entries.
The application binds to the MongoDB server via a connection string URL. That URL can represent a MongoDB server running internally within the Kubernetes cluster or external to the cluster using a service such as MongoDB Atlas. For simplicity's sake, the demonstration code was tested using a MongoDB instance running on MongoDB Atlas. Each tenant in the SaaS platform, in this example, is bound to a MongoDB instance as part of the process of configuring the Kubernetes manifest file for the given tenant's deployment.
Getting Kubernetes manifest files
The logic that powers each tenant in the Instrument Resellers SaaS platform is encapsulated in container images that are stored on the Quay container registry. You don't need to fiddle with source code directly to get an instrument reseller up and running. But you do need to configure the containers.
Configuration operates through Kubernetes manifest files that specify properties in YAML. The configuration files for this example are stored in a GitHub source code repository.
To get the manifest files, go to a terminal window on the machine in which MicroShift is running and execute the following command:
$ git clone https://github.com/redhat-developer-demos/instrument-resellersThis command copies the source code down from the GitHub repository that hosts the demonstration project.
Once the code is cloned from GitHub, navigate into the source code directory:
$ cd instrument-resellersYou're now ready to configure the Kubernetes manifest files.
Preparing the manifest files for deployment
The manifest files that you'll use to create instrument resellers in the Kubernetes cluster are in the instrument-resellers/openshift directory. There, you'll find the manifest file that creates a tenant for each instrument reseller. The declarations for the namespace, Secret, deployment, service, and route resources for the given reseller are combined into a single YAML file for that reseller. The manifest file for Clyde's Clarinets is named clarinet.yaml, the manifest file for Betty's Brass is brass.yaml, and the file for Sidney's Saxophones is saxophone.yaml.
The essential task performed by each resource follows:
namespace: Declares the namespace that is unique for the given reseller.deployment: Configures the init container that seeds the reseller data and the regular container that has the application logic.service: Exposes the reseller on the internal Kubernetes network.route: Provides the URL to access the reseller from outside the Kubernetes cluster.secret: Specifies the URL (with embedded username and password) that defines the connection to the external MongoDB instance in which the reseller's data is stored.
The following excerpt from clarinet.yaml (which is in the GitHub repository for this demo application) shows the declaration for the Kubernetes Secret that has the URL that will connect the application code for Clyde's Clarinets to its associated MongoDB instance. Note that the stringData.url property is assigned the value <mongo-url-here>. This value is a placeholder for the URL that will be provided by the developer.
apiVersion: v1
kind: Secret
metadata:
name: mongo-url
namespace: clydesclarinets
type: Opaque
stringData:
url: <mongo-url-here>The demonstration project ships with a utility script named set_mongo_url. The script is provided as a convenience. Executing the script inserts the connection string URL in the manifest files for all the instrument resellers: Clyde's Clarinets, Betty's Brass, and Sidney's Saxophones.
Or course, the script assumes that all the resellers use the same instance of MongoDB. In a production situation, each instrument reseller might be bound to a different database. Thus, the connection URLs will differ among resellers. But in this example, for demonstration purposes, using a single MongoDB instance is fine. Both the seeder code and the API code for a given tenant know how to create their particular database within the MongoDB instance. The database name for each reseller is defined by configuring an environment variable named RESELLER_DB_NAME that is common to all resellers.
The syntax for using the set_mongo_url utility script follows. Substitute your own connection string URL for <connection_string>:
$ sh set_mongo_url <connection_string>Thus, if you want to make all the resellers in the demonstration project use the MongoDB instance defined bythe URL mongodb+srv://reseller_user:F1Tc4lO5IVAXYZz@cluster0.ooooeo.mongodb.net, execute the utility script like so:
$ sh set_mongo_url mongodb+srv://reseller_user:F1Tc4lO5IVAXYZz@cluster0.ooooeo.mongodb.netApplying the manifest files to the Kubernetes cluster
Once the MongoDB URL has been specified for all the manifest files using the utility script in the previous section, the next step is to apply the manifest file for each reseller to the Kubernetes cluster. Create an instance of each instrument reseller in the MicroShift Kubernetes cluster by executing a kubectl apply command for that instrument reseller.
Run the following command to create the Clyde's Clarinets reseller:
$ kubectl apply -f clarinet.yamlRun the following command to create the Betty's Brass reseller:
$ kubectl apply -f brass.yamlRun the following command to create the Sidney's Saxophones reseller:
$ kubectl apply -f saxophone.yamlGetting the application routes
After the three resellers have been deployed using kubectl apply, you need to get the URL through which clients can get access to each of them. OpenShift makes this task simple through the oc get routes command. Go to the Red Hat Enterprise Linux or Fedora instance that hosts the MicroShift Kubernetes cluster, and execute that command for each reseller to get its route. The HOST/PORT column in the output lists the route's URL.
To get the route to Clyde's Clarinets, execute:
$ oc get route -n clydesclarinetsYou should get output similar to:
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
instrumentreseller clydesclarinets.local instrumentreseller 8088 NoneTo get the route to Betty's Brass, execute:
$ oc get route -n bettysbrassYou should get output similar to:
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
instrumentreseller bettysbrass.local instrumentreseller 8088 NoneTo get the route to Sidney's Saxophones, execute:
$ oc get route -n sidneyssaxophonesYou should get output similar to:
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
instrumentreseller sidneyssaxophones.local instrumentreseller 8088 NoneNote that all the routes are retrieved according to the relevant Kubernetes namespace. To get the route for Clyde's Clarinets, you had to use -n clydesclarinets. To get the route for Betty's Brass, you had to specify the bettysbrass namespace. And to get the route for Sidney's Saxophones you had to specify the sidneyssaxophones namespace.
This all makes sense when you remember that tenant isolation in the Kubernetes cluster is achieved through namespaces. Access to the route for each of the instrument resellers is determined according to its particular namespace.
Binding the route's domain name to the machine host
The last thing that needs to be done to access a particular instrument reseller API within the Kubernetes cluster is to bind the domain name of each instrument reseller to the IP address of the machine on which the Kubernetes cluster is running. The domain name returned by the oc get route -n <namespace> command is automatically mapped to the associated service within the Kubernetes cluster. However, outside of the cluster, an instrument reseller's domain name is nothing more than an arbitrary string. By default, the host computer has no understanding of how to route the domain name to an IP address—the host computer's IP address, in this case.
Domain naming is not magical. Whenever a domain name is in play, that name is bound to an IP address of a web server or load balancer somewhere. The scope of the domain name can vary. If the host with that domain name is on the Web, the domain name is bound to a particular IP address by a domain registrar and propagated to all the public domain name servers across the globe.
If the scope of the domain name is limited to a local network, that domain name is bound to an IP address on the local network by making an entry in that local network's domain name server. If the scope of the domain name is limited to a single computer, that domain name is bound to that computer's IP address through an entry in the /etc/hosts file of the computer using the domain name. Because MicroShift includes a Domain Name System (DNS) server, it can find the IP address in the host's /etc/hosts file.
With regard to the demonstration project, the scope of the domain names in the URLs retrieved from the Kubernetes cluster using oc get route is local to the computer running the Kubernetes cluster. Thus, at the least, that domain name needs to be bound to the local machine by making an entry in the /etc/hosts file. The following lines in /etc/hosts bind the domain names of our three instrument resellers to a local host with an IP address of 192.168.86.32:
192.168.86.32 clydesclarinets.local
192.168.86.32 bettysbrass.local
192.168.86.32 sidneyssaxophones.localOnce /etc/hosts is updated, you can access the given instrument reseller using the cURL command on the computer hosting the Kubernetes cluster. For example, using the domain names retrieved by using oc get routes earlier, you can query the /healthcheck endpoint on each instrument reseller's API to determine whether the given instrument reseller service is up and running.
For instance, the following command performs a health check on Sidney's Saxophones:
$ curl sidneyssaxophones.local/v1/healthcheckThe call to the API endpoint should produce the following results:
{
"date": "2022-07-05T20:20:28.519Z",
"message": "Things are A-OK at Sidney's Saxophones"
}This command performs a health check on Clyde's Clarinets:
$ curl clydesclarinets.local/v1/healthcheckThe output is particular to the clarinet reseller:
{
"date": "2022-07-05T20:24:57.710Z",
"message": "Things are A-OK at Clyde's Clarinets"
}An interesting point to note is that a port number isn't required along with the instrument reseller's domain name to query a reseller's API. The reason for this is that the server running OpenShift has intelligence that examines the domain name associated with the HTTP request and routes the request to the relevant tenant according to the domain name. This technique is called name-based virtual hosting.
When name-based virtual hosting is in force, multiple domain names can be served from the same network port. The server reads the host property in the incoming request's HTTP header and then maps the domain name defined in the header to an internal IP address and port number within the Kubernetes cluster, according to the particular domain name.
There is another interesting point about the calls to the health check. When you look at the source code that is common to all instrument reseller tenants running in the Kubernetes cluster, you'll see that the differences in responses between Sidney's Saxophones and Clyde's Clarinets are due to differences in configuration. The code running both instrument resellers is identical.
Exercising the tenant APIs
As mentioned many times in this article, a significant benefit of a multitenant SaaS platform is that one code base can support a variety of tenants. The queries performing health checks in the previous section are a good example of this benefit. The benefit becomes even more apparent when making calls to the resource endpoints of the API for a given instrument reseller.
For example, the following command asks Sidney's Saxophones API for Purchases:
$ curl sidneyssaxophones.local/v1/purchasesThe output looks like this:
[
{
"_id": "62bb6d9215e72a14688a16ba",
"purchaseDate": "2022-05-02T12:53:46.088Z",
"created": "2022-06-28T21:07:30.044Z",
"buyer": {
"firstName": "Meghan",
"lastName": "Boyer",
"email": "Meghan_Boyer92@hotmail.com",
"phone": "758-676-6625 x849",
"userType": "BUYER",
"address": {
"address_1": "69709 Renner Plains",
"address_2": "Suite 351",
"city": "Vallejo",
"state_province": "AZ",
"zip_region_code": "38547",
"country": "USA",
"_id": "62bb6d9215e72a14688a16bc",
"created": "2022-06-28T21:07:30.044Z"
},
"_id": "62bb6d9215e72a14688a16bb",
"created": "2022-06-28T21:07:30.044Z"
},
"instrument": {
"instrument": "saxophone",
"type": "bass",
"name": "Twin Saxophone",
"manufacturer": {
"name": "Cannonball Musical Instruments",
"description": "Manufacturer of a wide range of musical instruments",
"address": {
"address_1": "625 E Sego Lily Dr.",
"address_2": "Apt. 276",
"city": "Sandy",
"state_province": "UT",
"zip_region_code": "84070",
"country": "USA",
"_id": "62bb6d9215e72a14688a16bf",
"created": "2022-06-28T21:07:30.044Z"
},
"_id": "62bb6d9215e72a14688a16be"
},
"_id": "62bb6d9215e72a14688a16bd"
},
"price": 827,
"__v": 0
},
.
.
.
]Likewise, the following command queries the Clyde's Clarinets API:
$ curl clydesclarinets-clydesclarinets.cluster.local/v1/purchasesThe output shows the Purchases for that reseller:
[
{
"_id": "62bb6dd79b6a0fb4867020a8",
"purchaseDate": "2022-05-02T19:59:04.324Z",
"created": "2022-06-28T21:08:39.301Z",
"buyer": {
"firstName": "Otha",
"lastName": "Bashirian",
"email": "Otha.Bashirian57@gmail.com",
"phone": "(863) 541-6638 x8875",
"userType": "BUYER",
"address": {
"address_1": "47888 Oren Wall",
"address_2": "Apt. 463",
"city": "Dublin",
"state_province": "FL",
"zip_region_code": "49394",
"country": "USA",
"_id": "62bb6dd79b6a0fb4867020aa",
"created": "2022-06-28T21:08:39.302Z"
},
"_id": "62bb6dd79b6a0fb4867020a9",
"created": "2022-06-28T21:08:39.302Z"
},
"instrument": {
"instrument": "clarinet",
"type": "soprano",
"name": "Ecstatic Clarinet",
"manufacturer": {
"name": "Amati-Denak",
"description": "A manufacturer of wind and percussion instruments, parts, and accessories.",
"address": {
"address_1": "Dukelská 44",
"address_2": "Apt. 117",
"city": "Kraslice",
"state_province": "Sokolov",
"zip_region_code": "358 01",
"country": "CZ",
"_id": "62bb6dd79b6a0fb4867020ad",
"created": "2022-06-28T21:08:39.302Z"
},
"_id": "62bb6dd79b6a0fb4867020ac"
},
"_id": "62bb6dd79b6a0fb4867020ab"
},
"price": 777,
"__v": 0
},
.
.
.
]The data differs by the type of instrument sold by the reseller. But when you look under the covers at the application logic, you'll see that the code used by Sidney's Saxophones and Clyde's Clarinets is identical. The queries illustrate yet another example of the beauty of a well-designed multitenant SaaS platform. One single code base supports as many tenants as the physical infrastructure can host.
Lessons regarding SaaS
The demonstration project described in the article shows that multitenant SaaS platforms offer significant benefits. First and foremost is that when designed properly, a single code base can support any number of tenants running in a SaaS platform. Instead of having to dedicate a number of developers to many different software projects, a SaaS platform requires only a single development team supporting a single code base. The cost savings and reduction in technical debt are noteworthy.
Adding a new tenant to a SaaS platform running under Kubernetes requires nothing more than identifying a data source and configuring a set of Kubernetes resources for the new tenant. Deployment can be a matter of minutes instead of hours or even days. By saving time, you will save money.
Yet, for all the benefits that a SaaS platform provides, it also creates challenges.
The first challenge is getting configuration settings right. One misconfigured URL to a database or one bad value assignment to an environment variable can incur hours of debugging time. Configuration settings always need to be correct. Hence, automation is a recommended best practice.
The second challenge concerns infrastructure considerations. Optimal performance requires that the physical infrastructure on which the code runs can support the tenant's anticipated load. This means making sure that the physical infrastructure has the CPU, storage, and network capacity to support all tenants and that the Linux containers running the application logic are configured to take advantage of the physical resources available. Achieving this diversity can be complicated when each tenant is using the same code base.
A service mesh can make the tenant more operationally resilient by implementing circuit breaking and rerouting in the Kubernetes cluster.
In conclusion, the key takeaways for making a multitenant SaaS platform work under Kubernetes and OpenShift are:
- Design code and data structures that are generic enough to support a variety of tenants.
- Make sure that the environment hosting the SaaS platform is robust and resilient enough to support the loads of all clients.