Page
Configure RHEL AI and download a foundational model

Before you can complete the rest of this learning path, you must first configure your RHEL AI account and download a model.
Prerequisites:
- RHEL AI with the bootable container image on compatible hardware. Get the RHEL AI image here.
- A Red Hat registry account on your machine. Create your Red Hat Registry account here.
- Root user access on your machine.
In this learning path, you will:
- Learn about Granite models.
- Configure your RHEL AI environment.
- Create accounts.
- Initialize InstructLab.
- Download a model.
- Verify the model download.
Benefits of Granite models for enterprises
The Granite Code model family offers a range of large language models (LLMs) with sizes from 3B to 34B parameters, making them suitable for diverse enterprise applications from complex application modernization to memory-constrained, on-device use cases. These models are open-source and licensed under the Apache 2.0 license, ensuring complete transparency in training datasets.
Optimized for enterprise software development workflows, Granite Code models excel in tasks such as code generation, bug fixing, and code explanation. Evaluation across a comprehensive set of benchmarks consistently shows that Granite Code models achieve state-of-the-art performance among open-source code LLMs. For example, the Granite-8B-Code model competes effectively with other open-source models of similar size, as demonstrated by results from the HumanEvalPack, which spans three coding tasks and six programming languages.
Granite’s versatility and open-source approach make it a powerful tool for enterprises looking to integrate advanced AI solutions while maintaining transparency and control.
This research paper offers more context: Granite Code Models: A Family of Open Foundation Models for Code Intelligence
Enterprise support, lifecycle, and indemnification
RHEL AI provides enterprises with a trusted and reliable platform, offering 24 x 7 production support to ensure smooth AI model deployment and operation. Red Hat extends its commitment to enterprise-grade solutions by offering an extended model lifecycle, ensuring that Granite models receive continuous updates, maintenance, and improvements over time. Additionally, enterprises benefit from model IP indemnification, which protects them against intellectual property risks associated with model usage. This combination of support, lifecycle management, and indemnification makes RHEL AI a dependable choice for integrating and scaling AI models in mission-critical environments.
Connect to and configure your RHEL AI environment
Let’s connect to your RHEL AI environment via SSH. Follow the steps below to authenticate and gain access to your environment.
Open your terminal and run the provided SSH command with your unique endpoint:
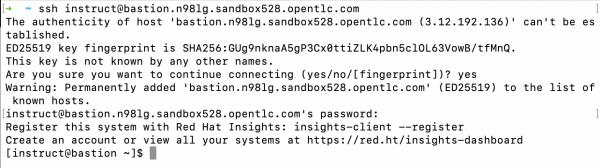
ssh <YOUR_RHEL_AI_SSH_ENDPOINT>- The first time you connect, you may receive a security warning like the following, asking you to verify the host’s authenticity. After accepting, the system will permanently add the host to your known hosts list. You’ll then be prompted to enter your password.
- Once authenticated, you’ll be successfully connected to the RHEL AI environment, and you should see a message similar to Figure 1.
-
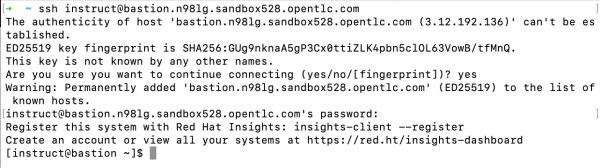
Figure 1: Connect to RHEL AI via Secure Shell Protocol (SSH). - You’re now logged in to your RHEL AI Machine. Let’s proceed to configure your RHEL AI Environment so that you can download LLMs and utilize other functionalities available on RHEL AI.
Configure your RHEL AI Environment
To download Red Hat indemnified LLMs, you’ll need to authenticate with the Red Hat container registry and then initialize InstructLab with the right config. This ensures that you have access to the foundational models provided by Red Hat. This section guides you through setting up your Red Hat account and logging in to the registry via Podman.
- Create a Red Hat account. If you don’t already have a Red Hat account, you can create one by following the procedure outlined in the Register for a Red Hat account page.
- Once your Red Hat account is set up, you’ll need a Red Hat registry account to download models.
- To create a registry account, visit the Registry Service Accounts page and select New Service Account.
- Once created, you can view your account username and password by selecting the Regenerate Token button on the webpage.
Log into the Red Hat Registry via the CLI. After creating your registry account, log into the Red Hat container registry using Podman in your terminal. Here’s how to authenticate:
[instruct@bastion ~1$ podman login -u='username' -p <key> registry.redhat.ioOnce you have authenticated, you should see a Login Succeeded! message. Now you can check the status of your Podman setup by typing:
podman infoThis will display a number of configuration settings and statuses for the Podman instance.
Optional: Configure Red Hat Lightspeed
For hybrid cloud deployments, Red Hat Lightspeed offers you visibility into your environment and can help you identify operational risks. If you wish to configure Red Hat Lightspeed, follow the procedure in Red Hat Lightspeed documentation.
To configure your system with an activation key, use the following command:
rhc connect --organization <org id> --activation-key <created key>If you prefer to opt out of Red Hat Lightspeed or are working in a disconnected environment, run the following commands:
sudo mkdir -p /etc/ilab
sudo touch /etc/ilab/insights-opt-outInitialize InstructLab
Now that we have logged into the required accounts, let’s initialize InstructLab, which is necessary to configure your environment for training and aligning large language models (LLMs).
ilab config initAs part of this process, InstructLab will also clone the taxonomy repository, which manages the skills and knowledge structure for model training. We’ll dive deeper into this in the Model Alignment section later.
Once you run the initialization command, you’ll be prompted to choose a training profile that matches your hardware setup. You will see several profile options as listed below. Enter the corresponding value for the GPUs you have on your machine. If you are on RHEL AI 1.2 or newer, your hardware may be automatically detected. Once completed, Instructlab will provide a successful message.
Now, you are ready to download the Red Hat-indemnified foundational LLMs.
Download the Instructlab foundational models
In this step, we will run the default process for downloading the basic foundational models provided as part of the Instructlab package. To do this, we will need a Hugging Face token (an open repository containing a huge amount of prebuilt LLMs) as Instructlab stores the base models there.
To obtain a Hugging Face token, head to https://huggingface.co/. If you do not already have a free account at Hugging Face, create one.
Once the account is created and you have logged on, click on the account icon at the top right of the webpage, then select Access Tokens.
Generate a new one, and copy the token text.
Note: You will need it for downloading the base foundational models.ilab model download --hf-token {add_your_token}This command will download a base version of the Granite, Mistral, and Merlinite models. Out of interest, note the file location the Models are stored in. With RHEL AI, this will be:
/var/home/instruct/.cache/instructlab/models/xxxHowever, these models are .gguf format, and the newer versions of RHEL AI support vLLM as well, so we will download a vLLM-based model. In the terminal to your RHEL AI instance type:
cd $home mkdir temp cd temp git clone https://huggingface.co/instructlab/granite-7b-lab
This gives us an additional model, based on Tensorflow files, that can be processed using vLLM.
Verify the model download
After the reference download completes, verify that the models have been downloaded successfully by running:
ilab model listThis command will list all the models currently available in your environment. You should see:
[instruct@bastion ~]$ ilab model list
+--------------------------------------+---------------------+--------+
| Model Name | Last Modified | Size |
+--------------------------------------+---------------------+--------+
| granite-7b-lab-Q4_K_M.gguf | 2025-05-12 07:17:58 | 3.8 GB |
| merlinite-7b-lab-Q4_K_M.gguf | 2025-05-12 07:18:11 | 4.1 GB |
| mistral-7b-instruct-v0.2.Q4_K_M.gguf | 2025-05-12 07:18:27 | 4.1 GB |
+--------------------------------------+---------------------+--------+In the next step, we’ll move forward with serving the model to make it available for training and alignment tasks.