Overview
We evaluate the behavior of load aware descheduler with OpenShift Virtualization on OCP 4.19. This blog explores how Load Aware Descheduler balances VM distribution using the KubeVirtRelieveAndMigrate profile based on CPU utilization and Node CPU pressure. Our data demonstrated how Descheduler could help improve overall CPU performance when nodes are suffering from CPU contentions due to imbalanced distribution.
Environment
This testing was conducted on a 3 masters + 12 workers cluster. Each node is equipped with 2 sockets x 16 cores x 2 threads = 64 CPUs, 376Gi of RAM.
Descheduler profiles & customization
Profile:
- KubeVirtRelieveAndMigrate
profileCustomizations:
- devEnableEvictionsInBackground: true
- devEnableSoftTainter: true
- devDeviationThresholds: AsymmetricLow
- devActualUtilizationProfile: PrometheusCPUCombined
This profile makes dynamic VM descheduling decisions based on both CPU utilization and PSI (Pressure Stall Information) CPU metric which quantifies the disruptions of workloads due to CPU contention, often caused by excessive overcommit. At first, Descheduler will balance workloads by evicting VMs from overutilized nodes (those exceeding the cluster average CPU utilization by 10% or more) to underutilized nodes (those below the cluster average). However, when cluster-wide CPU utilization reaches 80% threshold, Descheduler shifts from using CPU utilization to PSI CPU metrics. This allows Descheduler to make smarter decisions, moving VMs from high-pressure nodes to lower pressure ones.
Evaluation
Baseline
We deployed 130 VMIs across 6 of 12 worker nodes using Node Selectors and Zone labels. Each VM ran stress-ng init scripts that fully utilized all 4 allocated vCPUs. This created a stark imbalance: 6 nodes operated at maximum CPU capacity while the remaining 6 nodes (highlighted in magenta) sat completely idle. Upon activating the Descheduler, VMs gradually migrated from overutilized to idle nodes. The cluster quickly achieved balance, with CPU utilization converging across all nodes and standard deviation dropping from approximately 50% to just 7%.
We also observed that the cluster's average CPU utilization substantially increased following descheduler rebalancing. This counterintuitive result stemmed from the initial overcommitment of CPUs as reflected by the vCPU wait time plot above, where requested vCPU exceeded total node capacity on the active nodes. This created contention with VMs competing for limited CPU resources, degrading overall performance. By rebalancing the VM distribution, the descheduler improved overall CPU performance in this situation, reducing the average vCPU wait time from over 100% to nearly 0%.
Cluster Upgrade
For the node upgrade scenario, we simply keep the descheduler running at an interval of 60s and launch 130 VMIs without applying node selectors. The default scheduler did a reasonably good job by placing most VMs on 11 out of 12 nodes, However, only a few VMs got scheduled on to node f08-h03. Since the descheduler is running every 60s, it is continuously applying/removing soft-taints to nodes (according to their utilization) as a hint for the scheduler. it quickly classified node f08-h03 as underutilized and started moving some VMs from other nodes onto this one, helping the scheduler to converge faster in such cases.
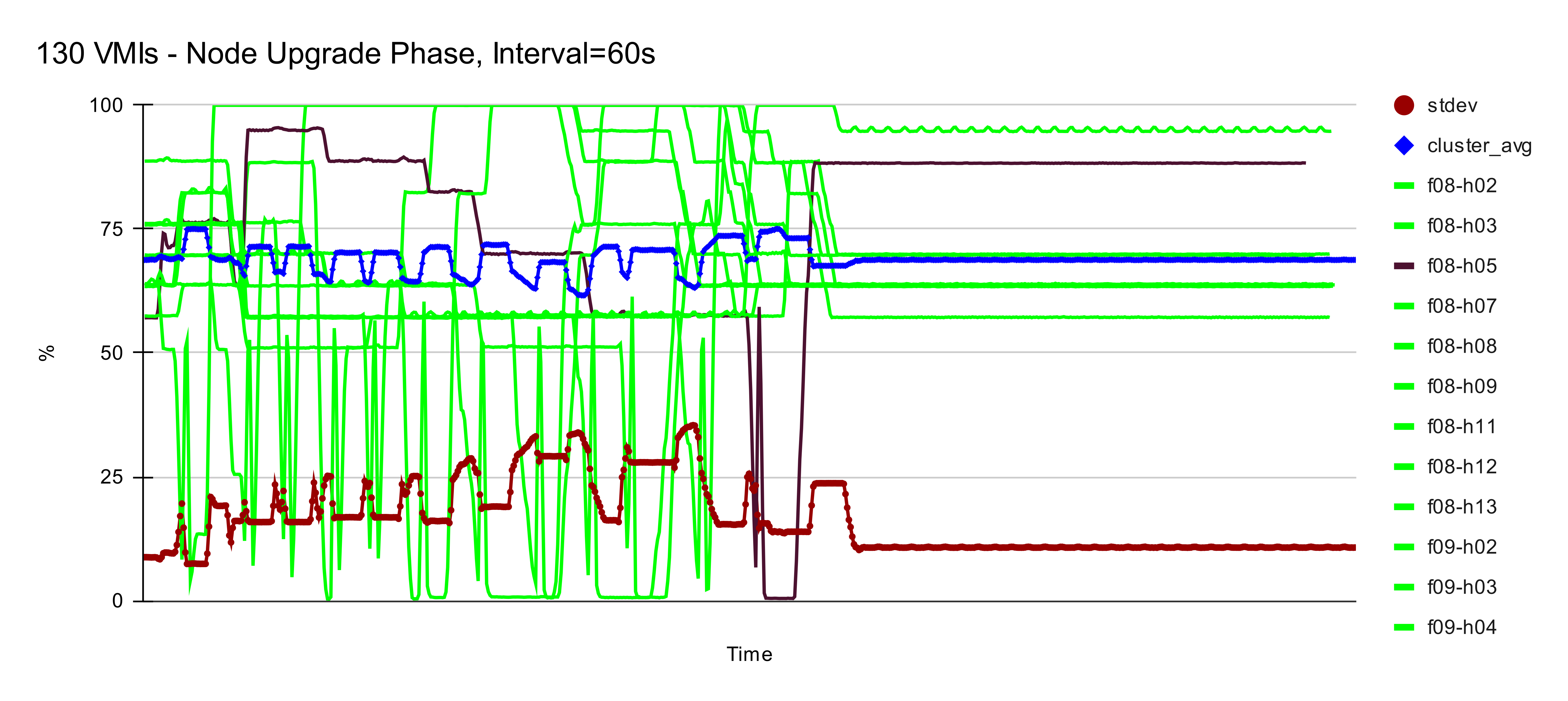
We then used the machine config that artificially simulated the node upgrade scenario to reboot each node one after another. As expected, the last node (f08-h05) got drained and eventually had some VMs moved in, achieving a balanced distribution in the end.
Node Pressure Rebalancing
When cluster average CPU utilization exceeds 80%, the Descheduler begins rebalancing nodes based on PSI pressure metrics. In our deployment of 800 VMs across 12 worker nodes, cluster-wide CPU utilization reached nearly 85%. Initially, several nodes experienced high CPU pressure due to uneven workload distribution. Once the Descheduler activated, we observed a significant improvement - nodes that had previously shown high pressure readings gradually saw their PSI values drop below the 20% threshold, Both the standard deviation and average node pressure metrics showed noticeable decline, demonstrating the ability of PSI-based scheduling for optimizing VM workload distribution.
Important Notes
CPU-based load-aware balancing is generally available in OpenShift Container Platform 4.20 through the KubeVirtRelieveAndMigrate Kube Descheduler profile, which uses Prometheus utilization signals to identify overutilized nodes and trigger VM live migration. Rebalancing is iterative rather than instantaneous; plan for operational review when corner cases limit convergence—for example, VMs with restrictive node selectors or affinity rules that leave no eligible destination node etc.
Acknowledgement
This is a collaborative effort within the OpenShift Virtualization Performance and Scale team, We address storage, network performance and scalability challenges, conducting in-depth performance analysis to ensure workloads operate efficiently at scale across the entire infrastructure stack. Special thanks to Simone Tiraboschi, Robert Krawitz, Jenifer Abrams, Shekhar Berry, Peter Lauterbach