With traditional virtualized infrastructure or Infrastructure-as-a-Service, it is common practice to regularly refresh instances back to a known good state. This provides confidence that the application workloads have the correct runtime configuration, no deltas are being introduced, and they can be relied upon to provide value for the business. In these cases, you might use tools such as Ansible or Jenkins, but when we move our application workloads to containers running on OpenShift Container Platform, we can use native tools provided by that platform to achieve the same result.
But Why Would I Do This?
Application state can still be written to ephemeral storage within a container - nothing prevents this. This anti-pattern can introduce deltas, not only between initial container states but also between multiple replicas of a Pod. Storing state in the container creates a Snowflake, which negates the benefits of immutability and scalability that they provide. Therefore, it is equally critical to have tools that draw attention to non-compliance with the Image Immutability Principle as it is to adhere to it in the first place.
In addition, having such a mechanism also brings some added benefits in terms of application architecture. It can serve to highlight whether or not:
- A container in a Pod is able to gracefully handle enforced shutdown/restart.
- Other applications and services that rely on this Pod are able to handle its absence gracefully.
- Enough replicas of this Pod are maintained to provide service continuity during redeployment.
That All Sounds Reasonable. How Do I Do It?
Helpfully, OpenShift has the concept of Jobs. Unlike a Replication Controller, a Job will run a Pod with any number of replicas through to completion. An extension of this concept is the CronJob, which is the same as a normal Job, but with the added ability to set an execution schedule. This can be done using the well-established Cron notation. It is a very powerful alternative mechanism for executing short-duration workloads or workloads that may sit idle for long periods.
With these properties in mind, a CronJob is a perfect mechanism for executing the process that wipes our slate clean. The process needs to be executed on a schedule, it'll live for a few seconds at most, and has a very specific task to carry out. But what does that actually look like in practical terms?
Several things need to happen as part of the process:
- Check for valid credentials
- Authenticate with the OpenShift API using those credentials
- Redeploy Pods
All of these tasks can be achieved within a CronJob. That doesn't sound so hard, does it?
Implementing the Clean Slate Job
Authentication
Several assumptions can be made which make the task of implementing this process relatively simple. Certificates, environment metadata, and details on the executing Service Account get injected into a Pod at runtime, allowing a process to be introspective and gain information about its environment. This information is found at location /run/secrets/kubernetes.io/serviceaccount.
[jboss@kitchensink-3-8fs58 serviceaccount]$ total 0 lrwxrwxrwx. 1 root root 13 Nov 10 10:56 ca.crt -> ..data/ca.crt lrwxrwxrwx. 1 root root 16 Nov 10 10:56 namespace -> ..data/namespace lrwxrwxrwx. 1 root root 21 Nov 10 10:56 service-ca.crt -> ..data/service-ca.crt lrwxrwxrwx. 1 root root 12 Nov 10 10:56 token -> ..data/token
The token and the ca.crt files are the most useful here. The token contains the authentication token for the Service Account being used to run the Pod, and the certificate can be used to secure communications with the OpenShift API. This information can be used within a simple script to authenticate the process with the OpenShift API:
#!/bin/bash if [ -f /run/secrets/kubernetes.io/serviceaccount/token ]; then TOKEN=`cat /run/secrets/kubernetes.io/serviceaccount/token` PROJECT=`cat /run/secrets/kubernetes.io/serviceaccount/namespace` CA=/run/secrets/kubernetes.io/serviceaccount/ca.crt else echo "No token found. Are you running on OpenShift?" fi # Make sure we're logged in if [ -n "$TOKEN" ]; then echo "Authenticating with token" oc login $KUBERNETES_SERVICE_HOST:$KUBERNETES_SERVICE_PORT --token=$TOKEN --certificate-authority=$CA fi
In addition to the files injected at runtime, the script also makes use of environment variables provided to the Pod by the platform as standard - KUBERNETES_SERVICE_HOST and KUBERNETES_SERVICE_PORT. These allow the script to identify the OpenShift API, and perform actions against it, without having to either hardcode IP addresses or DNS names into the container or otherwise perform a service lookup.
Pod Redeployment
Once authenticated, actions can then be carried out using the OpenShift API. Within the script we are executing as part of the CronJob, a pre-populated list of DeploymentConfigs can be iterated over, and a new deployment initiated:
# Iterate through DCs, and execute a rollout on them if [ -n "$DEPLOYMENT_CONFIGS" ]; then for dc in $(echo $DEPLOYMENT_CONFIGS | sed "s/,/ /g") do echo "--" echo "Wiping the slate of $dc" oc rollout latest dc/$dc -n $PROJECT echo "Done" done else echo "No DeploymentConfigs specified. Skipping execution." fi
The list of DeploymentConfigs is provided the DEPLOYMENT_CONFIGS environment variable, which turn is provided through an OpenShift ConfigMap. As nothing about the DeploymentConfig has changed, this initiates a graceful redeployment of the existing container, with the same configuration as the previous DeploymentConfig.
Job Container
Now that the content of the Job has been defined, it needs to be packaged up in a format that allows OpenShift to run it. This inevitably means the creation of a container. In order to keep this container as lightweight as possible, the RHEL Atomic Base Image can be used. The simplest way to build this container is to provide a Dockerfile that can be built and run on the OpenShift platform:
FROM registry.access.redhat.com/rhel7-atomic ... ADD scripts/clean-slate.sh /opt/app/scripts/ RUN microdnf --enablerepo=rhel-7-server-rpms \ install tar gzip --nodocs ;\ microdnf clean all ;\ curl --retry 5 -Lso /tmp/client-tools.tar.gz https://github.com/openshift/origin/releases/download/v3.6.0/openshift-origin-client-tools-v3.6.0-c4dd4cf-linux-64bit.tar.gz ;\ tar zxf /tmp/client-tools.tar.gz --strip-components=1 -C /usr/local/bin ... CMD ["/opt/app/scripts/clean-slate.sh"]
NOTE - Sections omitted for brevity.
This Dockerfile does a number of things:
- Add the script created above into the image.
- Uses Microdnf to satisfy the dependencies required to install the OpenShift Command Line Tools.
- Install the OpenShift Command Line Tools.
- Set the CMD point (the process to be run in the container) to be the script we've added to the image.
Job Definition
Now that the container has been defined, OpenShift needs to be told how to use it. This can be done using a CronJob object:
- apiVersion: batch/v2alpha1
kind: CronJob
metadata:
name: ${JOB_NAME}
labels:
job: ${JOB_NAME}
annotations:
alpha.image.policy.openshift.io/resolve-names: '*'
spec:
schedule: ${CRON_SCHEDULE}
jobTemplate:
spec:
template:
metadata:
labels:
parent: ${JOB_NAME}-parent
spec:
containers:
- name: ${JOB_NAME}
image: openshift-clean-slate:latest
env:
- name: DEPLOYMENT_CONFIGS
valueFrom:
configMapKeyRef:
name: ${JOB_NAME}-config
key: deployment.configs
restartPolicy: OnFailure
In this definition, the Job name, the Cron schedule, and the DeploymentConfigs being iterated over in the script are parameterized as part of an OpenShift Template to make consumption easier.
Service Account Configuration
The Service Account being used to execute the job must be given Edit rights on the OpenShift Project. This allows it to interact with the DeploymentConfigs, and trigger deployments as if it were a normal user of the platform. This can be done by executing the following command with the OpenShift Command Line Tools in the context of the OpenShift Project the Job needs to be executed within:
oc policy add-role-to-user edit system:serviceaccount:$(oc project -q):default -n $(oc project -q)
OpenShift Template
In order to pull this all together, an OpenShift Template can be created. This exposes a number of parameters:
- JOB_NAME - A unique identifier for the Job
- DEPLOYMENT_CONFIGS - A comma-separated list of DeploymentConfigs to target with the Job
- CRON_SCHEDULE - The standard Cron schedule to execute the Job against
When instantiated, the template presents an interface that looks like this:
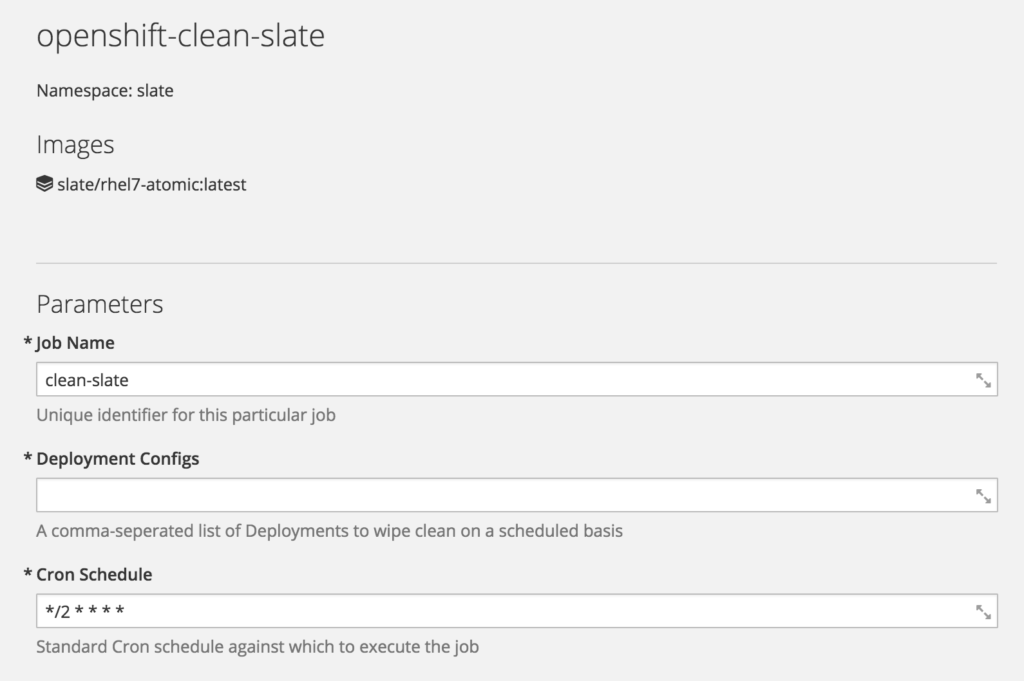
The template will create a number of objects in OpenShift:
- A BuildConfig to create the Job container.
- The CronJob object is shown above.
- An ImageStream for the builder image (RHEL Atomic).
- An ImageStream for the Job container.
- A ConfigMap containing the targeted DeploymentConfigs, so it can be altered independently between job executions. This takes the value of DEPLOYMENT_CONFIGS parameter and can be edited independently of the job.
NOTE - It is critical that the lookupPolicy for the Job container's ImageStream is set to 'true' so that the CronJob is able to reference an ImageStream. Without this (and indeed, on OpenShift Container Platform versions earlier than 3.6), a fully qualified reference to the image will need to be used. This is done as part of the template but should be noted for future reference.
End Result
So, the template has been created, the Job container has been built. What happens when the Cron schedule fires and the Job are run? Hopefully, it'll be a very quick process, and the Job's logs will need to be examined to get an idea of what's just happened. However, output similar to the following should be displayed:
Authenticating with token Logged into "https://172.30.0.1:443" as "system:serviceaccount:slate:default" using the token provided. You have one project on this server: "slate" Using project "slate". Welcome! See 'oc help' to get started. -- Wiping the slate of kitchensink deploymentconfig "kitchensink" rolled out Done
Wait. I Could Just Use Jenkins For This
Absolutely. But that's not what one would traditionally call a lightweight solution to an otherwise simple problem. Achieving the same result in Jenkins involves the integration of jobs and plugins that manage the process of redeploying your containers in OpenShift. An OpenShift Job, by comparison, is simple, repeatable, easy to scale, and uses native functionality rather than relying on a 3rd party orchestrator.
Resources
All the resources references in this blog are available on GitHub. Note that a specific tag for this content has been created, as the master branch cannot be guaranteed to be stable.
https://github.com/benemon/openshift-clean-slate/tree/blog
To learn more about Red Hat Openshift Container Platform, allowing you to provision, manage, and scale container-based applications.
Last updated: June 27, 2023