2025 was an exciting year for AI hobbyists running large language models (LLMs) on their own hardware and organizations that need on-premises and sovereign AI. These use cases require open models you can download locally from a public registry like Hugging Face. You can then run them on inference engines such as Ollama or RamaLama (for simple deployments) or production-ready inference servers such as vLLM.
As we help developers deploy these models for customer service and knowledge management (using patterns like retrieval-augmented generation) or code assistance (through agentic AI), we see a trend toward specific models for specific use cases. Let's look at which models are used most in real-world applications and how you can start using them.
Leading to 2025: The pre-DeepSeek landscape
Before DeepSeek gained popularity at the beginning of 2025, the open model ecosystem was simpler (Figure 1). Meta's Llama family of models was quite dominant, and these dense models (ranging from 7 to 405 billion parameters) were easy to deploy or customize. Mistral was also competing (certainly in the EU market), but models from Asia, such as DeepSeek (with its V3) or Qwen were not yet popular.
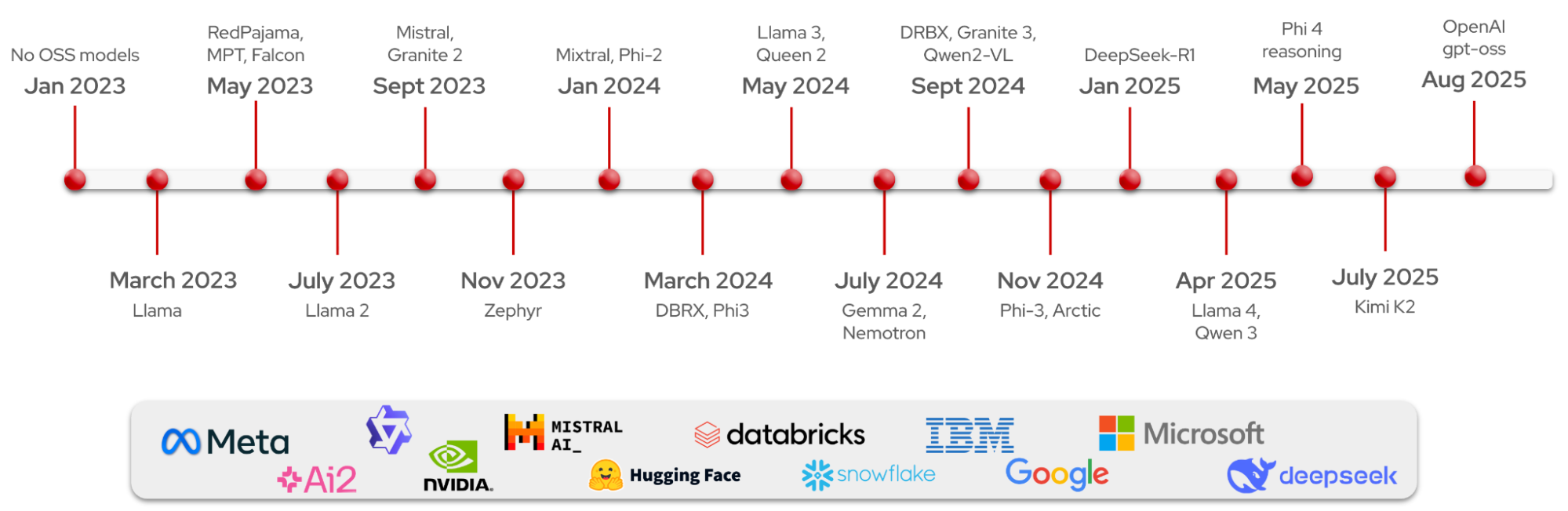
Through the stock market effect and media attention, DeepSeek's reasoning model validated that open weights can deliver high-value reasoning. It showed that open models are capable options for teams that need cost control or air-gapped deployments. In fact, many of the models I'll discuss here come from Chinese labs and lead in total downloads per region. As per The ATOM Project, total model downloads switched from USA-dominant to China-dominant during the summer of 2025.
The highest-performing open models
Benchmarks show a model's capabilities on certain predefined tasks, but you can also measure capabilities through the LMArena. This crowdsourced AI evaluation platform lets users vote for a result from two models through a "battle." Figure 2 shows what this leaderboard looks like.
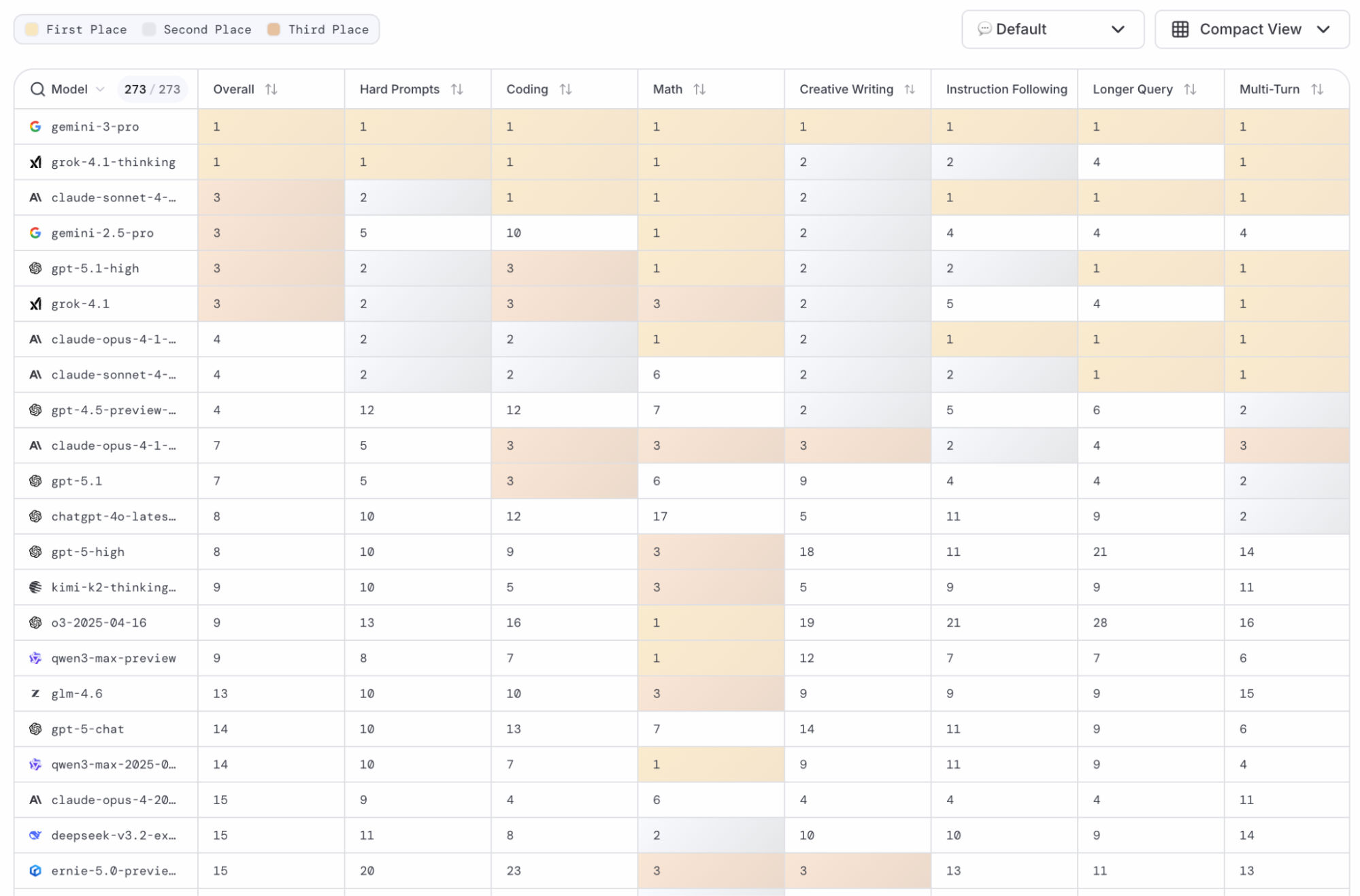
After filtering out the proprietary models such as Gemini, Claude, and ChatGPT, we're left with a few contenders. These include Kimi K2 from the Moonshot lab, Qwen3 from the Alibaba team, and of course, DeepSeek. This is quite interesting, as most folks know DeepSeek, but they might not be familiar with the others.
Qwen, Llama, and Gemma
Different AI use cases require different model sizes and capabilities, which is why open models are so useful. Instead of a general-purpose, one-size-fits-all scenario, model families such as Qwen offer various model sizes (ranging from as small as .5 B) and modalities (text or vision). The Qwen team maintains a transparent strategy for documentation and deployment instructions on GitHub and is active on X (formerly Twitter) to tease upcoming releases (Figure 4).

Llama and Gemma offer similar "families" of models, but the Qwen ecosystem has seen impressive adoption. While they might not have the highest benchmarks, their commitment to the open model community makes them one of the most used local models available. Farther down on The ATOM Project webpage shows how the Qwen family of models have become the most used through metrics of cumulative downloads as 2025 closes out.
Frontier models for RAG, agents, and AI-assisted coding
While labs like Qwen build models for specific use cases, other frontier labs are building capable models that perform like proprietary models (think ChatGPT or Gemini) at a fraction of the cost. A fair way to understand their capabilities, speed, and price is through Artificial Analysis, which incorporates evaluations (like MMLU-Pro and LiveCodeBench to compare all models, both proprietary and open (Figure 5).
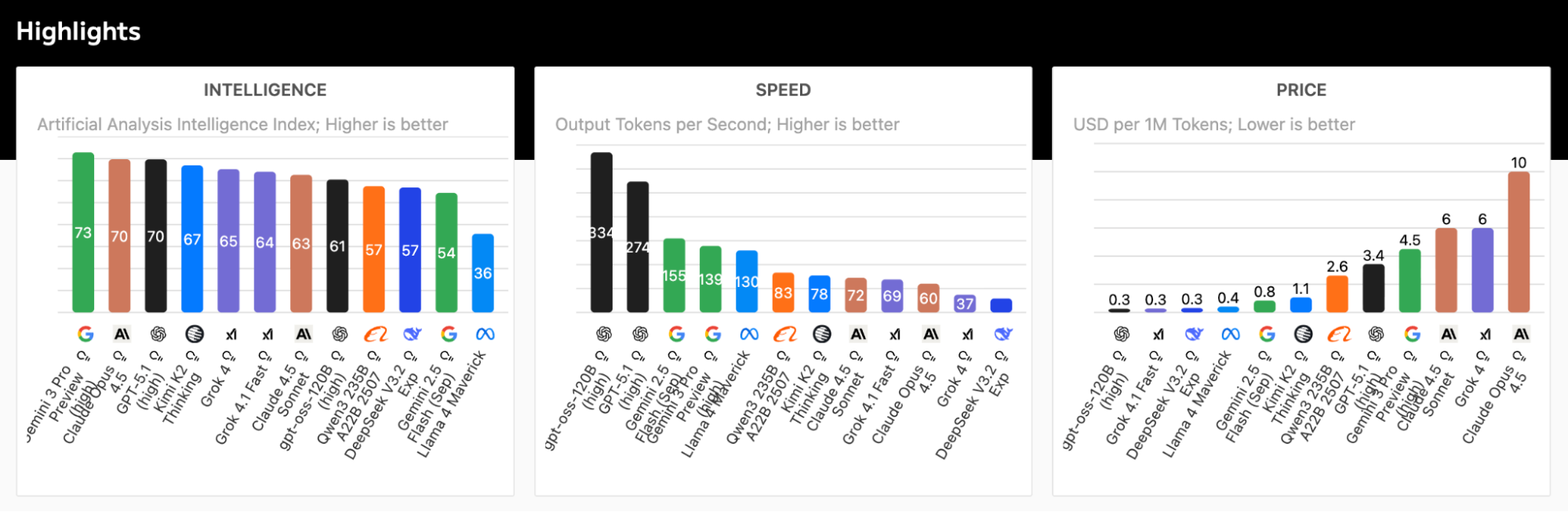
Let's look at the two with the highest intelligence score: Kimi K2 from Moonshot AI and gpt-oss from OpenAI.
Kimi: For tool calling and AI-assisted coding
Kimi K2 is one of the largest open models in terms of total parameters (about 1 trillion). It is designed with only roughly 32 billion active parameters per token to provide a smaller runtime footprint that can run on NVIDIA A100s, an H100, or even an A6000 (at 48 GB of VRAM if using 4-bit quantization). It performs quite well with agentic workflows, where you might need an AI assistant to search data, analyze trends and patterns, summarize, and generate a report. See Figure 6.
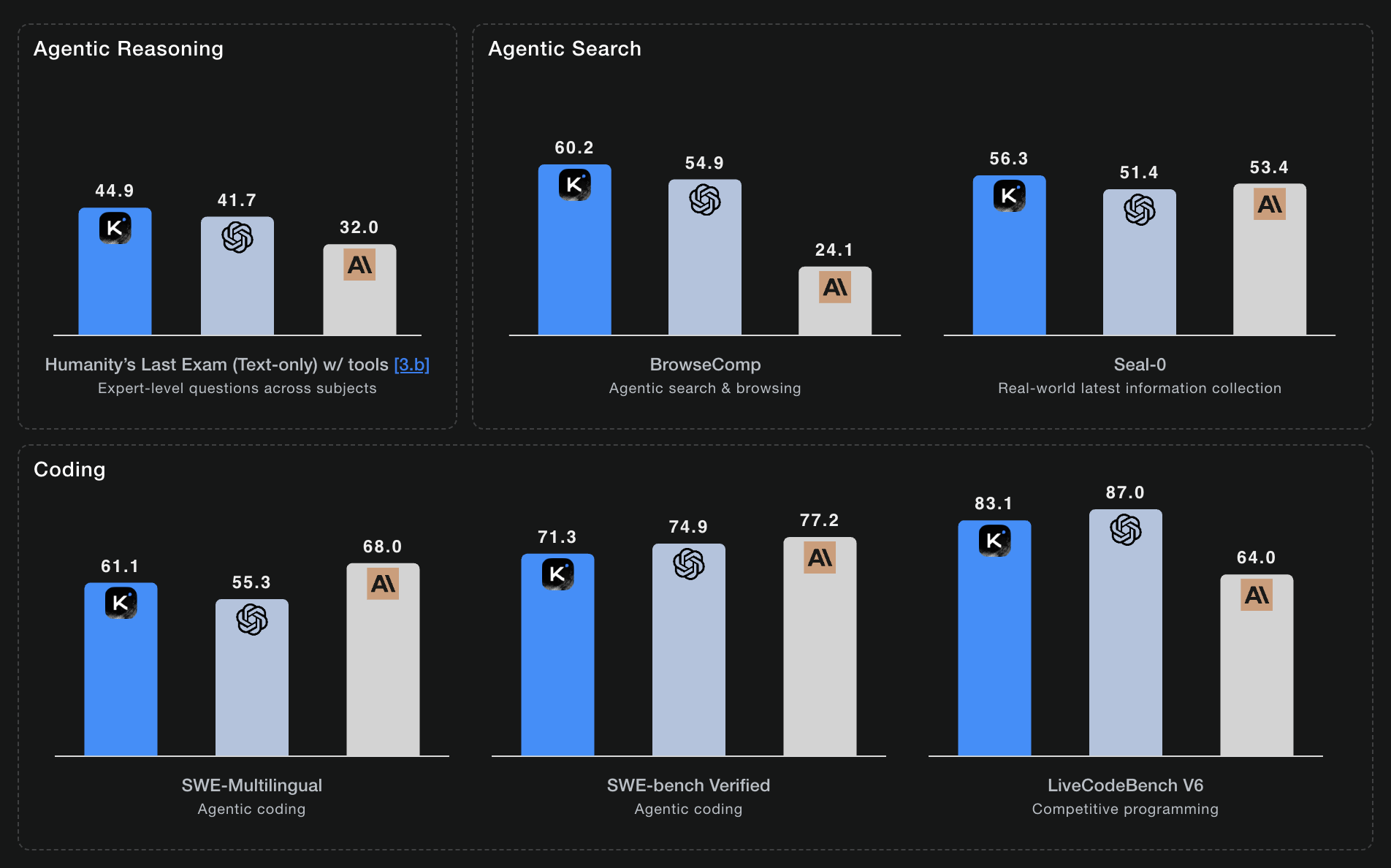
Additionally, the "thinking" variant has a context window of up to 256,000 tokens. This is helpful in "vibe" or "spec" coding where you need to generate code, tests, and integrate Model Context Protocol (MCP) servers for additional capabilities.
OpenAI's gpt-oss: A (surprise) high performing open model
Because OpenAI is the de facto brand name for AI, its release of an open model a surprise. The gpt-oss model matches the performance of slightly older ChatGPT models. After a bit of a rough launch (due to a "harmony" chat template breaking tools), this model is now known for accurate tool use. Its 120b variant fits on a single 80 GB GPU (like an H100), and the 20b version fits on consumer hardware. It also provides a solid alternative to Qwen for organizations that are still evaluating their model decisions (Figure 7).
Small models for consumer devices and the edge
Perhaps the biggest win for AI in 2025 has been the advancement of small language models (SLMs) that can run on almost any consumer device, including mobile phones. Small models are improving faster than most people realize (Figure 8). Although parameter counts might not be changing, their capabilities are increasing. This is the result of improved attention kernels, efficient block layouts, and synthetic data generation techniques that were not available two years ago.
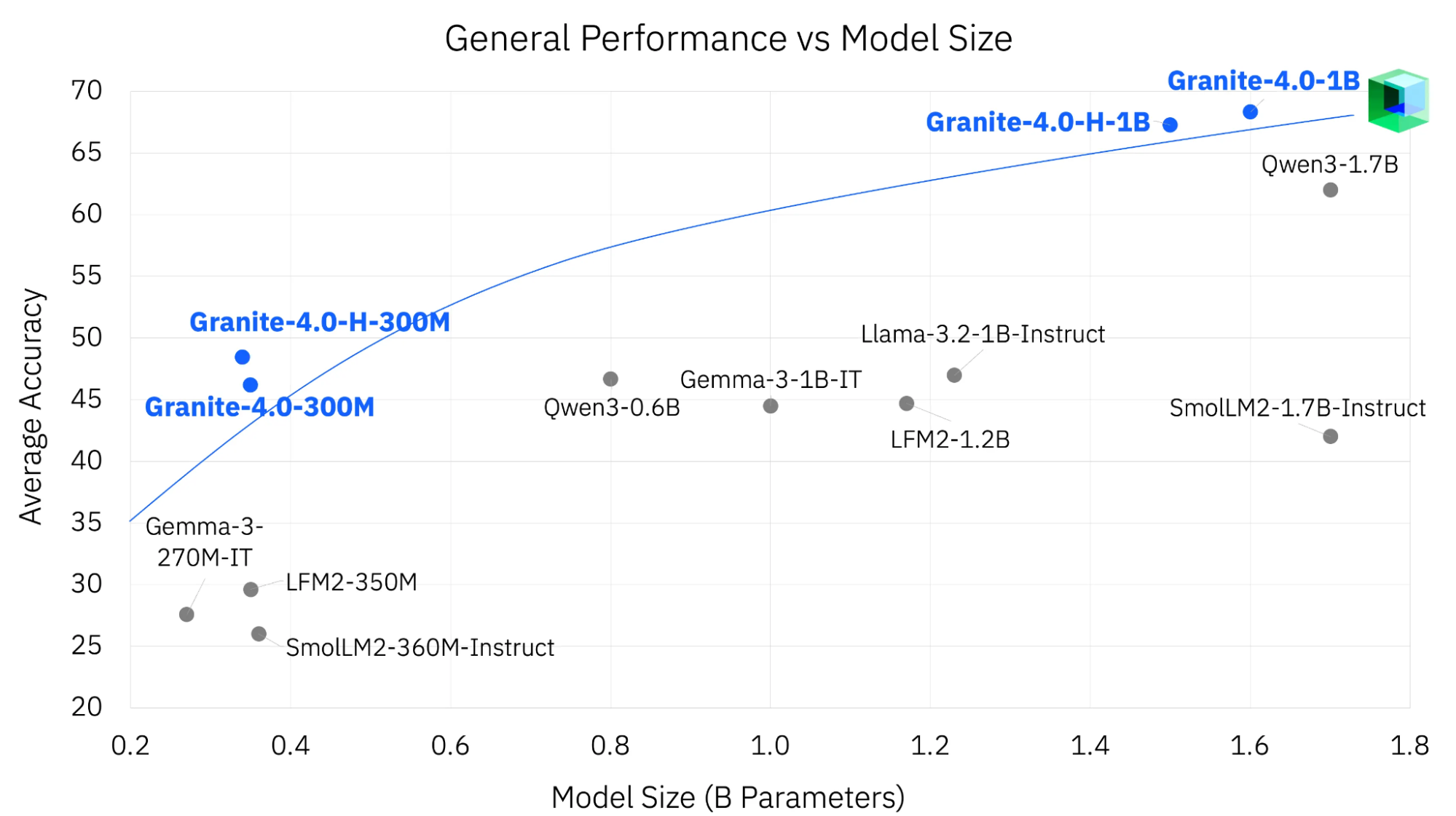
For example, the Granite 4 from IBM focused on edge and on-device deployments. It is even ISO 42001 certified for responsible development and governance. Models from Qwen, Gemma (Google), and Llama are also part of this adoption. They provide small models for developers that need air-gapped inference with predictable costs and no API key requirement.
Real-world use cases for open models
While smaller models helped the majority of people to run and experiment their own AI, open models are also used in the enterprise (Figure 9). We see this especially in highly regulated sectors (like telecommunications or banking) that have a strict requirement for on-premise deployment and data sovereignty. For example, due to data residency regulations, the usage of AI needs to stay local, so open models are a requirement.
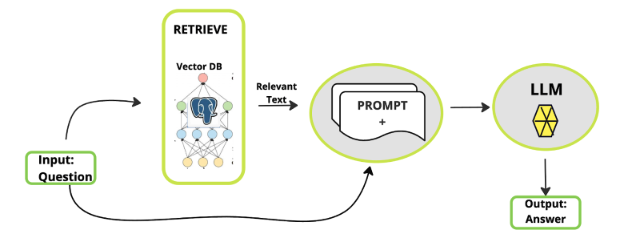
In areas ranging from customer service automation (call centers and chatbots) to internal knowledge management (legal and document processing), we see a combination of tools. Teams use data processing tools like Docling along with a "smaller" language model like Llama 4 Scout, DeepSeek R1, or Llama 3 to process and respond to requests. Retrieval-augmented generation (RAG) workflows become important here (Figure 10), as these AI pipelines typically need unstructured data for accurate responses.
How to run these models on your own hardware
You can easily test and evaluate these models. To run locally on your own device (using a GPU or even just a CPU), use Ollama and RamaLama. These command-line interface (CLI) tools can pull and run a model with a single command. These projects both use the llama.cpp inference engine but provide a simple CLI to get you started.
Beyond just chatting, you can also replace run with serve to get a OpenAI-compatible API for your applications instead of a remote endpoint.
ollama run gpt-ossIf you're using Docker or Podman for containerized applications, RamaLama is a great option. It runs models in containers for enhanced isolation and security.
ramalama run gpt-ossvLLM is suited for large-scale inference with concurrent users and repeated requests where caching is useful. A UC Berkeley project now with Red Hat as the main corporate contributor, it supports "any model, on any accelerator, on any cloud." It's also the top open source project by contributors for GitHub in 2025 (Figure 11).
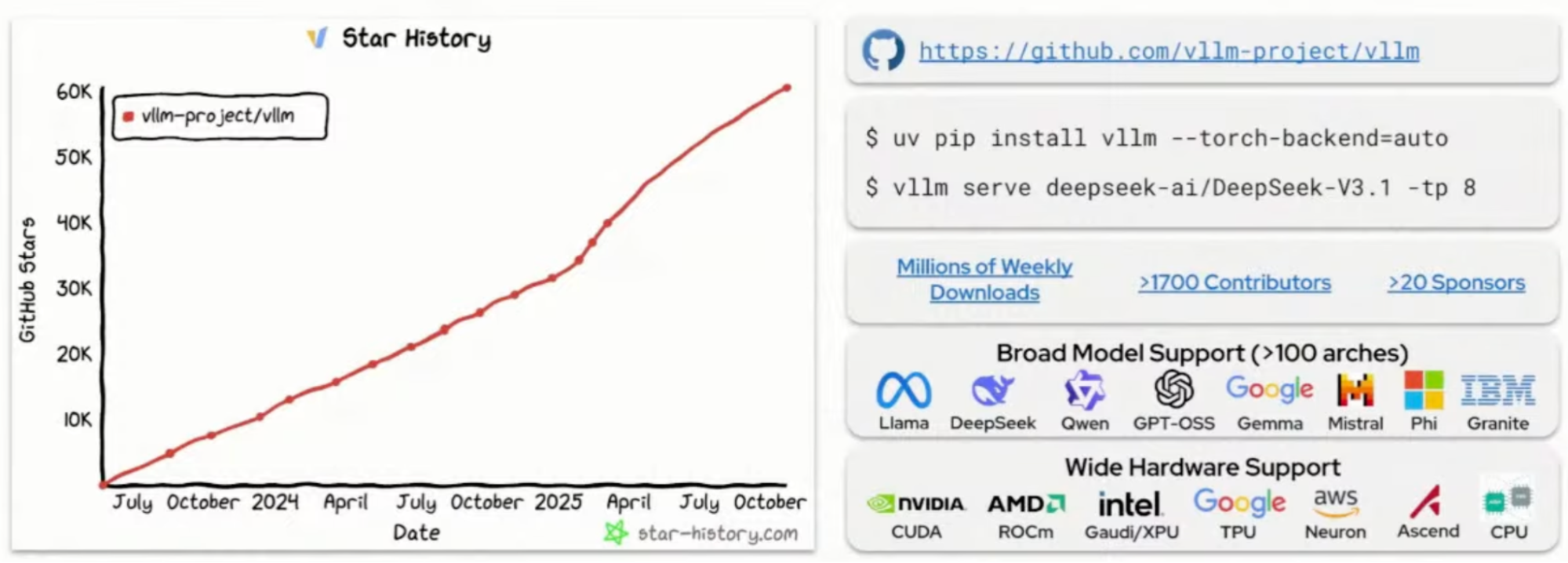
Through a full application platform like Red Hat OpenShift and OpenShift AI, your containerized applications run alongside open models. This provides the observability, guardrails, and more that are needed for enterprise AI deployments.
Wrapping up
The power of open has provided a huge ecosystem of models for right-sized use cases and inference capabilities that power everything from Raspberry Pis to distributed Kubernetes environments. You've learned about models like Qwen, DeepSeek, gpt-oss, and platforms like LMArena and Artificial Analysis that make it easy to select the right one. Now, it's time for you to test them out, see what works for you, and control your AI narrative.