A sparse summary
- Hardware-accelerated sparsity: Achieves an average of 30% lower latency and 20% higher throughput from sparsity alone on NVIDIA Hopper GPUs.
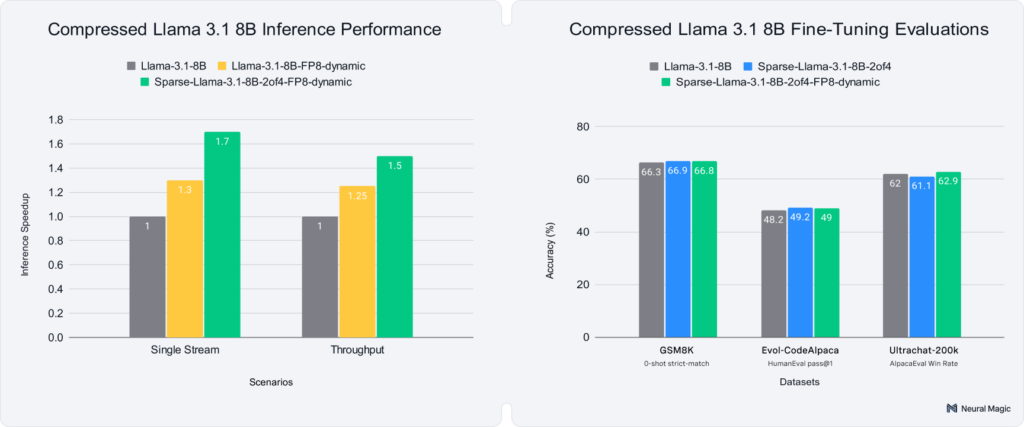
- FP8 quantization compatible: Supports NVIDIA's FP8 format with sparsity, enabling an average of 1.7X lower latency and 1.5X faster throughput.
- Open source with vLLM: Built into vLLM with custom CUTLASS-based sparse, FP8 kernels for further adoption and development.
Advancing AI efficiency is more critical than ever, and sparsity has proven to be a cornerstone in this pursuit. Building on our previous work at Neural Magic with the 2:4 Sparse Llama 3.1 8B foundation model–which increases model efficiency by eliminating unnecessary parameters while preserving accuracy–we are excited to introduce the next step forward: sparse 8-bit floating point (FP8) models and the associated high-performance kernels for vLLM.
FP8 precision, the latest hardware-supported quantization format on NVIDIA GPUs, delivers significant compute and memory reductions, comparable to 8-bit integer (INT8) formats, with 2X faster compute and 2X lower memory usage. The difference, though, is the floating-point nature provides a better representation of outliers within the model than INT8, enabling easier and more accurate quantization. By combining FP8 with the advantages of the 2:4 sparsity pattern and CUTLASS-based performance kernels in vLLM, we achieve optimal hardware utilization and state-of-the-art performance on NVIDIA's Hopper architecture. This integration unlocks new levels of efficiency with a total of 1.7X lower latency and 1.5X more queries per second for throughput with full accuracy recovery.

Cutting latency with CUTLASS
The development of high-performance FP8 sparse kernels for vLLM marks a new chapter in inference optimization, delivering state-of-the-art performance on NVIDIA Hopper GPUs. By combining FP8 precision and the 2:4 structured sparsity pattern, we created custom CUTLASS v3.6 kernels—NVIDIA’s toolkit for efficient matrix multiplication—that tackle memory bottlenecks and improve computational efficiency. FP8 cuts memory bandwidth usage by half compared to BF16, while sparsity doubles the theoretical tensor core throughput by skipping redundant computations.
Building on existing FP8 kernel implementations in vLLM, which leverage CUTLASS and the torch.float8_e4m3fn tensor type, we enabled high-performance sparse FP8 support through:
- Custom sparse FP8 CUTLASS kernels: Optimized to handle sparse FP8 weight matrices with FP8 quantized activations efficiently.
- Optimization and tuning: Fine-tuning CUTLASS parameters across scenarios to maximize inference performance.
Matrix multiplication performance benchmarks illustrate the impact of these advancements. Compared to a naive PyTorch BF16 implementation, the FP8 CUTLASS kernels alone achieve up to 1.9X speedups. These gains are further amplified when combined with the 2:4 sparsity pattern, delivering up to 30% lower latency across batch sizes. FP8 precision and sparsity unlock a total potential speedup of 2.5X over BF16 while maintaining consistent performance advantages over dense FP8 implementations, as shown in Figure 3.

Accuracy without compromise
To ensure Sparse FP8 models retain accuracy while delivering inference performance gains and easy-to-apply quantization, we employed a two-part quantization strategy: dynamic per-token FP8 for activations and static per-channel FP8 for weights. This quantization was applied post-training, following fine-tuning processes identical to those outlined in the original 2:4 Sparse Llama blog.
The fine-tuning and evaluations were conducted across the same key domains to measure accuracy recovery and robustness:
- Mathematical reasoning: Fine-tuned on GSM8K, evaluated with strict-match accuracy in a zero-shot setting.
- Coding tasks: Fine-tuned on Evol-CodeAlpaca, evaluated with pass@1 performance on HumanEval.
- Conversational AI: Fine-tuned on Ultrachat-200K, evaluated with win rate on AlpacaEval.
As summarized in Table 1, Sparse FP8 models achieve near-full accuracy recovery, comparable to earlier results observed with INT8 quantization. These findings demonstrate the robustness of FP8 quantization, ensuring maximum compression and performance gains without sacrificing accuracy.

Efficient inference at scale
To evaluate the real-world impact of sparse FP8 models, we benchmarked their performance compared to dense FP8 and dense BF16 versions. These benchmarks were generated across scenarios reflecting practical deployments to ensure consistency across various prefill vs. decode sizes, including code completion, docstring generation, instruction following, multi-turn chat, summarization, and long-context retrieval-augmented generation (RAG), as given in Table 2.

Single-Stream Latency Results
To illustrate the extreme latency side for inference, we benchmarked the various scenarios in a single-stream setup: batch size one and a single request at a time. Here, sparse FP8 models show an average 1.7X faster inference latency than dense BF16 models, with up to 30% of these gains attributed to sparsity alone, as seen in Table 3.

Multi-Stream Throughput Results
To illustrate the alternative in the performance envelope, we benchmarked the various scenarios in a throughput setup: batch size one and all requests at once. Here, sparse FP8 models show an average 1.5X increase in queries per second than dense BF16 models, with up to 20% of these gains attributed to sparsity alone, as seen in Table 4.

Multi-stream server results
To evaluate the scalability of Sparse FP8 models in real-world server deployments and ensure the throughput and latency benchmarks align, we present comprehensive results for two key use cases. These benchmarks scale queries per second (QPS) from single-stream to full-throughput conditions while measuring inter-token latency (ITL).
Figure 2, introduced earlier in the blog, showcases the performance for multi-turn chat, demonstrating consistent performance gains across a range of QPS rates.
Figure 4, below, focuses on code completion, a more decode-heavy workload, where Sparse FP8 models similarly deliver consistent performance improvements across various QPS rates.
Both figures provide two key perspectives for interpreting the results:
- Fixed ITL (Inter-Token Latency) as a Service Level Agreement (SLA): By setting a target ITL, the graphs illustrate how Sparse FP8 models increase the number of queries that can be processed concurrently while maintaining the desired performance level.
- Fixed QPS (Queries Per Second): At a specific QPS rate, the graphs demonstrate improvements in ITL, showcasing faster response times and lower latency.

Unlock efficiency
Sparse FP8 models enable exceptional performance, scalability, and cost-effectiveness on NVIDIA Hopper GPUs. By reducing memory bandwidth demands, maximizing tensor core throughput, and maintaining full accuracy recovery, sparse FP8 models enable faster, more efficient AI deployments without compromising quality.
Neural Magic is proud to continue its commitment to the open-source community, empowering developers, researchers, and enterprises to adopt and build upon these innovations. Our open source FP8 models and high-performance kernels for vLLM are designed to simplify integration and experimentation for real-world use cases.
Looking to get started in open source?
- Explore Sparse FP8 models on Hugging Face.
- Access our FP8 kernels on GitHub within vLLM.