Page
Understanding LLM workflows
We will explore the workflow involved for experimenting and improving large language models (LLMs) in this lesson.
In order to get full benefit from taking this lesson, you need:
- A basic understanding of AI/ML, generative AI, and large language models.
In this lesson, you will:
- Get an overview of the workflow involved in experimenting with LLMs.
- Go through our step-by-step guide on experimenting with LLMs using Red Hat Enterprise Linux AI (RHEL AI).
The end-to-end LLM workflow
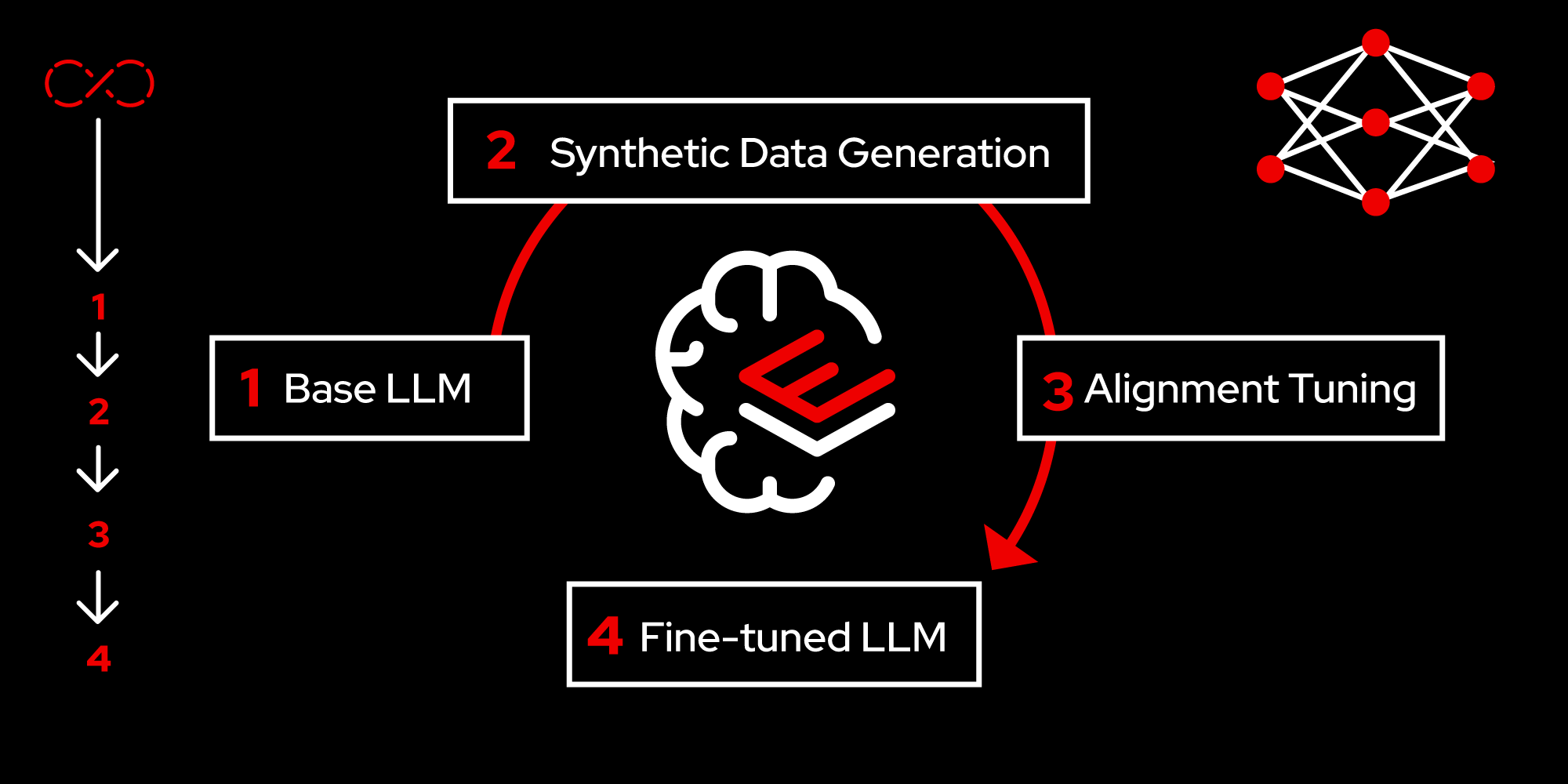
Figure 2 depicts the four phases of workflow involved in experimenting with LLMs using RHEL AI, described in the following sections.
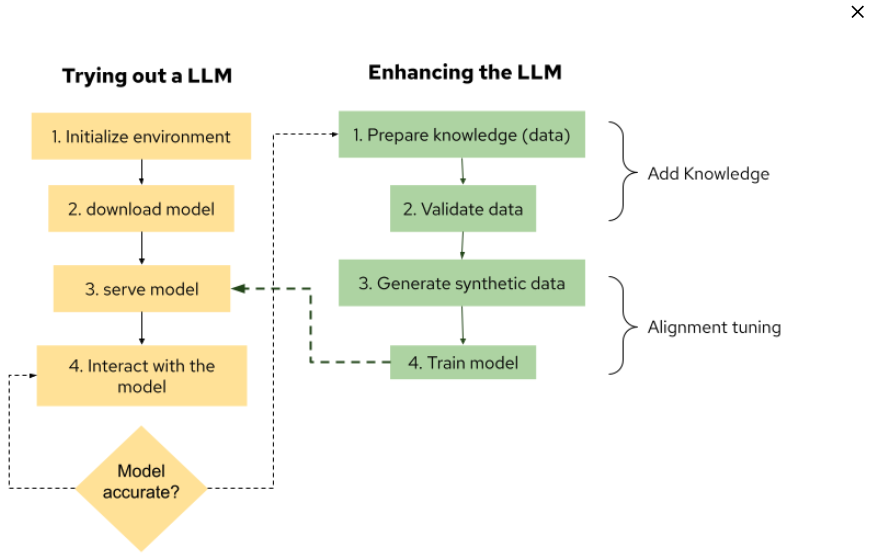
How to experiment with an LLM
The following steps will guide you through trying out an LLM from start to finish.
Step 1: Initialize the environment
Start by downloading the InstructLab CLI tool and setting up the environment which includes the configuration file and path parameters for various artifacts like taxonomy repo, model, etc.:
[instruct@instructlab ~]$ cd ~/instructlab/
[instruct@instructlab instructlab]$ source venv/bin/activate
(venv) [instruct@instructlab instructlab]$
(venv) [instruct@instructlab instructlab]$ pip3 install git+https://github.com/instructlab/instructlab.git@v0.16.1
Collecting git+https://github.com/instructlab/instructlab.git@v0.16.1
Cloning https://github.com/instructlab/instructlab.git (to revision v0.16.1) to /tmp/pip-req-build-_iawsehl
…
Successfully installed instructlab-0.16.1 numpy-1.26.4
(venv) [instruct@instructlab instructlab]$ ilab
Usage: ilab [OPTIONS] COMMAND [ARGS]...
CLI for interacting with InstructLab.
If this is your first time running InstructLab, it's best to start with
`ilab init` to create the environment.
Options:
--config PATH Path to a configuration file. [default: config.yaml]
--version Show the version and exit.
--help Show this message and exit.
Commands:
chat Run a chat using the modified model
check (Deprecated) Check that taxonomy is valid
convert Converts model to GGUF
diff Lists taxonomy files that have changed since <taxonomy-base>...
download Download the model(s) to train
generate Generates synthetic data to enhance your example data
init Initializes environment for InstructLab
list (Deprecated) Lists taxonomy files that have changed since <taxonomy-base>.
serve Start a local server
sysinfo Print system information
test Runs basic test to ensure model correctness
train Takes synthetic data generated locally with `ilab generate`...
(venv) [instruct@instructlab instructlab]$ ilab init
Found config.yaml in the current directory, do you still want to continue? [y/N]: y
Welcome to InstructLab CLI. This guide will help you to setup your environment.
Please provide the following values to initiate the environment [press Enter for defaults]:
Path to taxonomy repo [taxonomy]:
Path to your model [models/merlinite-7b-lab-Q4_K_M.gguf]:
Generating `config.yaml` in the current directory...
Initialization completed successfully, you're ready to start using `ilab`. Enjoy!
(venv) [instruct@instructlab instructlab]$ Step 2: Download the model
Next, we download the required model. With RHEL AI, users work with quantized versions of large language models. Quantized models are smaller in size and computation requirements, since model parameters get stored and processed with lower precision. For example, they use 8-bits instead of 32-bits to store the model parameters. This allows for less storage to be taken up and faster computations. While there is some loss of accuracy, users can still experiment with the model at this size, and advance to a fuller model if it suits their needs. Enter the commands below:
(venv) [instruct@instructlab instructlab]$ ilab download --repository instructlab/granite-7b-lab-GGUF --filename=granite-7b-lab-Q4_K_M.gguf
Downloading model from instructlab/granite-7b-lab-GGUF@main to models...
Downloading 'granite-7b-lab-Q4_K_M.gguf' to 'models/.huggingface/download/granite-7b-lab-Q4_K_M.gguf.6adeaad8c048b35ea54562c55e454cc32c63118a32c7b8152cf706b290611487.incomplete'
INFO 2024-07-02 19:56:17,086 file_download.py:1877 Downloading 'granite-7b-lab-Q4_K_M.gguf' to 'models/.huggingface/download/granite-7b-lab-Q4_K_M.gguf.6adeaad8c048b35ea54562c55e454cc32c63118a32c7b8152cf706b290611487.incomplete'
granite-7b-lab-Q4_K_M.gguf: 100%|███████████████████████████| 4.08G/4.08G [00:09<00:00, 438MB/s]
Download complete. Moving file to models/granite-7b-lab-Q4_K_M.gguf
INFO 2024-07-02 19:56:26,483 file_download.py:1893 Download complete. Moving file to models/granite-7b-lab-Q4_K_M.ggufStep 3: Serve the model
Serving the model with the following commands allows users to directly interact with the model:
(venv) [instruct@instructlab instructlab]$ ilab serve --model-path models/granite-7b-lab-Q4_K_M.gguf
INFO 2024-07-02 19:57:13,492 lab.py:340 Using model 'models/granite-7b-lab-Q4_K_M.gguf' with -1 gpu-layers and 4096 max context size.
INFO 2024-07-02 19:57:16,464 server.py:206 Starting server process, press CTRL+C to shutdown server...
INFO 2024-07-02 19:57:16,464 server.py:207 After application startup complete see http://127.0.0.1:8000/docs for API.Step 4: Interact with the model
In a separate terminal, chat with the Granite LLM as follows:
[instruct@instructlab ~]$ cd ~/instructlab
source venv/bin/activate
(venv) [instruct@instructlab instructlab]$ ilab chat -m models/granite-7b-lab-Q4_K_M.gguf
╭──────────────────────── system ─────────────────────────╮
│ Welcome to InstructLab Chat w/ MODELS/GRANITE-7B-LAB-Q4_K_M.GGUF │
│ (type /h for help) │
╰──────────────────────────────────────────────────────╯
>>> What is openshift in 20 words or less?
╭────────────────── models/granite-7b-lab-Q4_K_M.gguf────────────────╮
│ Openshift: A container application platform for accelerating development, deployment, and │ │ scaling of applications using Kubernetes. │
╰────────────────────────────────────────── elapsed 0.403 seconds ─╯Great! You can now download an LLM and chat with it. In the next lesson, we’ll test the accuracy of the LLM and explore how you can improve it.
