Page
Achieve cross-cloud identity on OpenShift with SPIRE and Tornjak

What does workload identity really mean? Most cloud platforms today come with a trusted identity provider that is integrated with the platform or the cloud infrastructure. This provider consists of a certificate authority, or root of trust, to provision identities for the application workloads running on top of the platform. This means that when an application container running within these environments wants to access a service, it takes that identity which comes in the form of an x509 certificate or JWT (JSON Web Token), and presents it to a Policy Enforcement Point which verifies this identity with the identity service. Then, based on policies, access is either granted or rejected.
This process works fine in a single cloud provider environment, but when there are two or more providers in use, there is no common trust domain to verify the identity, as there will likely be different identity schemas defined by each of the cloud providers. This challenge is depicted in Figure 1.

This lesson explains how you can mitigate these challenges using SPIRE and Tornjak on Red Hat OpenShift.
In order to get full benefit from taking this lesson, you need to:
- Understand the definitions of workload identity and policy enforcement point.
- Have familiarity with SPIRE concepts and Tornjak.
In this lesson, you will:
- Learn about cross-cloud workload identity and its challenges.
- Understand how to achieve cross-cloud workload identity with SPIRE and Torjnak on OpenShift.
Achieving cross-cloud workload identity with SPIRE and Torjnak on OpenShift
Figure 1 is dramatically changed with the addition of SPIFFE, SPIRE, and Tornjak on OpenShift, shown in Figure 2.
SPIFFE, the Secure Production Identity Framework for Everyone, is a Cloud Native Computing Foundation (CNCF) graduated project that defines an identity format and specifies how workloads can securely obtain identities in heterogeneous and dynamic cloud environments.
SPIRE, also a CNCF graduated project, provides a production-ready implementation of the SPIFFE standards and enables organization-wide management of SPIFFE identities and identity attestation. It issues and rotates identity tokens, and provides a single point of federation using an OpenID Connect (OIDC) discovery service. Refer to the SPIRE documentation for a detailed overview of architecture and concepts.
Lastly, Tornjak, a control plane and user interface for SPIRE, defines and presents organization-wide universal workload identity schemes. The Tornjak project was donated to CNCF by IBM.
As Figure 2 depicts, with SPIFFE and SPIRE deployed, a common schema is now available that is not dependent on any specific cloud and uses workload identity instead of hardcoding static keys.

A practical use case with workload identities
Now that you have a baseline understanding of SPIFFE, SPIRE, and Tornjak, let’s look at a simple use case of workload identity.
Figure 3 illustrates how a workload in a Red Hat OpenShift cluster securely accesses a remote S3 bucket in the AWS cloud. Unlike traditional methods involving hardcoded API keys or passwords, this method leverages AWS policies and roles and utilizes the workload identity for managing access. SPIRE facilitates this identity management capability, ensuring a more secure and scalable approach to access control.
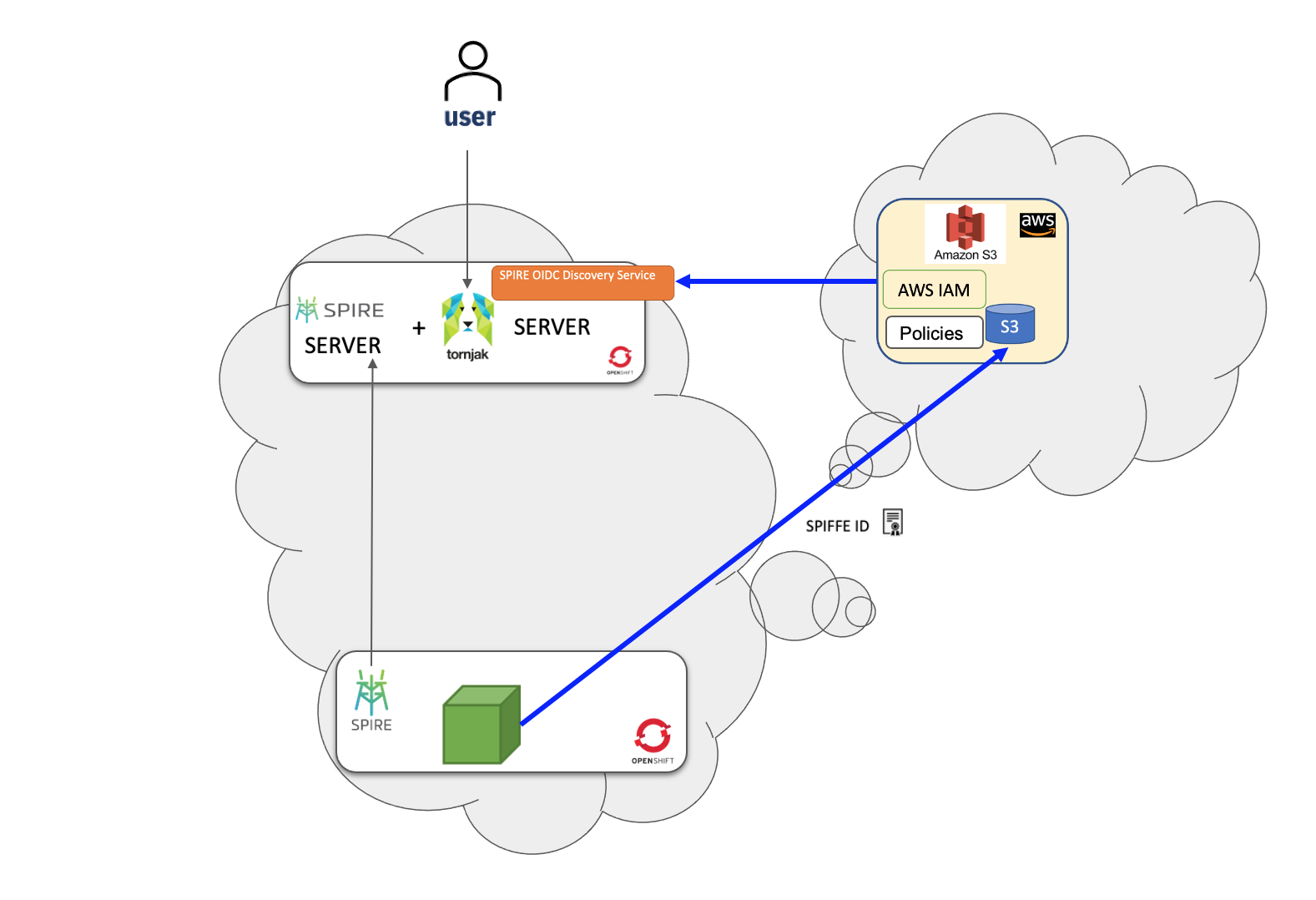
The following lessons are a step-by-step set of instructions on how to achieve the desired workload identity outcomes with SPIRE and Torjnak on OpenShift.
Configuration steps
- Set up SPIRE: The first phase involves configuring SPIRE to manage workload identities effectively. This includes the deployment of a centralized SPIRE server and SPIRE agents on every working node hosting the desired workloads.
- OIDC integration: Establishing a secure connection between AWS Identity and Access Management (IAM) and SPIRE by configuring IAM to use an OpenID Identity Provider (OIDC). This integration ensures a seamless identity verification process.
- AWS IAM configuration: Defining AWS IAM policies and roles that reference the SPIRE OIDC service. This step is pivotal in specifying the characteristics of workloads eligible to access the data stored in the designated S3 bucket.
Conclusion
In this lesson, you learned about cross-cloud workload identity, its challenges, and how SPIRE and Tornjak can be used to mitigate the challenges.
Next, we’ll see how to configure and install SPIRE on Red Hat OpenShift.